Okapi
1.0.0
霍加狓
透過人類回饋進行強化學習的多語言指令調整大型語言模型
這是 Okapi 框架的儲存庫,引入了針對大型語言模型 (LLM) 的指令調整的資源和模型,以及基於多種語言的人類回饋 (RLHF) 的強化學習。我們的框架支援 26 種語言,其中包括 8 種高資源語言、11 種中等資源語言和 7 種低資源語言。
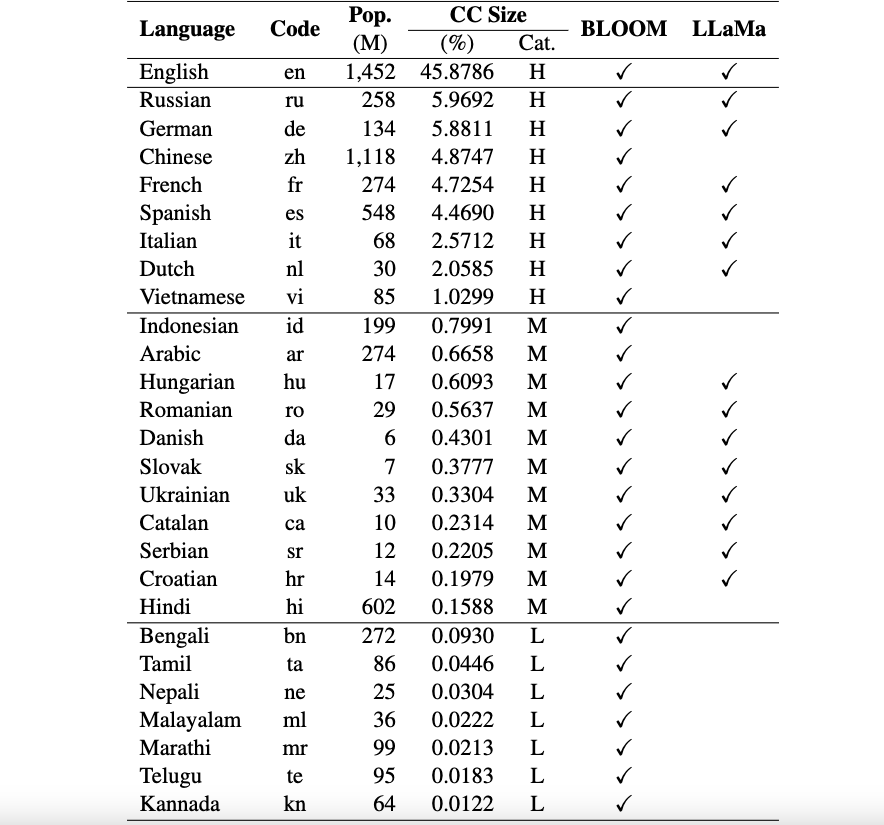
Okapi 資源:我們提供使用 RLHF 對 26 種語言進行指令調校的資源,包括 ChatGPT 提示、多語言指令資料集和多語言回應排名資料。
Okapi 模型:我們在 Okapi 資料集上為 26 種語言提供基於 RLHF 的指令調整的 LLM。我們的模型包括基於 BLOOM 和基於 LLaMa 的版本。我們還提供與我們的模型互動的腳本,並使用我們的資源微調法學碩士。
多語言評估基準資料集:我們提供三個基準資料集,用於評估 26 種語言的多語言大語言模型 (LLM)。您可以存取完整的資料集和評估腳本:此處。
使用和許可聲明:Okapi 僅供研究使用並獲得許可。資料集為 CC BY NC 4.0(僅允許非商業用途),使用此資料集訓練的模型不應在研究目的之外使用。
我們的技術論文和評估結果可以在這裡找到。
我們執行全面的資料收集流程,透過四個主要步驟為我們的多語言框架 Okapi 準備必要的資料:
若要下載整個資料集,您可以使用以下腳本:
bash scripts/download.sh如果您只需要特定語言的數據,則可以將語言代碼指定為腳本的參數:
bash scripts/download.sh [LANG]
# For example, to download the dataset for Vietnamese: bash scripts/download.sh vi下載後,我們發布的資料可以在datasets目錄中找到。它包括:
multilingual-alpaca-52k :Alpaca 中 52K 英文指令翻譯成 26 種語言的資料。
multilingual-ranking-data-42k :26種語言的多語言回應排名資料。對於每種語言,我們提供42K指令;他們每個人都有 4 個排名回應。這些數據可用於訓練 26 種語言的獎勵模型。
multilingual-rl-tuning-64k :RLHF 的多語言指令資料。我們為 26 種語言中的每一種提供 62K 指令。
使用我們的 Okapi 資料集和基於 RLHF 的指令調校技術,我們引入了針對 26 種語言的多語言微調 LLM,這些語言建立在 7B 版本的 LLaMA 和 BLOOM 的基礎上。這些型號可以從 HuggingFace 取得。
Okapi 支援與 26 種語言的多語言指示調整的法學碩士進行互動式聊天。請依照以下步驟進行聊天:
git clone https://github.com/nlp-uoregon/Okapi.git
cd Okapi
pip install -r requirements.txt
from chat import pipeline
model_path = 'uonlp/okapi-vi-bloom'
p = pipeline ( model_path , gpu = True )
instruction = 'Dịch câu sau sang Tiếng Việt' # Translate the following sentence into Vietnamese
prompt_input = 'The City of Eugene - a great city for the arts and outdoors. '
response = p . generate ( instruction = instruction , prompt_input = prompt_input )
print ( response )我們還提供腳本,使用 RLHF 使用我們的指令資料對 LLM 進行微調,涵蓋三個主要步驟:監督微調、獎勵建模和使用 RLHF 進行微調。使用以下步驟微調 LLM:
conda create -n okapi python=3.9
conda activate okapi
pip install -r requirements.txtbash scripts/supervised_finetuning.sh [LANG]bash scripts/reward_modeling.sh [LANG]bash scripts/rl_training.sh [LANG]如果您使用此儲存庫中的資料、模型或程式碼,請引用:
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

