ThinkRAG
1.0.0
English | 簡體中文
ThinkRAG 大模型檢索增強生成系統,可輕鬆部署在筆記型電腦上,實現本地知識庫智慧問答。
該系統基於LlamaIndex 和Streamlit 構建,針對國內用戶在模型選擇、文字處理等許多領域進行了最佳化。
ThinkRAG 是為專業人士、研究人員、學生等知識工作者開發的大模型應用系統,可在筆記型電腦上直接使用,知識庫資料都保存在電腦本地。
ThinkRAG具備以下特質:
特別地,ThinkRAG 也為國內用戶做了大量客製化和優化:
ThinkRAG 可使用LlamaIndex 資料框架支援的所有模型。關於模型列表信息,請參考相關文件。
ThinkRAG致力於打造一個直接能用、有用、易用的應用系統。
因此,在各種模型、組件與技術上,我們做了精心的選擇與取捨。
首先,使用大模型,ThinkRAG支援OpenAI API 以及所有相容的LLM API,包括國內主流大模型廠商,例如:
如果要在地化部署大模型,ThinkRAG 選用了簡單易用的Ollama。我們可以從透過Ollama 將大模型下載到本地運行。
目前Ollama 支援幾乎所有主流大型模式在地化部署,包括Llama、Gemma、GLM 、Mistral、Phi、Llava等。具體可至以下Ollama 官網了解。
系統也使用了嵌入模型和重排模型,可支援來自Hugging Face 的大多數模型。目前,ThinkRAG主要選用了BAAI的BGE系列模型。國內用戶可存取鏡像網址了解及下載。
從Github下載程式碼後,用pip安裝所需元件。
pip3 install -r requirements.txt若要離線運行系統,請先從官網下載Ollama。然後,使用Ollama 指令下載如GLM、 Gemma 和QWen 等大模型。
同步,從Hugging Face將嵌入模型(BAAI/bge-large-zh-v1.5)和重排模型(BAAI/bge-reranker-base)下載到localmodels 目錄中。
具體步驟,可參考docs 目錄下的文件:HowToDownloadModels.md
為了獲得更好的效能,建議使用千億級參數的商用大模型LLM API。
首先,從LLM 服務商取得API 金鑰,配置下列環境變數。
ZHIPU_API_KEY = " "
MOONSHOT_API_KEY = " "
DEEPSEEK_API_KEY = " "
OPENAI_API_KEY = " "你可以跳過這一步,在系統運行後,再透過應用程式介面配置API 金鑰。
如果選擇使用其中一個或多個LLM API,請在config.py 設定檔中刪除不再使用的服務提供者。
當然,你也可以在設定檔中,加入其他相容OpenAI API 的服務商。
ThinkRAG 預設以開發模式運作。在此模式下,系統使用本機檔案存儲,你不需要安裝任何資料庫。
若要切換到生產模式,你可以按照以下方式配置環境變數。
THINKRAG_ENV = production在生產模式下,系統使用向量資料庫Chroma 和鍵值資料庫Redis。
如果你沒有安裝Redis,建議透過Docker 安裝,或使用現有的Redis 實例。請在config.py 檔案裡,設定Redis 實例的參數資訊。
現在,你已經準備好要運行ThinkRAG。
請在包含app.py 檔案的目錄中執行以下命令。
streamlit run app.py系統將運行,並在瀏覽器上自動開啟以下網址,展示應用程式介面。
http://localhost:8501/
第一次運行可能會需要等待片刻。如果沒有事先下載Hugging Face 上的嵌入模型,系統也會自動下載模型,將需要等待更長時間。
ThinkRAG 支援在使用者介面,對大模型進行配置與選擇,包括:大模型LLM API 的Base URL 和API 金鑰,並可選擇使用的特定模型,例如:智譜的glm-4。
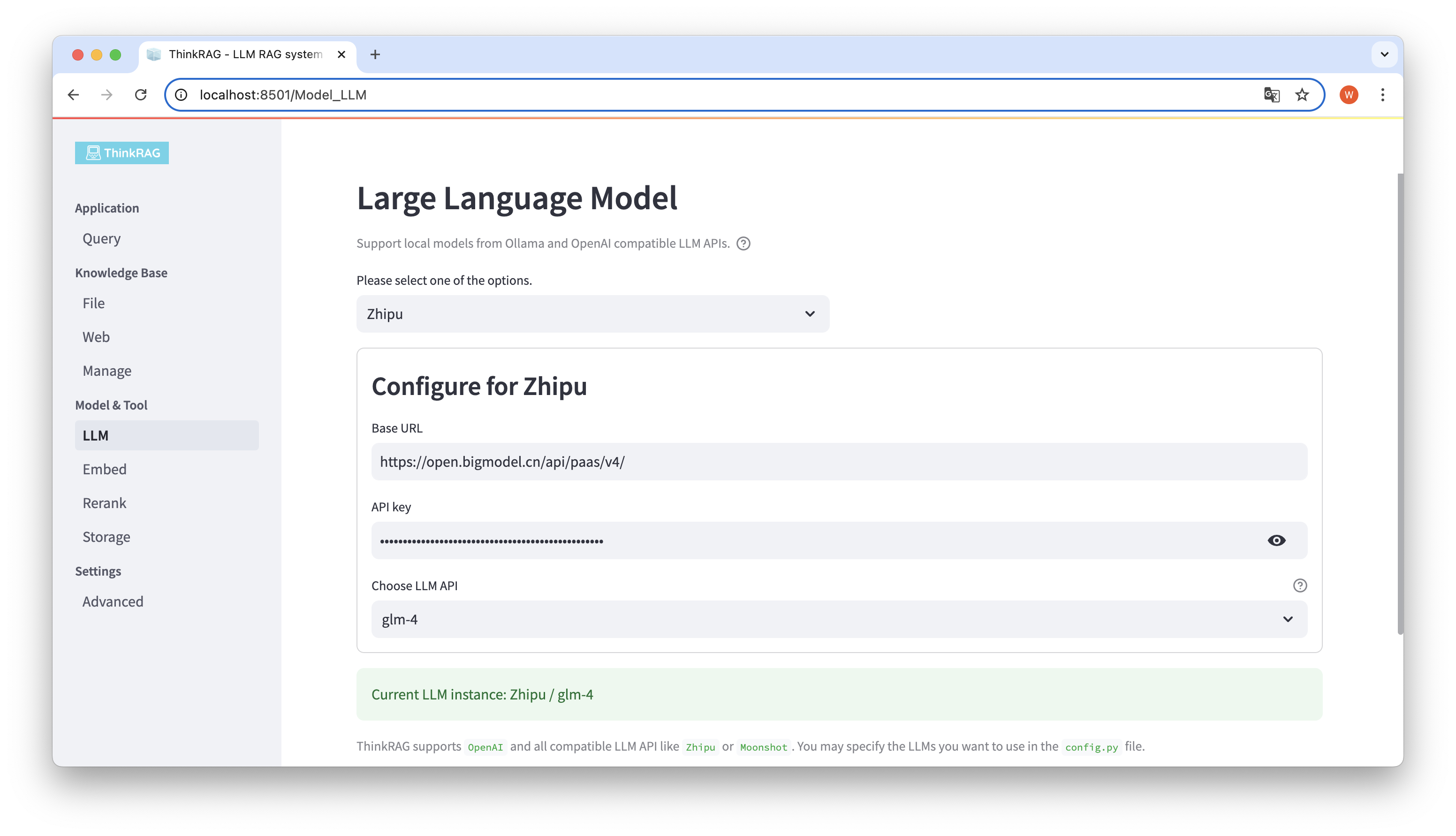
系統將自動偵測API 和金鑰是否可用,若可用則在底部以綠色文字,顯示目前選取的大模型實例。
同樣,系統可以自動取得Ollama 下載的模型,使用者可以在使用者介面上選擇所需的模型。
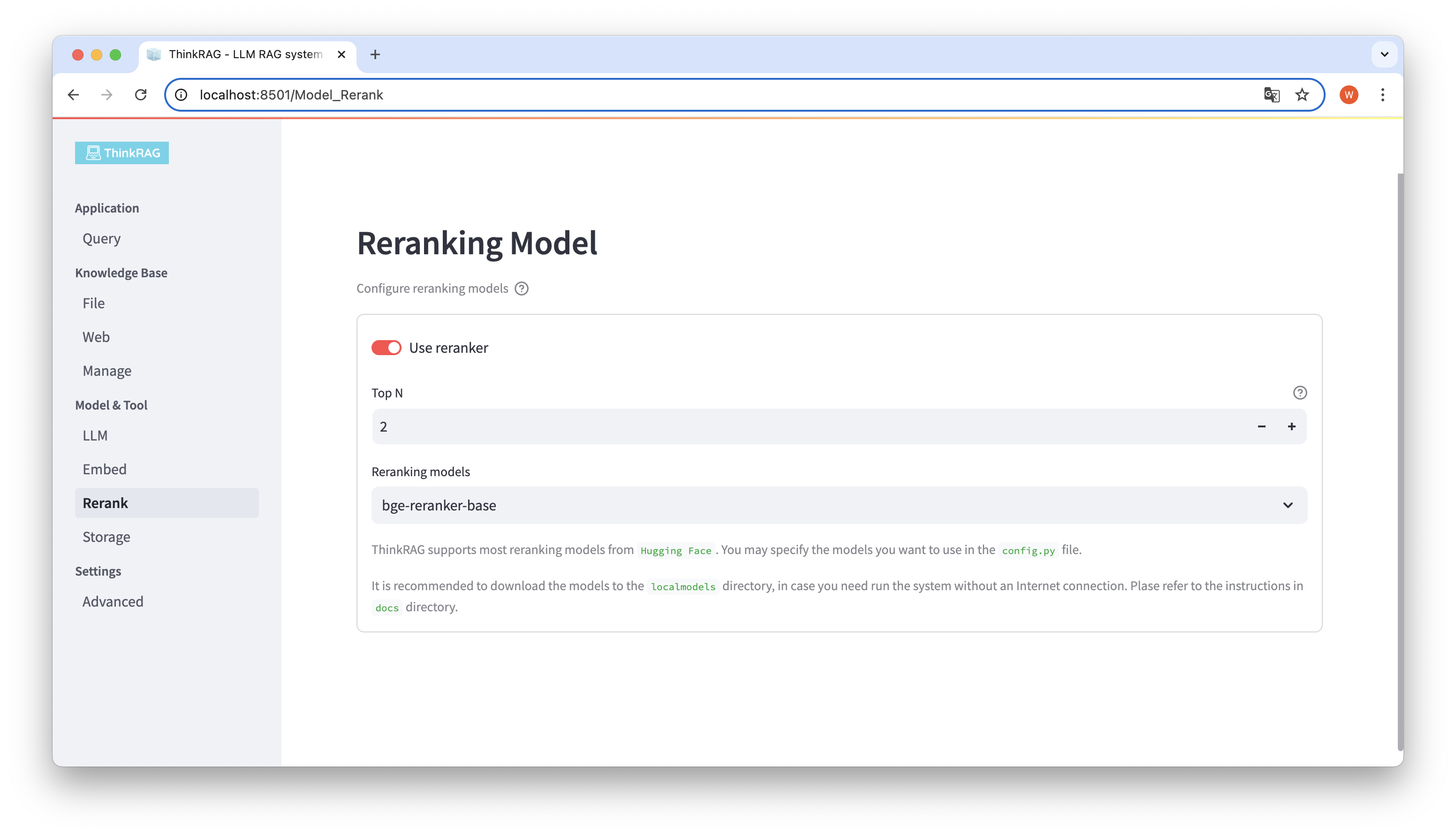
若你已經將嵌入模型和重排模型下載到本地localmodels 目錄下。在使用者介面上,可以切換選擇使用的模型,並設定重排模型的參數,例如Top N。
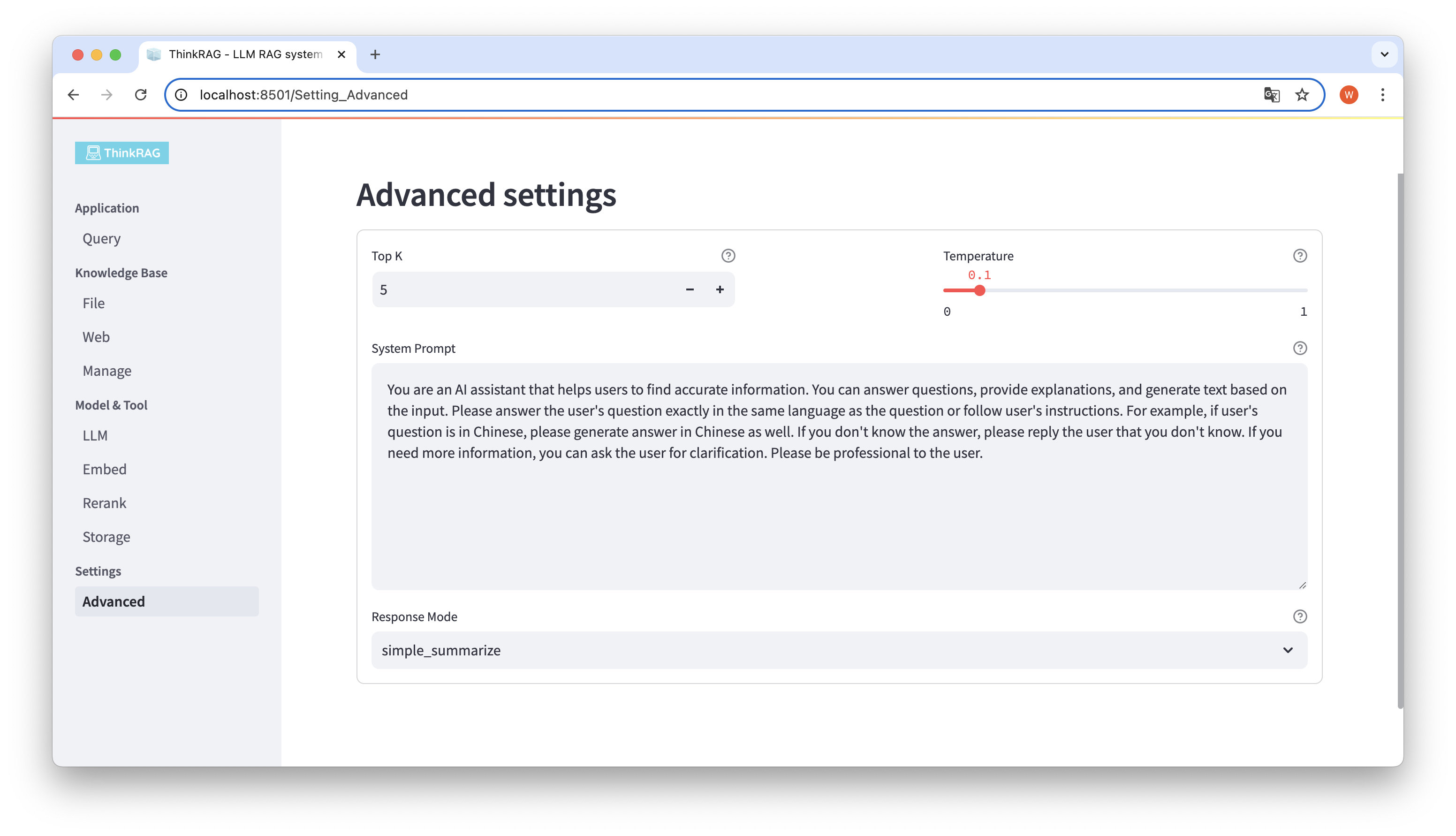
在左側導覽欄,點擊進階設定(Settings-Advanced),你也可以對下列參數進行設定:
透過使用不同參數,我們可以比較大模型輸出結果,找到最有效的參數組合。
ThinkRAG 支援上傳PDF、DOCX、PPTX 等各類文件,也支援上傳網頁URL。
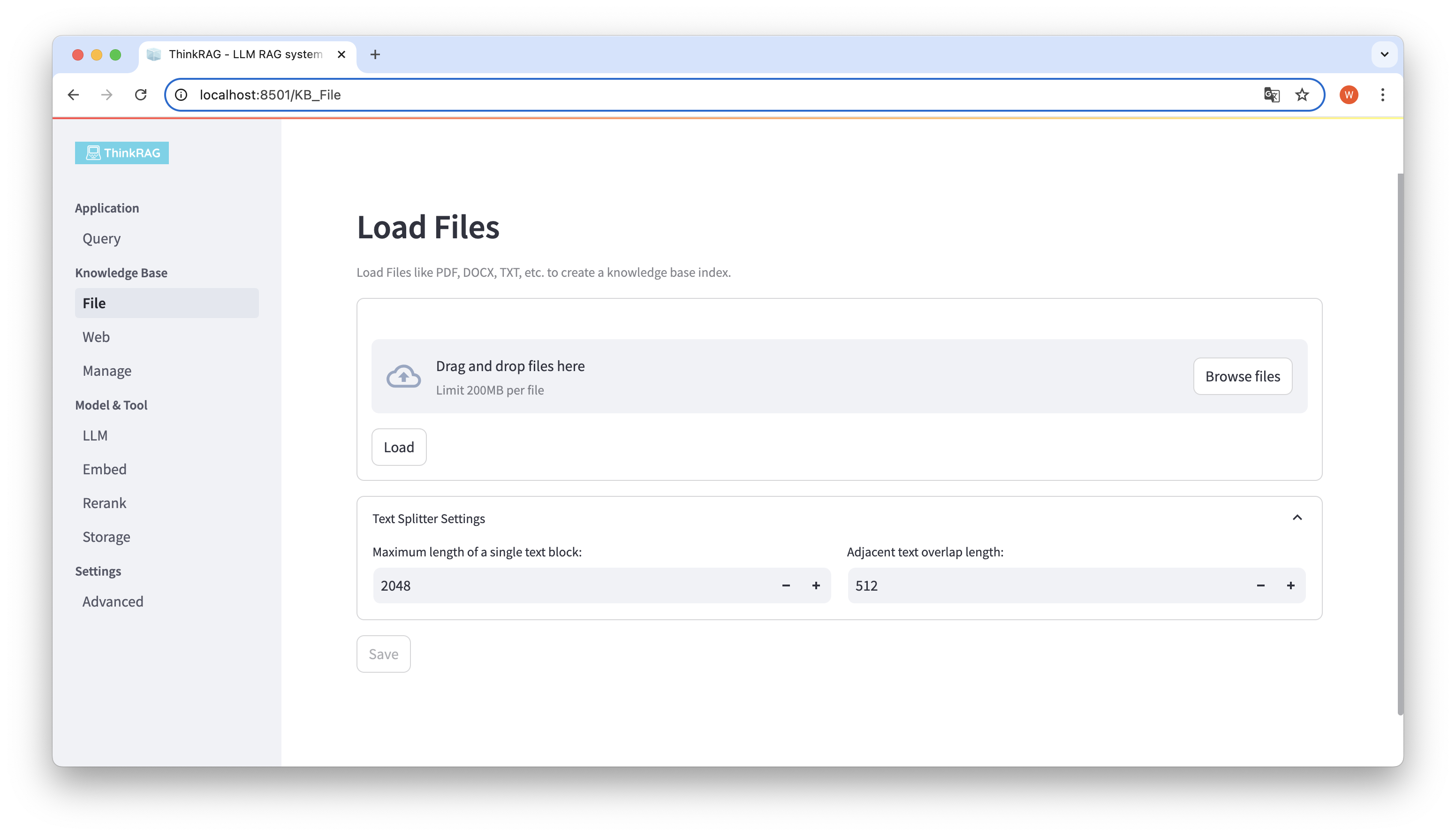
點選Browse files 按鈕,選擇電腦上的文件,然後點選Load 按鈕加載,此時會列出所有已載入的檔案。
然後,點擊Save 按鈕,系統就會對文件進行處理,包括文字分割和嵌入,並儲存到知識庫中。
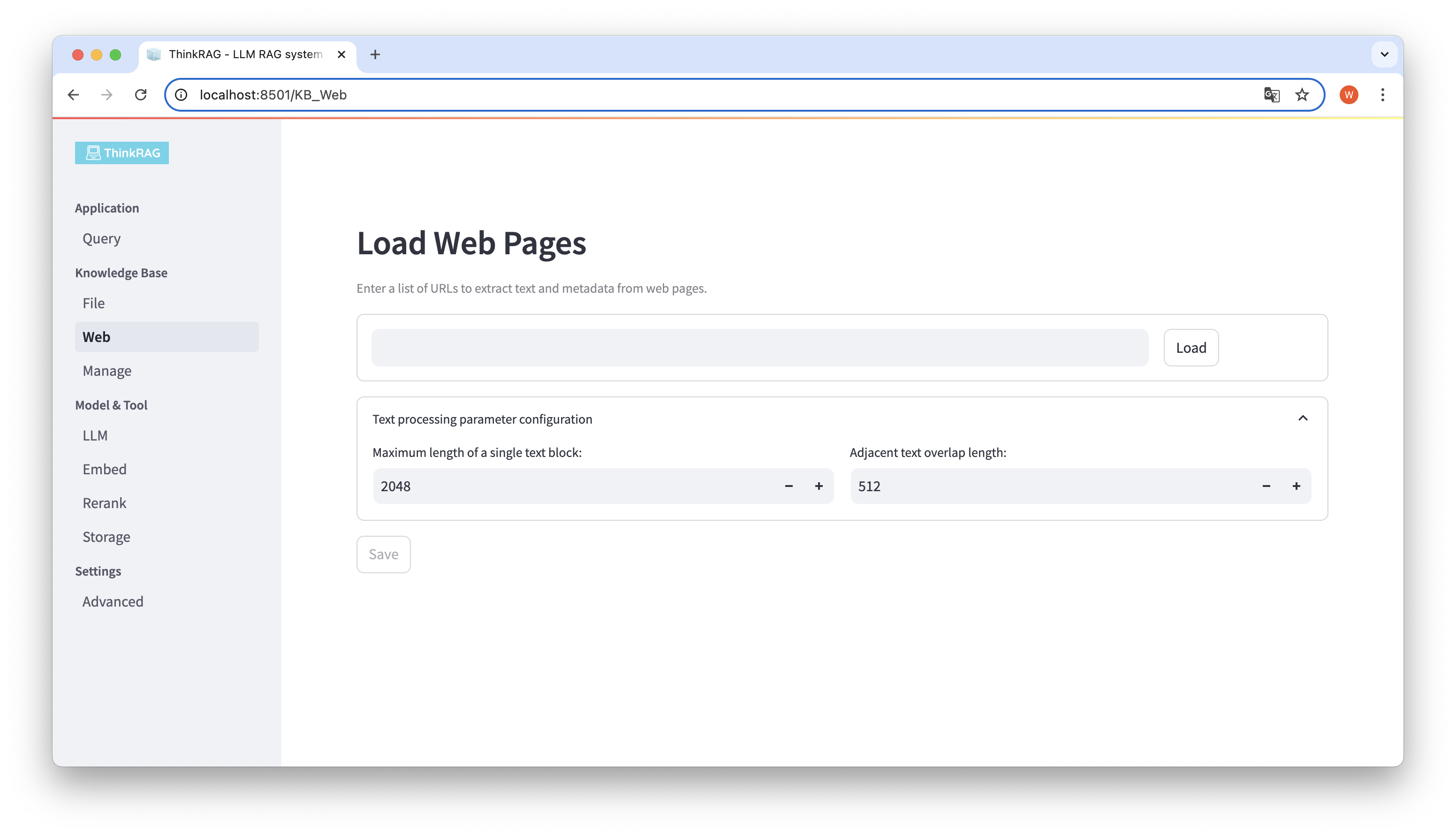
同樣,你可以輸入或貼上網頁URL,取得網頁訊息,處理後儲存到知識庫。
系統支援對知識庫進行管理。
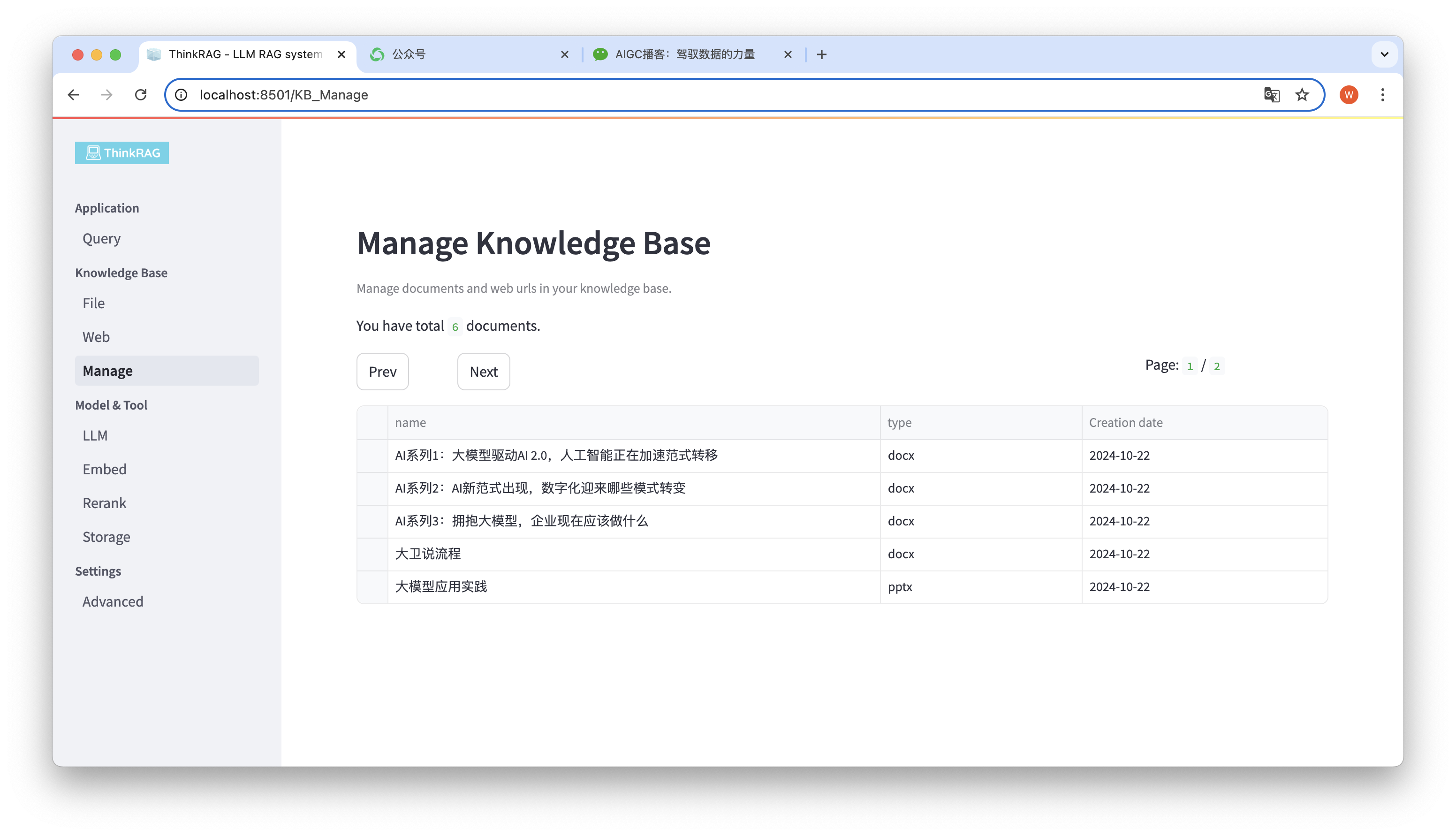
如上圖所示,ThinkRAG 可以分頁列出,知識庫中所有的文件。
選擇要刪除的文檔,將出現Delete selected documents 按鈕,點擊該按鈕可以將文檔從知識庫中刪除。
在左側導覽欄,點選Query,將會出現智慧問答頁面。
輸入問題後,系統會對知識庫進行檢索,並給予答案。在這個過程當中,系統將採用混合檢索和重排等技術,從知識庫中獲得準確的內容。
例如,我們已經在知識庫中上傳了一個Word 文件:「大衛說流程.docx」。
現在輸入問題:”流程有哪三個特徵?”
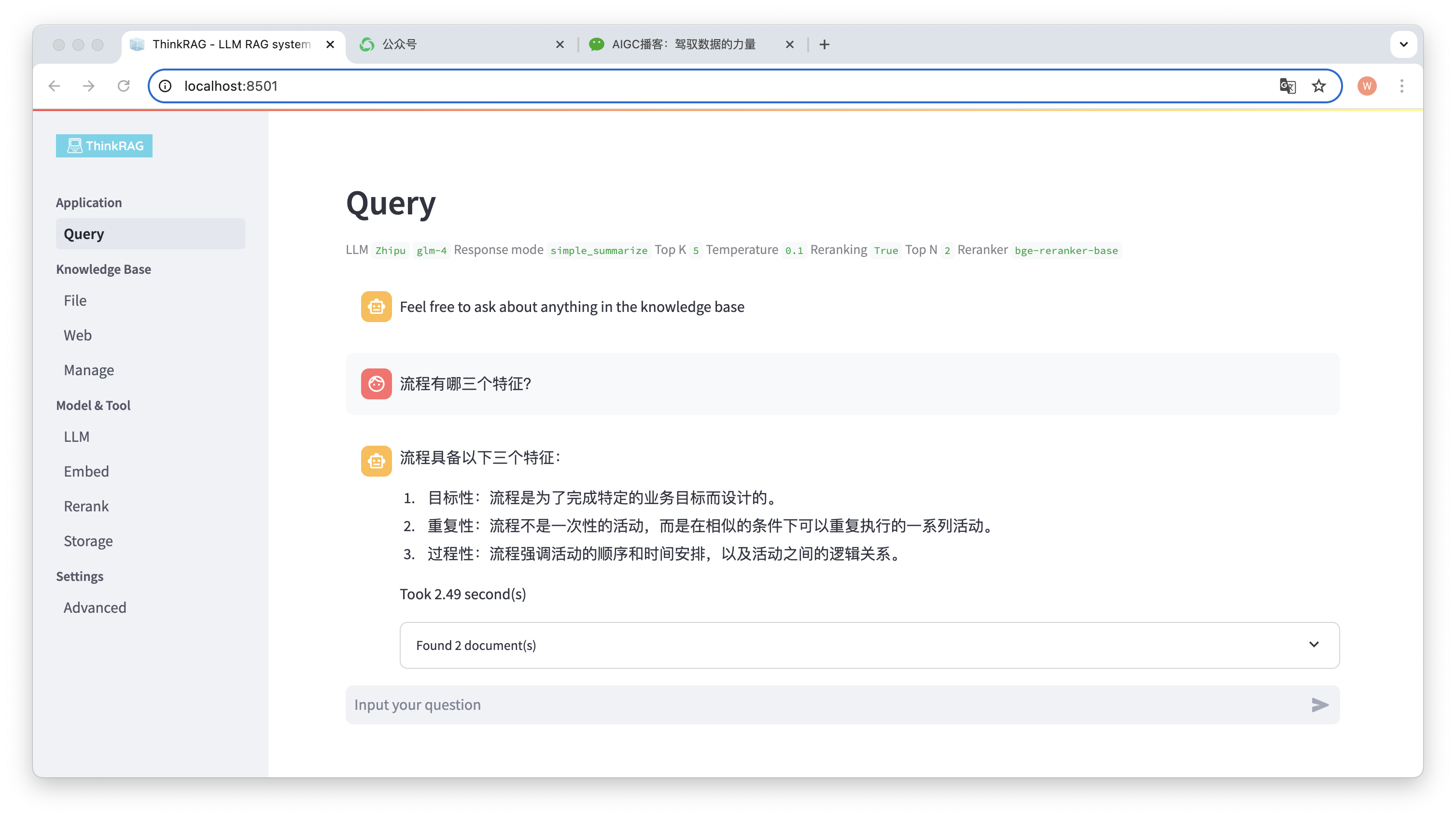
如圖所示,系統用時2.49秒,給了精確的答案:流程具備目標性、重複性與過程性。同時,系統也給出了從知識庫檢索到的2個相關文件。
可以看到,ThinkRAG 完整且有效地實現了,基於本地知識庫的大模型檢索增強生成的功能。
ThinkRAG 採用LlamaIndex 資料框架開發,前端使用Streamlit。系統的開發模式和生產模式,分別選用了不同的技術組件,如下表所示:
| 開發模式 | 生產模式 | |
|---|---|---|
| RAG框架 | LlamaIndex | LlamaIndex |
| 前端框架 | Streamlit | Streamlit |
| 嵌入模型 | BAAI/bge-small-zh-v1.5 | BAAI/bge-large-zh-v1.5 |
| 重排模型 | BAAI/bge-reranker-base | BAAI/bge-reranker-large |
| 文字分割器 | SentenceSplitter | SpacyTextSplitter |
| 對話存儲 | SimpleChatStore | Redis |
| 文件儲存 | SimpleDocumentStore | Redis |
| 索引存儲 | SimpleIndexStore | Redis |
| 向量存儲 | SimpleVectorStore | LanceDB |
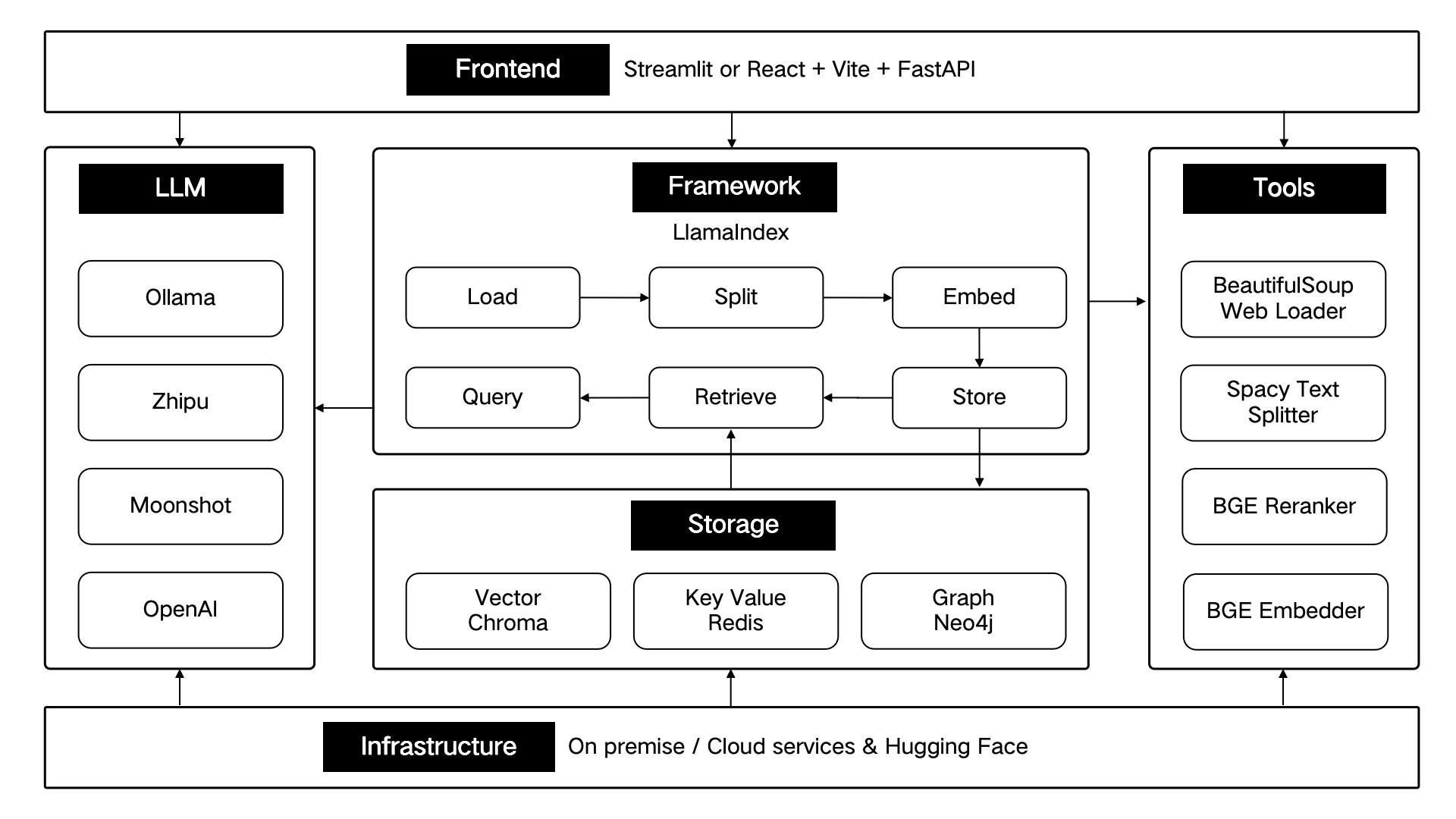
這些技術組件,依照前端、框架、大模型、工具、儲存、基礎設施,這六個部分進行架構設計。
如下圖所示:
ThinkRAG 將持續優化核心功能,持續提升檢索的效率與準確性,主要包括:
同時,我們也將進一步完善應用架構、提升使用者體驗,主要包括:
歡迎你加入ThinkRAG 開源項目,一起打造用戶喜愛的AI 產品!
ThinkRAG 使用MIT 協定.


