dream
v1.13.0
DeepPavlov Dream是一個用於創建多技能生成式人工智慧助理的平台。
要了解有關該平台以及如何用它構建人工智能助手的更多信息,請訪問 Dream。如果您想了解有關為 Dream 提供支援的 DeepPavlov Agent 的更多信息,請訪問 DeepPavlov Agent 文件。
我們已經包含了六個發行版:其中四個基於輕量級 Deepy 社交機器人,一個是英文版的全尺寸 Dream 聊天機器人(基於 Alexa 獎挑戰版),另一個是俄語版 Dream 聊天機器人。
月球助手的基礎版本。 Deepy Base 包含拼字預處理註解器、基於範本的 Harvesters Maintenance Skill 和基於 Dialog Flow Framework 的 AIML 開放域 Program-y Skill。
月球助手進階版。 Deepy Advanced 包含拼字預處理、句子分割、實體連結和意圖捕捉器註釋器、用於目標導向回應的 Harvesters Maintenance GoBot Skill 以及基於 Dialog Flow Framework 的 AIML 開放域 Program-y Skill。
月球助手FAQ版本。 Deepy FAQ包含拼字預處理註釋器、基於範本的常見問題解答技能和基於對話流程框架的基於AIML的開放域Program-y技能。
月球助手的目標導向版本。 Deepy GoBot Base 包含拼字預處理註解器、用於目標導向回應的 Harvesters Maintenance GoBot Skill 以及基於 Dialog Flow Framework 的 AIML 開放式 Program-y Skill。
DeepPavlov Dream 社交機器人的完整版本。這幾乎與 Alexa 大獎挑戰賽 4 結束時的 DREAM 社交機器人版本相同。某些服務(例如新聞註釋器、遊戲技能、天氣技能)需要底層 API 的私鑰,其中大多數可以免費取得。如果您想在本機部署中使用這些服務,請將您的金鑰新增至環境變數(例如./.env 、 ./.env_ru )。此版本的 Dream Socialbot 由於其模組化架構和最初的目標(參加 Alexa 大獎挑戰賽)而消耗了大量資源。我們在我們的網站上提供了 Dream Socialbot 的示範。
DeepPavlov Dream 社交機器人的迷你版。這是一個基於生成的社交機器人,使用英語 DialoGPT 模型來產生大部分回應。它還包含意圖捕獲器和響應器組件來滿足特殊的用戶請求。連結到發行版。
DeepPavlov Dream 社交機器人的俄語版本。這是一個基於生成的社交機器人,它使用 DeepPavlov 的 Russian DialoGPT 來產生大部分回應。它還包含意圖捕獲器和響應器組件來滿足特殊的用戶請求。連結到發行版。
DeepPavlov Dream Socialbot 的迷你版,使用基於提示的生成模型。這是一個基於生成的社交機器人,它使用大型語言模型來產生大部分回應。您可以將自己的提示(json 檔案)上傳到 common/prompts,將提示名稱新增至PROMPTS_TO_CONSIDER (以逗號分隔),提供的資訊將在 LLM 支援的回覆產生中用作提示。連結到發行版。
docker版本20以上;docker-compose v1.29.2 版本; git clone https://github.com/deeppavlov/dream.git
如果執行 docker-compose 時出現「權限被拒絕」錯誤,請確保正確配置 docker 使用者。
docker-compose -f docker-compose.yml -f assistant_dists/deepy_base/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_adv/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_faq/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_gobot_base/docker-compose.override.yml up --build
嘗試 Dream 的最簡單方法是透過代理部署它。所有請求都將被重定向到 DeepPavlov API,因此您不必使用任何本機資源。有關詳細信息,請參閱代理使用情況。
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
請注意,DeepPavlov Dream 元件需要大量資源。請參閱組件部分以了解估計的需求。
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml up --build
我們也提供了針對多 GPU 環境的 GPU 分配配置:
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/test.yml up
當您需要重新啟動特定的 docker 容器而不重新建置時(確保assistant_dists/dream/dev.yml中的映射正確):
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml restart container-name
docker-compose -f docker-compose.yml -f assistant_dists/dream_persona_prompted/docker-compose.override.yml -f assistant_dists/dream_persona_prompted/dev.yml -f assistant_dists/dream_persona_prompted/proxy.yml up --build
我們也提供了針對多 GPU 環境的 GPU 分配配置。
DeepPavlov Agent 提供了多種互動選項:命令列介面、HTTP API 和 Telegram 機器人
在單獨的終端選項卡中運行:
docker-compose exec agent python -m deeppavlov_agent.run agent.channel=cmd agent.pipeline_config=assistant_dists/dream/pipeline_conf.json
輸入您的使用者名稱並與 Dream 聊天!
啟動機器人後,DeepPavlov 的代理程式 API 將在http://localhost:4242上運作。您可以從 DeepPavlov Agent 文件了解該 API。
基本的聊天介面將在http://localhost:4242/chat上提供。
目前,部署的是 Telegram bot,而不是HTTP API。在docker-compose.override.yml配置中編輯agent command定義:
agent:
command: sh -c 'bin/wait && python -m deeppavlov_agent.run agent.channel=telegram agent.telegram_token=<TELEGRAM_BOT_TOKEN> agent.pipeline_config=assistant_dists/dream/pipeline_conf.json'
注意:將您的 Telegram 令牌視為秘密,不要提交到公共儲存庫!
Dream 使用幾個 docker-compose 設定檔:
./docker-compose.yml是核心配置,其中包括 DeepPavlov Agent 和 mongo 資料庫的容器;
./assistant_dists/*/docker-compose.override.yml列出了該發行版的所有元件;
./assistant_dists/dream/dev.yml包含磁碟區綁定,以便於 Dream 除錯;
./assistant_dists/dream/proxy.yml是代理容器的清單。
如果您的部署資源有限,您可以將容器替換為由 DeepPavlov 託管的代理副本。為此,請覆蓋proxy.yml中的那些容器定義,例如:
convers-evaluator-annotator:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8004
- SERVICE_PORT=8004
並將此配置包含在您的部署命令中:
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
預設情況下, proxy.yml包含所有可用的代理定義。
夢想建築如下圖所示: 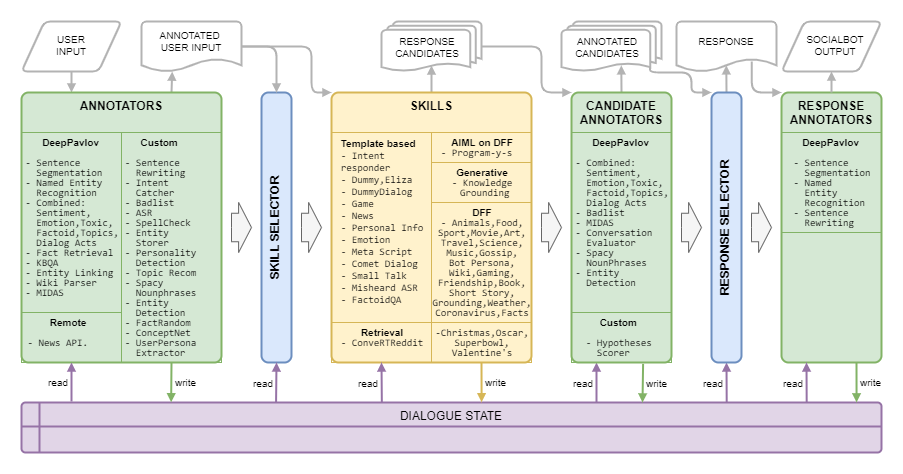
| 姓名 | 要求 | 描述 |
|---|---|---|
| 基於規則的選擇器 | 根據主題、實體、情緒、毒性、對話行為和對話歷史選擇技能清單來產生對當前上下文的候選回應的演算法 | |
| 響應選擇器 | 50MB 內存 | 從給定的候選響應清單中選擇最終響應的演算法 |
| 姓名 | 要求 | 描述 |
|---|---|---|
| 自動語音識別 | 40MB 內存 | 計算給定話語的整體 ASR 置信度,並將其評為非常低、低、中或高(針對亞馬遜標記) |
| 列入不良清單的單字 | 150MB 內存 | 檢測不良清單中的單字和短語 |
| 組合分類 | 1.5 GB 內存,3.5 GB GPU | 基於BERT的模型,包括主題分類、對話行為分類、情緒、毒性、情緒、事實分類 |
| 組合分類輕量化 | 1.6 GB 內存 | 與組合分類相同的模型,但由於主幹網路更輕,花費的時間減少了 42% |
| 彗星原子 | 2 GB 內存,1.1 GB GPU | 常識預測模型 COMeT Atomic |
| COMeT概念網 | 2 GB 內存,1.1 GB GPU | 常識預測模型 COMeT ConceptNet |
| Convers 評估器註釋器 | 1 GB 內存,4.5 GB GPU | 根據先前比賽的 Alexa 獎數據進行訓練,並預測候選人的回答是否有趣、可理解、切題、有吸引力或錯誤 |
| 情緒分類 | 2.5 GB 內存 | 情感分類標註器 |
| 實體偵測 | 1.5 GB 內存,3.2 GB GPU | 從話語中擷取實體及其類型 |
| 實體連結 | 2.5 GB 內存,1.3 GB GPU | 尋找使用實體偵測偵測到的實體的維基資料實體 ID |
| 實體儲存 | 220MB 內存 | 基於規則的元件,如果使用模式或 MIDAS 分類器偵測到意見表達,則儲存來自使用者和社交機器人話語的實體,並將它們與偵測到的對話狀態態度一起保存 |
| 事實隨機 | 50MB 內存 | 傳回給定實體的隨機事實(對於來自使用者話語的實體) |
| 事實檢索 | 7.4 GB 內存,1.2 GB GPU | 從 Wikipedia 和 wikiHow 中提取事實 |
| 意圖捕手 | 1.7 GB 內存,2.4 GB GPU | 將使用者話語分類為許多預先定義的意圖,這些意圖在一組短語和正規表示式上進行訓練 |
| KBQA | 2 GB 內存,1.4 GB GPU | 根據 Wikidata KB 回答使用者的事實問題 |
| 邁達斯分類 | 1.1 GB 內存,4.5 GB GPU | 基於 BERT 的模型在 MIDAS 資料集的語意類別子集上進行訓練 |
| MIDAS 預測器 | 30MB 內存 | 基於 BERT 的模型在 MIDAS 資料集的語意類別子集上進行訓練 |
| NER | 2.2 GB 內存,5 GB GPU | 從無大小寫文字中提取人名、地點名稱、組織名稱 |
| 新聞 API 註解器 | 80MB 內存 | 使用 GNews API 提取有關實體或主題的最新新聞。 DeepPavlov Dream 部署使用我們自己的 API 金鑰。 |
| 個性捕手 | 30MB 內存 | 此技能是透過聊天介面改變系統的個性描述,它的作用相當於系統指令,回應的是類似系統的訊息 |
| 提示選擇器 | 50MB 內存 | 註釋器利用句子排名器對提示進行排名並選擇N_SENTENCES_TO_RETURN最相關的提示(基於提示中提供的問題) |
| 財產提取 | 6.3 GiB 內存 | 從話語中提取使用者屬性 |
| 耙動關鍵字 | 40MB 內存 | 借助 RAKE 演算法從話語中擷取關鍵字 |
| 相對角色提取器 | 50MB 內存 | 註釋者利用句子排名器對人物句子進行排名並選擇N_SENTENCES_TO_RETURN最相關的句子 |
| 森特瑞特 | 200MB 內存 | 透過以特定名稱替換代名詞來重寫使用者的話語,為下游組件提供更多有用的信息 |
| 聖塞格 | 1 GB 內存 | 允許我們透過將使用者的話語分成句子並恢復標點符號來處理長而複雜的使用者話語 |
| 空格名詞片語 | 180MB 內存 | 使用 Spacy 提取名詞短語並過濾掉通用短語 |
| 語音功能分類器 | 1.1 GB 內存,4.5 GB GPU | Eggins 和 Slade 描述的基於多個線性模型的分層演算法和基於規則的語音函數預測方法 |
| 語音功能預測器 | 1.1 GB 內存,4.5 GB GPU | 產生可以遵循語音函數分類器預測的語音函數的語音函數的機率 |
| 拼字預處理 | 50MB 內存 | 基於模式的元件將不同的口語表達重寫為更正式的對話風格 |
| 話題推薦 | 40MB 內存 | 使用有關討論的主題和使用者偏好的資訊提供進一步對話的主題。目前版本是基於 Reddit 人物(請參閱 Alexa 獎 4 的夢想報告)。 |
| 毒性分類 | 3.5 GB 內存,3 GB GPU | 來自 Transformers 的有毒分類模型指定為 PRETRAINED_MODEL_NAME_OR_PATH |
| 使用者角色提取器 | 40MB 內存 | 根據一些關鍵字判斷使用者屬於哪個年齡段 |
| 維基解析器 | 100MB 內存 | 提取透過實體連結偵測到的實體的維基資料三元組 |
| 維基事實 | 1.7GB 內存 | 從 Wikipedia 和 WikiHow 頁面提取相關事實的模型 |
| 姓名 | 要求 | 描述 |
|---|---|---|
| 迪亞洛GPT | 1.2 GB 內存,2.1 GB GPU | 基於 Transformers 生成模型的生成服務,該模型在 docker compose 參數PRETRAINED_MODEL_NAME_OR_PATH中設定(例如, microsoft/DialoGPT-small ,GPU 上的時間為 0.2-0.5 秒) |
| 基於 DialoGPT 角色 | 1.2 GB 內存,2.1 GB GPU | 基於 Transformers 生成模型的生成服務,該模型在 PersonaChat 資料集上進行了預訓練,以產生以社交機器人角色的幾個句子為條件的響應 |
| 圖片字幕 | 4 GB 內存,5.4 GB GPU | 建立接收到的圖像的文字表示 |
| 填充 | 1 GB 內存,1.2 GB GPU | (關閉但代碼可用)基於 Infilling 模型的生成服務,對於給定的話語返回話語,其中原始文本中的_被生成的標記替換 |
| 知識基礎 | 2 GB 內存,2.1 GB GPU | 基於 BlenderBot 架構的生成服務,考慮附加文字段落,提供對上下文的回應 |
| 蒙面LM | 1.1 GB 內存,1 GB GPU | (已關閉但代碼可用) |
| 基於Seq2seq Persona | 1.5 GB 內存,1.5 GB GPU | 基於 Transformers seq2seq 模型的生成服務,該模型在 PersonaChat 資料集上進行了預訓練,以產生以社交機器人角色的幾個句子為條件的響應 |
| 句子排名 | 1.2 GB 內存,2.1 GB GPU | 以PRETRAINED_MODEL_NAME_OR_PATH給出的排名模型,對於一對 os 句子返回對應的浮點分數 |
| 故事GPT | 2.6 GB 內存,2.15 GB GPU | 基於微調 GPT-2 的生成服務,對於給定的一組關鍵字,傳回使用該關鍵字的短篇故事 |
| GPT-3.5 | 100MB 內存 | 基於 OpenAI API 服務的生成服務,模型在 docker compose 參數PRETRAINED_MODEL_NAME_OR_PATH中設定(特別是,在此服務中,使用了text-davinci-003 。 |
| 聊天GPT | 100MB 內存 | 基於 OpenAI API 服務的產生服務,模型在 docker compose 參數PRETRAINED_MODEL_NAME_OR_PATH中設定(特別是,在此服務中,使用gpt-3.5-turbo 。 |
| 提示故事GPT | 3 GB 內存,4 GB GPU | 基於微調 GPT-2 的生成服務,對於由一個名詞表示的給定主題,傳回給定主題的短篇故事 |
| GPT-J 6B | 1.5 GB 內存,24.2 GB GPU | 基於 Transformers 生成模型的生成服務,模型在 docker compose 參數PRETRAINED_MODEL_NAME_OR_PATH中設定(特別是,在該服務中,使用 GPT-J 模型。 |
| 布魯姆茲7B | 2.5 GB 內存,29 GB GPU | 基於 Transformers 生成模型的生成服務,該模型在 docker compose 參數PRETRAINED_MODEL_NAME_OR_PATH中設定(特別是,在此服務中,使用 BLOOMZ-7b1 模型。 |
| GPT-JT 6B | 2.5 GB 內存,25.1 GB GPU | 基於 Transformers 生成模型的生成服務,模型在 docker compose 參數PRETRAINED_MODEL_NAME_OR_PATH中設定(特別是,在該服務中,使用 GPT-JT 模型。 |
| 姓名 | 要求 | 描述 |
|---|---|---|
| 亞歷克斯·漢德勒 | 30MB 內存 | 幾個特定 Alexa 指令的處理程序 |
| 聖誕節技能 | 30MB 內存 | 支援聖誕節常見問題、事實和腳本 |
| 彗星對話技能 | 300MB 內存 | 使用 COMeT ConceptNet 模型來表達意見、提出問題或對對話中提到的使用者操作進行評論 |
| 轉換 Reddit | 1.2GB 內存 | 使用 ConveRT 編碼器為句子建立有效的表示 |
| 假人技能 | 代理容器的一部分 | 具有多個無毒候選反應的後備技能 |
| 虛擬技能對話框 | 600MB 內存 | 如果使用者對虛擬技能的回應與來源資料中的相應回應相似,則傳回主題聊天資料集中的下一個回合 |
| 伊麗莎 | 30MB 內存 | 聊天機器人 (https://github.com/wadetb/eliza) |
| 情感技巧 | 40MB 內存 | 傳回來自組合分類註釋器的情緒分類所偵測到的情緒的範本回應 |
| 事實問答 | 170MB 內存 | 回答事實問題 |
| 遊戲合作技巧 | 100MB 內存 | 為用戶提供有關電腦遊戲的對話:過去一年、過去一個月和上週的最佳遊戲排行榜 |
| 收割機維修技巧 | 30MB 內存 | 收割機的維修保養技巧 |
| 收割機維護 Gobot 技能 | 30MB 內存 | 收割機維護 目標導向技能 |
| 知識基礎技能 | 100MB 內存 | 根據對話歷史產生回應並提供與當前對話主題相關的知識 |
| 元腳本技能 | 150MB 內存 | 提供圍繞人類活動的多輪對話。此技能使用 COMeT Atomic 模型產生多個方面的常識性描述和問題 |
| 聽錯了 ASR | 40MB 內存 | 當 ASR 置信度太低時,使用 ASR 處理器註解向使用者提供回饋 |
| 新聞API技巧 | 60MB 內存 | 使用 GNews API 呈現有關實體或主題的最受好評的最新新聞 |
| 奧斯卡技能 | 30MB 內存 | 支持奧斯卡常見問題、事實和腳本 |
| 個人資訊技能 | 40MB 內存 | 查詢並儲存使用者的姓名、出生地和位置 |
| DFF 計劃 Y 技能 | 800MB 內存 | [新 DFF 版本]聊天機器人程式 Y (https://github.com/keiffster/program-y) 適用於 Dream 社交機器人 |
| DFF 計劃 Y 危險技能 | 100MB 內存 | [新 DFF 版本]聊天機器人程式 Y (https://github.com/keiffster/program-y) 適用於 Dream 社交機器人,包含對話中危險情況的回應 |
| DFF 計劃 Y 廣泛技能 | 110MB 內存 | [新DFF版本] Chatbot Program Y(https://github.com/keiffster/program-y)適用於Dream Socialbot,僅包含非常通用的模板(置信度較低) |
| 閒聊技巧 | 35MB 內存 | 使用手寫腳本提出 25 個主題的問題,包括但不限於愛情、運動、工作、寵物等。 |
| 超級盃技巧 | 30MB 內存 | 支持 SuperBowl 的常見問題、事實和腳本 |
| 文字品質檢查 | 1.8 GB 內存,2.8 GB GPU | 該服務在文本中尋找事實問題的答案。 |
| 情人節技巧 | 30MB 內存 | 支援情人節常見問題、事實和腳本 |
| 維基數據撥號技巧 | 100MB 內存 | 使用 Wikidata 三元組產生話語。未開啟,需要改進 |
| DFF動物技能 | 200MB 內存 | 使用 DFF 創建,具有關於動物的三個對話分支:使用者的寵物、社交機器人的寵物和野生動物 |
| DFF藝術技巧 | 100MB 內存 | 基於 DFF 的藝術討論技巧 |
| DFF書籍技能 | 400MB 內存 | [新 DFF 版本]借助 Wiki 解析器和實體連結來偵測使用者話語中提到的書名和作者,並利用 GoodReads 資料庫中的資訊推薦書籍 |
| DFF 機器人角色技能 | 150MB 內存 | 旨在透過短篇故事討論用戶最喜歡的內容和 20 個最受歡迎的事物,表達社交機器人對他們的看法 |
| DFF 冠狀病毒技能 | 110MB 內存 | [新 DFF 版本]檢索來自約翰霍普金斯大學系統科學與工程中心的不同地點的冠狀病毒病例數和死亡人數數據 |
| DFF 食物技能 | 150MB 內存 | 用 DFF 構建,鼓勵與食物相關的對話 |
| DFF友誼技能 | 100MB 內存 | [新 DFF 版本]基於 DFF 的技能在對話框開始時問候用戶,並將用戶轉發到一些腳本化技能 |
| DFF 功能技能 | 100MB 內存 | 【新DFF版本】告訴用戶有趣的事實 |
| DFF遊戲技巧 | 80MB 內存 | 提供視頻遊戲討論。遊戲技能是關於視頻遊戲的更一般性的討論 |
| DFF八卦技能 | 95MB 內存 | 基於 DFF 的技能來討論其他人的新聞 |
| DFF影像技巧 | 100MB 內存 | [新 DFF 版本]腳本化技能,基於發送的圖像字幕(來自註釋)響應,在檢測到食物、動物或人的情況下具有指定響應,否則預設響應 |
| DFF模板技巧 | 50MB 內存 | [新DFF版本]基於DFF的技能,提供DFF使用範例 |
| DFF模板提示技巧 | 50MB 內存 | [新 DFF 版本]基於 DFF 的技能,提供語言模型根據指定提示和對話上下文產生的答案。要使用的模型在 GENERATIVE_SERVICE_URL 中指定。例如,您可以使用 Transformer LM GPTJ 服務。 |
| DFF接地技巧 | 90MB 內存 | [新DFF版本]基於DFF的技能來回答對話的主題是什麼,產生確認,透過MIDAS對某些對話行為產生通用回應 |
| DFF 意圖響應器 | 100MB 內存 | [新DFF版本]為Intent Catcher註釋器檢測到的一些意圖提供基於模板的回复 |
| DFF電影技巧 | 1.1GB 內存 | 使用 DFF 實現並處理與電影相關的對話 |
| DFF音樂技巧 | 70MB 內存 | 基於 DFF 的音樂討論技巧 |
| DFF科學技能 | 90MB 內存 | 基於 DFF 的科學討論技能 |
| DFF短篇小說技巧 | 90MB 內存 | 【新DFF版本】為使用者講述3類短故事:(1)睡前故事,例如寓言和道德故事,(2)恐怖故事,(3)搞笑故事 |
| DFF運動技能 | 70MB 內存 | 基於 DFF 的體育討論技能 |
| DFF 旅行技巧 | 70MB 內存 | 基於 DFF 的旅行討論技巧 |
| DFF 天氣技能 | 1.4 GB 內存 | [新DFF版本]使用OpenWeatherMap服務取得用戶位置的天氣預報 |
| DFF 維基技能 | 150MB 內存 | 用於製作包含實體提取、槽填充、事實插入和確認的場景 |
| 姓名 | 要求 | 描述 |
|---|---|---|
| AI常見問題技巧 | 150MB 內存 | 【新DFF版本】關於現代人工智慧你想知道但又不敢問的一切!這個常見問題解答助理會與您聊天,同時解釋當今科技世界中最簡單的主題。 |
| 時尚造型師技能 | 150MB 內存 | 【新DFF版本】達科斯塔工業服裝助手,讓每個季節都受到保護!無論天氣如何,都能體驗終極的舒適和保護。冬天要注意保暖,... |
| 夢境角色技能 | 150MB 內存 | [新DFF版本]基於提示的技能,利用給定的生成服務根據給定的提示產生回應 |
| 行銷技巧 | 150MB 內存 | [新DFF版本]透過行銷AI助理以前所未有的方式與您的受眾建立聯繫!透過利用同理心的力量達到成功的新高度。告別.. |
| 童話技能 | 150MB 內存 | 【新版DFF】小助手將為您或您的孩子講述一個簡短卻引人入勝的童話故事。選擇人物和主題,剩下的就交給人工智慧想像。 |
| 營養技能 | 150MB 內存 | 【DFF新版】與AI助理一起探索健康飲食的秘密!輕鬆為您和您所愛的人找到營養豐富的食物選擇。告別用餐壓力,迎接美味… |
| 生活輔導技巧 | 150MB 內存 | 【新DFF版本】使用Rhodes & Co的專利AI助理釋放您的全部潛力!在工作和家庭中達到最佳表現。輕鬆進入最佳狀態並激勵他人。 |
庫拉托夫 Y. 等。 2019 年 Alexa 獎的 DREAM 技術報告//Alexa 獎論文集。 – 2020 年。
Baymurzina D.等人。 Alexa 獎 4 //Alexa 獎程式的 DREAM 技術報告。 – 2021 年。
DeepPavlov Dream 在 Apache 2.0 下獲得許可。
Program-y(請參閱dream/skills/dff_program_y_skill 、 dream/skills/dff_program_y_wide_skill 、 dream/skills/dff_program_y_dangerous_skill )在 Apache 2.0 下獲得許可。 Eliza(請參閱dream/skills/eliza )根據 MIT 許可證獲得許可。
要製作帶有機器人回應的認證xlsx文件,您可以透過執行來使用xlsx_responder.py腳本
docker-compose -f docker-compose.yml -f dev.yml exec -T -u $( id -u ) agent python3
utils/xlsx_responder.py --url http://0.0.0.0:4242
--input ' tests/dream/test_questions.xlsx '
--output ' tests/dream/output/test_questions_output.xlsx '
--cache tests/dream/output/test_questions_output_ $( date --iso-8601=seconds ) .json確保所有服務均已部署。 --input - 包含認證問題的xlsx文件, --output - 包含機器人回應的xlsx文件, --cache - json ,其中包含詳細標記並用於快取。


