lance
v0.20.0

適用於 ML 的現代柱狀資料格式。使用 2 行程式碼從 Parquet 轉換,實現速度提高 100 倍的隨機存取、向量索引、資料版本控制等。
與 pandas、DuckDB、Polars 和 pyarrow 相容,並將有更多整合。
文件 • 部落格 • Discord • Twitter
Lance 是一種現代柱狀資料格式,針對 ML 工作流程和資料集進行了最佳化。蘭斯非常適合:
蘭斯的主要特點包括:
高效能隨機存取:比 Parquet 快 100 倍,且不犧牲掃描效能。
向量搜尋:以毫秒為單位尋找最近鄰居,並將 OLAP 查詢與向量搜尋結合。
零拷貝、自動版本控制:無需額外的基礎架構即可管理資料版本。
生態系統整合: Apache Arrow、Pandas、Polars、DuckDB 等即將推出。
提示
Lance 正在積極開發中,我們歡迎貢獻。請參閱我們的貢獻指南以獲取更多資訊。
安裝
pip install pylance要安裝預覽版:
pip install --pre --extra-index-url https://pypi.fury.io/lancedb/ pylance提示
預覽版本比完整版本發布得更頻繁,並包含最新功能和錯誤修復。它們接受與完整版本相同等級的測試。我們保證它們將保持發布並可供下載至少 6 個月。當您想要固定到特定版本時,最好選擇穩定版本。
轉換為蘭斯
import lance
import pandas as pd
import pyarrow as pa
import pyarrow . dataset
df = pd . DataFrame ({ "a" : [ 5 ], "b" : [ 10 ]})
uri = "/tmp/test.parquet"
tbl = pa . Table . from_pandas ( df )
pa . dataset . write_dataset ( tbl , uri , format = 'parquet' )
parquet = pa . dataset . dataset ( uri , format = 'parquet' )
lance . write_dataset ( parquet , "/tmp/test.lance" )讀取蘭斯數據
dataset = lance . dataset ( "/tmp/test.lance" )
assert isinstance ( dataset , pa . dataset . Dataset )貓熊
df = dataset . to_table (). to_pandas ()
df鴨資料庫
import duckdb
# If this segfaults, make sure you have duckdb v0.7+ installed
duckdb . query ( "SELECT * FROM dataset LIMIT 10" ). to_df ()向量搜尋
下載 sift1m 子集
wget ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz
tar -xzf sift.tar.gz將其轉換為蘭斯
import lance
from lance . vector import vec_to_table
import numpy as np
import struct
nvecs = 1000000
ndims = 128
with open ( "sift/sift_base.fvecs" , mode = "rb" ) as fobj :
buf = fobj . read ()
data = np . array ( struct . unpack ( "<128000000f" , buf [ 4 : 4 + 4 * nvecs * ndims ])). reshape (( nvecs , ndims ))
dd = dict ( zip ( range ( nvecs ), data ))
table = vec_to_table ( dd )
uri = "vec_data.lance"
sift1m = lance . write_dataset ( table , uri , max_rows_per_group = 8192 , max_rows_per_file = 1024 * 1024 )建立索引
sift1m . create_index ( "vector" ,
index_type = "IVF_PQ" ,
num_partitions = 256 , # IVF
num_sub_vectors = 16 ) # PQ搜尋資料集
# Get top 10 similar vectors
import duckdb
dataset = lance . dataset ( uri )
# Sample 100 query vectors. If this segfaults, make sure you have duckdb v0.7+ installed
sample = duckdb . query ( "SELECT vector FROM dataset USING SAMPLE 100" ). to_df ()
query_vectors = np . array ([ np . array ( x ) for x in sample . vector ])
# Get nearest neighbors for all of them
rs = [ dataset . to_table ( nearest = { "column" : "vector" , "k" : 10 , "q" : q })
for q in query_vectors ]| 目錄 | 描述 |
|---|---|
| 鏽 | 核心 Rust 實現 |
| Python | Python 綁定 (pyo3) |
| 文件 | 文件來源 |
在這裡我們將重點介紹蘭斯設計的幾個面向。有關更多詳細信息,請參閱完整的 Lance 設計文件。
向量索引:用於嵌入空間上相似性搜尋的向量索引。支援 CPU( x86_64和arm )和 GPU( Nvidia (cuda)和Apple Silicon (mps) )。
編碼:為了實現快速柱狀掃描和次線性點查詢,Lance 使用自訂編碼和佈局。
嵌套欄位:Lance 將每個子欄位儲存為單獨的列,以支援高效率的篩選器,例如「尋找偵測到的物件包括貓的影像」。
版本控制:清單可用於記錄快照。目前我們支援透過追加、覆蓋和建立索引自動建立新版本。
快速更新(路線圖):將透過預寫日誌支援更新。
豐富的二級索引(ROADMAP):
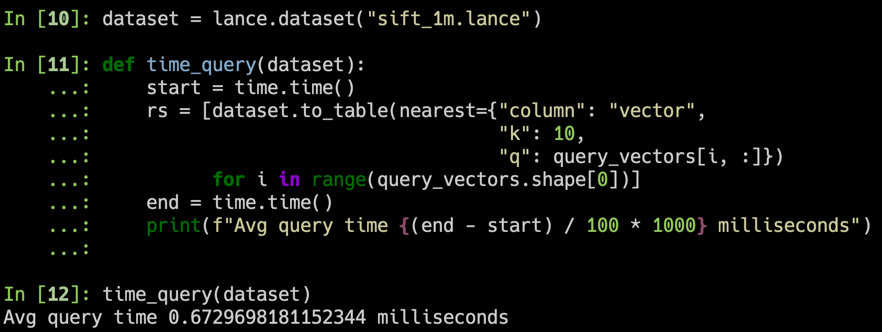
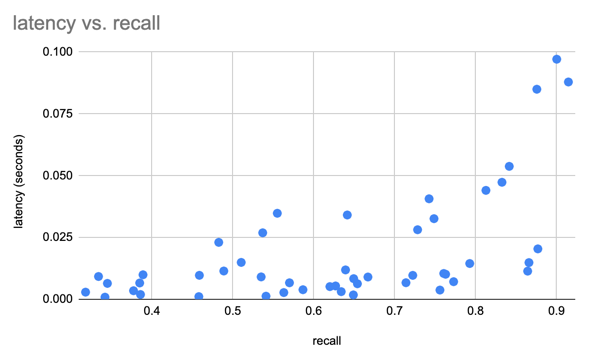
我們使用 SIFT 資料集對 1M 個 128D 向量的結果進行基準測試
我們使用 Oxford Pet 資料集建立 Lance 資料集,與 Parquet 和原始映像/XML 相比,對 Lance 進行一些初步效能測試。對於分析查詢,Lance 比讀取原始元資料好 50-100 倍。對於批量隨機訪問,Lance 比 parquet 和原始文件好 100 倍。

機器學習開發週期涉及以下步驟:
圖LR
A[收藏] --> B[探索];
B --> C[分析];
C --> D[功能工程師];
D --> E[訓練];
E --> F[評估];
F-->C;
E --> G[部署];
G --> H[監控];
H-->A;
人們在不同階段使用不同的數據表示來提高效能或受到可用工具的限制。學術界主要使用 XML / JSON 進行註釋,並使用壓縮影像/感測器資料進行深度學習,這些資料很難整合到資料基礎設施中,並且在雲端儲存上訓練速度很慢。雖然業界使用資料湖(基於 Parquet 的技術,即 Delta Lake、Iceberg)或資料倉儲(AWS Redshift 或 Google BigQuery)來收集和分析數據,但他們必須將資料轉換為適合訓練的格式,例如 Rikai/ Petastorm 或TFRecord。多個單一用途的資料轉換以及將雲端儲存之間的副本同步到本地訓練實例已成為常見做法。
雖然每種現有資料格式都能夠勝任其最初設計的工作負載,但我們需要一種針對多階段 ML 開發週期量身定制的新資料格式,以減少資料孤島。
機器學習開發週期每個階段不同資料格式的比較。
| 槊 | 實木複合地板和獸人 | JSON 和 XML | TF記錄 | 資料庫 | 倉庫 | |
|---|---|---|---|---|---|---|
| 分析 | 快速地 | 快速地 | 慢的 | 慢的 | 體面的 | 快速地 |
| 特徵工程 | 快速地 | 快速地 | 體面的 | 慢的 | 體面的 | 好的 |
| 訓練 | 快速地 | 體面的 | 慢的 | 快速地 | 不適用 | 不適用 |
| 勘探 | 快速地 | 慢的 | 快速地 | 慢的 | 快速地 | 體面的 |
| 基礎設施支持 | 富有的 | 富有的 | 體面的 | 有限的 | 富有的 | 富有的 |
Lance 目前用於生產的有:


