duplicut
v2.2 release
如今,密碼單字清單的建立通常意味著連接多個資料來源。
理想情況下,最可能的密碼應位於單字清單的開頭,因此最常見的密碼會立即被破解。
使用現有的重複資料刪除工具,您必須選擇希望保留順序或處理大量單字清單。
不幸的是,創建單字清單需要以下兩者:

所以我用高度最佳化的 C 語言寫了 duplicut 來解決這個非常具體的需求?
git clone https://github.com/nil0x42/duplicut
cd duplicut/ && make
./duplicut wordlist.txt -o clean-wordlist.txt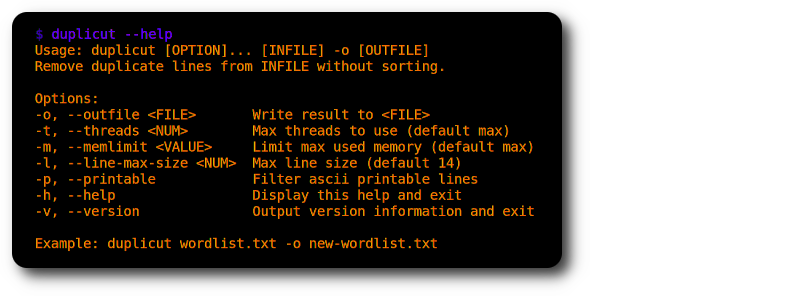
特徵:
-l選項)-p選項)執行:
限制:
透過將size資訊打包在指標的額外位元中, uint64足以索引雜湊圖中的行:
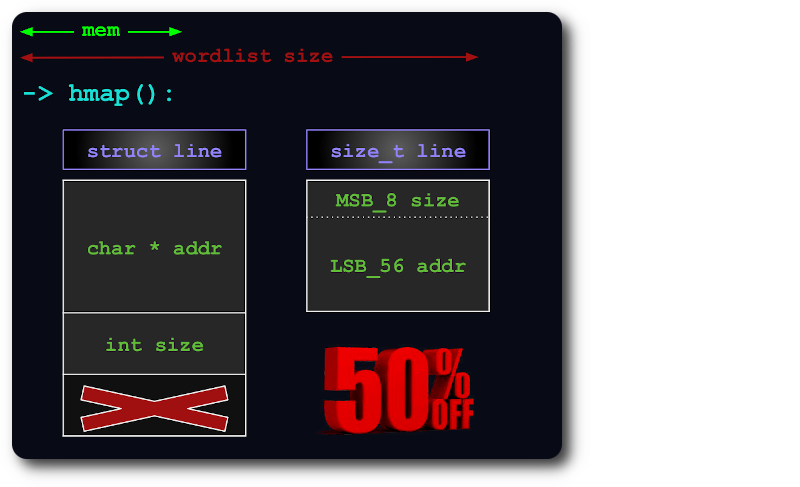
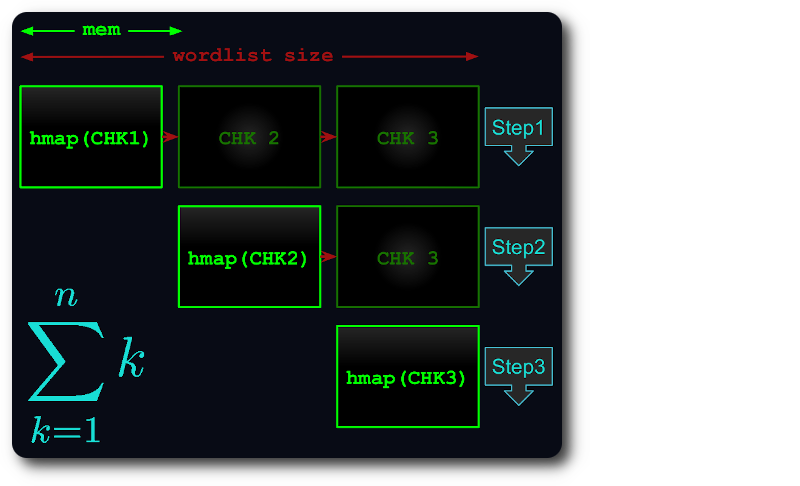
如果整個檔案無法容納在記憶體中,則會將其拆分為虛擬區塊,這樣每個區塊都會使用盡可能多的 RAM。
然後將每個區塊載入到哈希映射中,進行重複資料刪除,並針對後續區塊進行測試。
這樣,執行時間最多減少到第 th 個三角形:
如果您發現錯誤,或者某些內容未按預期工作,請在偵錯模式下編譯重複項並發布帶有附加輸出的問題:
# debug level can be from 1 to 4
make debug level=1
./duplicut [OPTIONS] 2>&1 | tee /tmp/duplicut-debug.log


