cambrian
1.0.0
有趣的事實:動物在寒武紀就出現了視覺!這就是我們計畫名稱寒武紀的靈感來源。
eval/子資料夾。dataengine/子資料夾。目前,我們支援使用 TorchXLA 對 TPU 進行訓練
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install -e " .[tpu] " pip install torch~=2.2.0 torch_xla[tpu]~=2.2.0 -f https://storage.googleapis.com/libtpu-releases/index.html
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install " .[gpu] " 這是我們的寒武紀檢查點以及如何使用權重的說明。我們的模型在 8B、13B 和 34B 參數層級的各個維度上都表現出色。與 GPT-4V、Gemini-Pro 和 Grok-1.4V 等閉源專有模型相比,它們在多個基準測試中表現出具有競爭力的性能。
| 模型 | # 可見。托克。 | MMB | SQA-I | 數學維斯塔M | 圖表品質保證 | 綜合MVP |
|---|---|---|---|---|---|---|
| GPT-4V | 恩克 | 75.8 | - | 49.9 | 78.5 | 50.0 |
| Gemini-1.0 專業版 | 恩克 | 73.6 | - | 45.2 | - | - |
| Gemini-1.5 Pro | 恩克 | - | - | 52.1 | 81.3 | - |
| 格羅克-1.5 | 恩克 | - | - | 52.8 | 76.1 | - |
| MM-1-8B | 144 | 72.3 | 72.6 | 35.9 | - | - |
| MM-1-30B | 144 | 75.1 | 81.0 | 39.4 | - | - |
| 基礎法學碩士:Phi-3-3.8B | ||||||
| 寒武紀1-8B | 第576章 | 74.6 | 79.2 | 48.4 | 66.8 | 40.0 |
| 基礎法學碩士:LLaMA3-8B-指導 | ||||||
| 迷你雙子座-HD-8B | 2880 | 72.7 | 75.1 | 37.0 | 59.1 | 18.7 |
| LLaVA-NeXT-8B | 2880 | 72.1 | 72.8 | 36.3 | 69.5 | 38.7 |
| 寒武紀1-8B | 第576章 | 75.9 | 80.4 | 49.0 | 73.3 | 51.3 |
| 基礎法學碩士:Vicuna1.5-13B | ||||||
| 迷你雙子座-HD-13B | 2880 | 68.6 | 71.9 | 37.0 | 56.6 | 19.3 |
| LLaVA-NeXT-13B | 2880 | 70.0 | 73.5 | 35.1 | 62.2 | 36.0 |
| 寒武紀1-13B | 第576章 | 75.7 | 79.3 | 48.0 | 73.8 | 41.3 |
| 基礎法學碩士:Hermes2-Yi-34B | ||||||
| 迷你雙子座-HD-34B | 2880 | 80.6 | 77.7 | 43.4 | 67.6 | 37.3 |
| LLaVA-NeXT-34B | 2880 | 79.3 | 81.8 | 46.5 | 68.7 | 47.3 |
| 寒武紀-1-34B | 第576章 | 81.4 | 85.6 | 53.2 | 75.6 | 52.7 |
如需完整表格,請參閱我們的 Cambrian-1 論文。
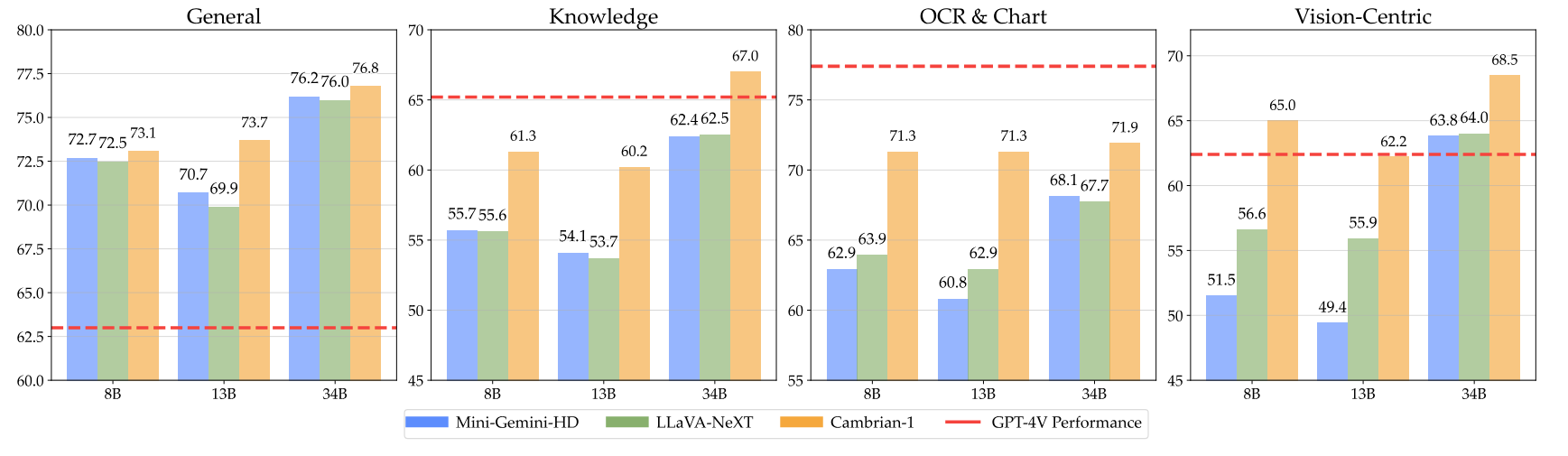
我們的模型在使用較少的固定數量的視覺標記的同時提供了極具競爭力的性能。
要使用模型權重,請從 Hugging Face 下載它們:
我們在inference.py中提供了範例模型載入和產生腳本。

在這項工作中,我們收集了一個非常大的指令調優資料池 Cambrian-10M,供我們和未來研究訓練 MLLM 的資料。在我們的初步研究中,我們將資料過濾為一組高品質的 7M 精選資料點,我們稱之為 Cambrian-7M。這兩個資料集都可以在以下 Hugging Face 資料集中找到:Cambrian-10M。
我們從各種來源收集了各種視覺指令調整數據,包括 VQA、視覺對話和具體視覺互動。為了確保高品質、可靠、大規模的知識數據,我們設計了網路數據引擎。
此外,我們觀察到 VQA 資料往往會產生非常短的輸出,導致訓練資料分佈變化。為了解決這個問題,我們利用 GPT-4v 和 GPT-4o 來創建擴展回應和更具創意的數據。
為了解決科學相關數據的不足,我們設計了一個互聯網數據引擎來收集可靠的科學相關VQA數據。此引擎可用於收集任何主題的數據。使用該引擎,我們額外收集了 161k 個與科學相關的視覺指令調整數據點,使該領域的總數據增加了 400%!如果你想使用這部分數據,請使用這個jsonl。
我們使用 GPT-4v 創建了額外的 77k 數據點。該數據要么使用 GPT-4v 將原始的僅答案 VQA 重寫為具有更詳細響應的更長答案,要么根據給定圖像生成視覺指令調整數據。如果你想使用這部分數據,請使用這個jsonl。
我們使用 GPT-4o 創建了額外的 60k 創意數據點。這些數據鼓勵模型產生很長的回應,並且通常包含高度創造性的問題,例如寫一首詩、創作一首歌曲等等。如果你想使用這部分數據,請使用這個jsonl。
我們透過以下方式對資料管理進行了初步研究:
根據經驗,我們發現設置
| 類別 | 數據比率 |
|---|---|
| 語言 | 21.00% |
| 一般的 | 34.52% |
| 光學字元辨識 | 27.22% |
| 計數 | 8.71% |
| 數學 | 7.20% |
| 程式碼 | 0.87% |
| 科學 | 0.88% |
與先前的 LLaVA-665K 模型相比,擴展和改進的資料管理顯著提高了模型效能,如下表所示:
| 模型 | 平均的 | 常識 | 光學字元辨識 | 圖表 | 以視覺為中心 |
|---|---|---|---|---|---|
| LLaVA-665K | 40.4 | 64.7 | 45.2 | 20.8 | 31.0 |
| 寒武紀10M | 53.8 | 68.7 | 51.6 | 47.1 | 47.6 |
| 寒武紀7M | 54.8 | 69.6 | 52.6 | 47.3 | 49.5 |
雖然使用 Cambrian-7M 進行訓練可提供具有競爭力的基準結果,但我們觀察到該模型往往會輸出較短的響應,並且就像問答機一樣。這種行為,我們稱之為「應答機」現象,可能會限制模型在更複雜的交互作用中的有用性。
我們發現添加了一個系統提示,例如「使用單字或短語回答問題」。可以幫助緩解這個問題。這種方法鼓勵模型僅在上下文適當時才提供如此簡潔的答案。欲了解更多詳細信息,請參閱我們的論文。
我們還策劃了一個帶有系統提示的資料集Cambrian-7M,其中包括增強模型創造力和聊天能力的系統提示。
以下是Cambrian-1的最新訓練配置。
在 Cambrian-1 論文中,我們進行了廣泛的研究來證明兩階段訓練的必要性。 Cambrian-1 訓練分為兩個階段:
Cambrian-1 在 TPU-V4-512 上進行訓練,但也可以在從 TPU-V4-64 開始的 TPU 上進行訓練。 GPU訓練程式碼即將發布。對於較少 GPU 上的 GPU 訓練,請減少per_device_train_batch_size並相應地增加gradient_accumulation_steps ,確保全域批次大小保持不變: per_device_train_batch_size gradient_accumulation_steps x num_gpus 。
下面提供了預訓練和微調中使用的兩個超參數。
| 基礎法學碩士 | 全域批量大小 | 學習率 | SVA學習率 | 紀元 | 最大長度 |
|---|---|---|---|---|---|
| 拉瑪-3 8B | 第512章 | 1e-3 | 1e-4 | 1 | 2048 |
| 駱駝毛-1.5 13B | 第512章 | 1e-3 | 1e-4 | 1 | 2048 |
| 愛馬仕Yi-34B | 1024 | 1e-3 | 1e-4 | 1 | 2048 |
| 基礎法學碩士 | 全域批量大小 | 學習率 | 紀元 | 最大長度 |
|---|---|---|---|---|
| 拉瑪-3 8B | 第512章 | 4e-5 | 1 | 2048 |
| 駱駝毛-1.5 13B | 第512章 | 4e-5 | 1 | 2048 |
| 愛馬仕Yi-34B | 1024 | 2e-5 | 1 | 2048 |
對於指令微調,我們進行了實驗來確定模型訓練的最佳學習率。根據我們的發現,我們建議使用以下公式根據您的設備的可用性調整您的學習率:
optimal lr = base_lr * sqrt(bs / base_bs)
要獲得基礎 LLM 並訓練 8B、13B 和 34B 模型:
我們使用 LLaVA、ShareGPT4V、Mini-Gemini 和 ALLaVA 對齊資料的組合來預先訓練我們的視覺連接器 (SVA)。在 Cambrian-1 中,我們進行了廣泛的研究來證明使用額外對齊資料的必要性和好處。
首先,請造訪我們的擁抱臉部對齊資料頁面以了解更多詳細資訊。您可以從以下鏈接下載對齊資料:
我們在以下位置提供範例培訓腳本:
如果您希望使用其他資料來源或自訂資料進行訓練,我們支援常用的 LLaVA 資料格式。為了處理非常大的文件,我們使用 JSONL 格式而不是 JSON 格式來延遲資料加載,以優化記憶體使用。
與訓練 SVA 類似,請造訪我們的 Cambrian-10M 資料以取得有關指令調校資料的更多詳細資訊。
我們在以下位置提供範例培訓腳本:
--mm_projector_type :要使用我們的 SVA 模組,請將此值設為sva 。若要使用 LLaVA 樣式 2 層 MLP 投影儀,請將此值設為mlp2x_gelu 。--vision_tower_aux_list :要使用的視覺模型清單(例如'["siglip/CLIP-ViT-SO400M-14-384", "openai/clip-vit-large-patch14-336", "facebook/dinov2-giant-res378", "clip-convnext-XXL-multi-stage"]' )。--vision_tower_aux_token_len_list :每個願景塔的願景令牌數量清單;每個數字應該是平方數(例如'[576, 576, 576, 9216]' )。每個視覺塔的特徵圖將被插值以滿足這個要求。--image_token_len :將提供給LLM的視覺令牌的最終數量;該數字應該是平方數(例如576 )。請注意,如果mm_projector_type為 mlp,則vision_tower_aux_token_len_list中的每個數字必須與image_token_len相同。以下參數僅對 SVA 投影機有意義--num_query_group :SVA 模組的G值。--query_num_list :SVA 中每組查詢的查詢編號清單(例如'[576]' )。列表的長度應等於num_query_group 。--connector_depth :SVA 模組的D值。--vision_hidden_size :SVA 模組的隱藏大小。--connector_only :如果為true,SVA模組只會出現在LLM之前,否則會在LLM內部多次插入。以下三個參數僅在設定為False時才有意義。--num_of_vision_sampler_layers :LLM 中插入的 SVA 模組總數。--start_of_vision_sampler_layers :LLM 層索引,之後開始插入 SVA。--stride_of_vision_sampler_layers :LLM 內 SVA 模組插入的步幅。 我們已在eval/子資料夾中發布了評估代碼。請參閱那裡的自述文件以了解更多詳細資訊。
以下說明將引導您使用 Cambrian 啟動本機 Gradio 演示。我們提供了一個簡單的 Web 介面供您與模型互動。您也可以使用 CLI 進行推理。這個設定很大程度上受到 LLaVA 的啟發。
請依照以下步驟啟動本機 Gradio 演示。本地服務代碼圖如下1 。
%%{init: {"主題": "基礎"}}%%
流程圖BT
%% 聲明節點
樣式 gws 填滿:#f9f,描邊:#333,描邊寬度:2px
樣式 c 填滿:#bbf,描邊:#333,描邊寬度:2px
樣式 mw8b 填滿:#aff,描邊:#333,描邊寬度:2px
樣式 mw13b 填滿:#aff,描邊:#333,描邊寬度:2px
%% 樣式 sglw13b 填滿:#ffa,描邊:#333,描邊寬度:2px
%% 樣式 lsglw13b 填滿:#ffa,描邊:#333,描邊寬度:2px
gws["Gradio(UI 伺服器)"]
c["控制器(API 伺服器):<br/>連接埠:10000"]
mw8b["勞模:<br/><b>Cambrian-1-8B</b><br/>埠:40000"]
mw13b["勞模:<br/><b>Cambrian-1-13B</b><br/>埠:40001"]
%% sglw13b["SGLang 後端:<br/><b>Cambrian-1-34B</b><br/>http://localhost:30000"]
%% lsglw13b["SGLang 工作執行緒:<br/><b>Cambrian-1-34B<b><br/>連接埠:40002"]
子圖“演示架構”
方向BT
c <--> GWS
mw8b <--> c
mw13b <--> c
%% lsglw13b <--> c
%% sglw13b <--> lsglw13b
結尾
python -m cambrian.serve.controller --host 0.0.0.0 --port 10000python -m cambrian.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload您剛剛啟動了 Gradio Web 介面。現在,您可以開啟 Web 介面,並將 URL 列印在螢幕上。您可能會注意到模型清單中沒有模型。別擔心,我們還沒有推出任何勞模。當您啟動模型工作人員時,它將自動更新。
即將推出。
這是在 GPU 上執行推理的實際工作程序。每個工作人員負責--model-path中指定的單一模型。
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8b等到進程完成載入模型,您會看到「Uvicorn running on ...」。現在,刷新您的 Gradio Web UI,您將在模型清單中看到剛剛啟動的模型。
您可以根據需要啟動任意數量的工作程序,並在相同 Gradio 介面中比較不同模型檢查點。請保持--controller相同,並將--port和--worker修改為每個worker的不同連接埠號碼。
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port < different from 40000, say 40001> --worker http://localhost: < change accordingly, i.e. 40001> --model-path < ckpt 2>如果您使用的是具有 M1 或 M2 晶片的 Apple 設備,則可以使用--device標誌指定 mps 設備: --device mps 。
如果您的 GPU 的 VRAM 小於 24GB(例如 RTX 3090、RTX 4090 等),您可以嘗試使用多個 GPU 來運行它。如果您有多個 GPU,我們最新的程式碼庫將自動嘗試使用多個 GPU。您可以透過CUDA_VISIBLE_DEVICES指定要使用的 GPU。下面是使用前兩個 GPU 運行的範例。
CUDA_VISIBLE_DEVICES=0,1 python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8b待辦事項
如果您發現 Cambrian 對您的研究和應用有用,請使用此 BibTeX 進行引用:
@misc { tong2024cambrian1 ,
title = { Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs } ,
author = { Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie } ,
year = { 2024 } ,
eprint = { 2406.16860 } ,
}
使用和許可聲明:該專案使用某些資料集和檢查點,這些資料集和檢查點受各自原始許可的約束。使用者必須遵守這些原始許可證的所有條款和條件,包括但不限於資料集的 OpenAI 使用條款以及使用資料集訓練的檢查點的基本語言模型的特定許可證(例如 Llama-3 的 Llama 社群許可證,和駱駝毛-1.5)。除了原始許可證中規定的限制外,該項目沒有施加任何額外的限制。此外,提醒使用者確保他們對資料集和檢查點的使用符合所有適用的法律和法規。
複製自 LLaVA 的圖表。 ↩


