MELD
1.0.0
如果您對智商測驗法學碩士感興趣,請查看我們的新作品:AlgoPuzzleVQA
我們發布了使用 Resnet 提取的視覺特徵 - https://github.com/declare-lab/MM-Align
有關更新的基線,請訪問此連結:conv-emotion
要下載數據,請使用 wget: wget http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz
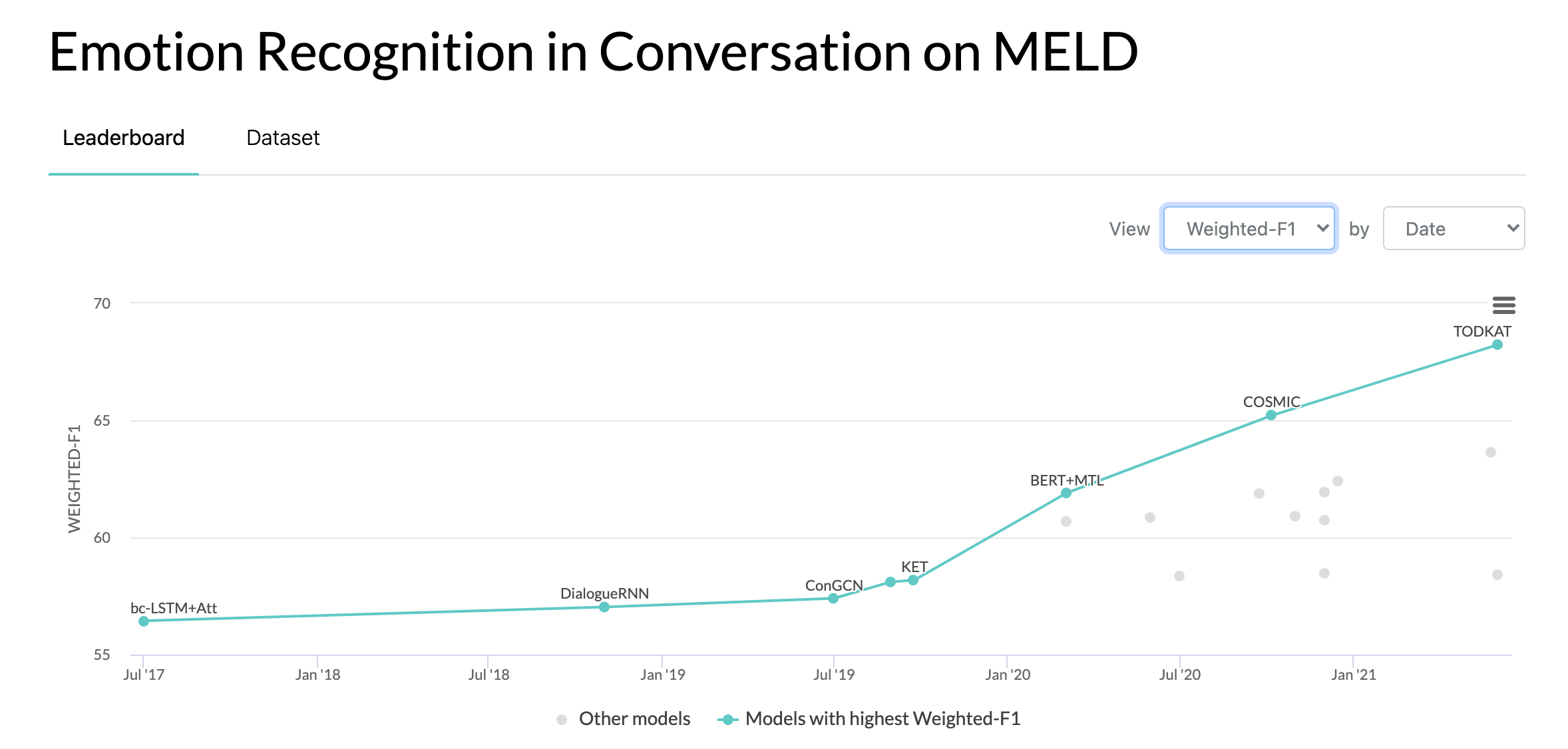
2020 年 10 月 10 日:MELD 資料集對話中情緒辨識的新論文和 SOTA。代碼請參閱 COSMIC 目錄。閱讀論文 - COSMIC:對話中情緒辨識的 COMmonSense 知識。
2019 年 5 月 22 日:MELD:對話中情緒辨識的多模式多方資料集已被 ACL 2019 接受為全文。
2019 年 5 月 22 日:二元 MELD 已發布。它可用於測試二元對話模型。
2018 年 11 月 15 日:train.tar.gz 中的問題已修復。
張亞洲、李秋池、宋大偉、張鵬、王盼盼。 “用於對話情緒分析的量子啟發互動式網路。”國際JCAI 2019。
張、董、吳良慶、孫長龍、李壽山、朱巧明和周國棟。 “對上下文和說話者敏感依賴性進行建模,以實現多說話人對話中的情緒檢測。”國際JCAI 2019。
Ghosal、Deepanway、Navonil Majumder、Soujanya Poria、Niyati Chhaya 和 Alexander Gelbukh。 “DialogueGCN:用於對話中情緒識別的圖卷積神經網路。” EMNLP 2019。
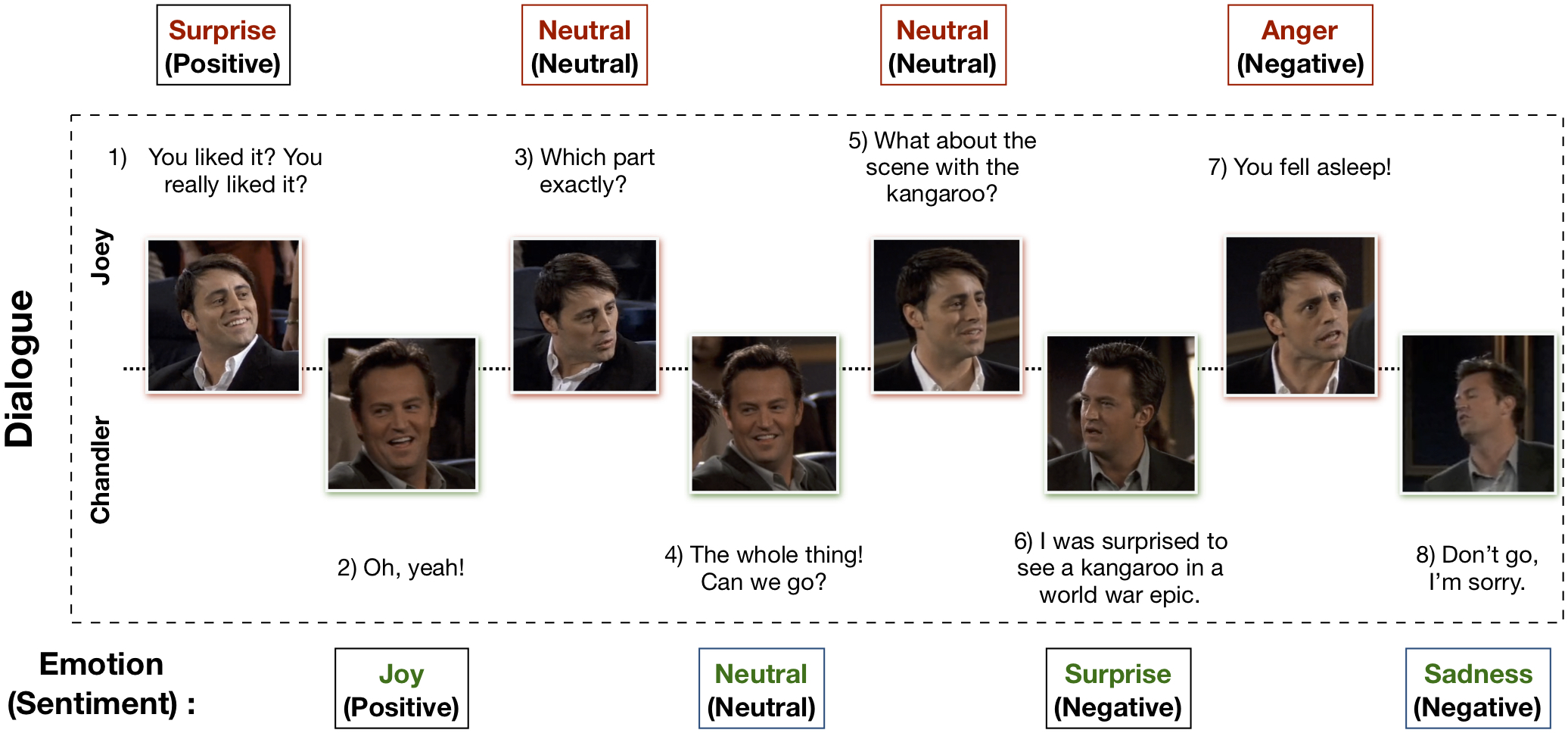
多模態 EmotionLines 資料集 (MELD) 是透過增強和擴展 EmotionLines 資料集建立的。 MELD 包含與 EmotionLines 中相同的對話實例,但它還包含音訊和視覺模式以及文字。 MELD 擁有《老友記》電視劇中的 1400 多個對話和 13000 多個話語。多位發言者參與了對話。對話中的每句話都被標記為這七種情緒中的任何一種:憤怒、厭惡、悲傷、喜悅、中性、驚訝和恐懼。 MELD 也為每個話語提供情緒(正面、負面和中立)註釋。
| 統計數據 | 火車 | 開發者 | 測試 |
|---|---|---|---|
| 模態# | {a,v,t} | {a,v,t} | {a,v,t} |
| # 獨特的單字 | 10,643 | 2,384 | 4,361 |
| 平均。話語長度 | 8.03 | 7.99 | 8.28 |
| 最大限度。話語長度 | 69 | 37 | 45 |
| 平均。每個對話的情緒數量 | 3.30 | 3.35 | 3.24 |
| 對話數量 | 1039 | 114 | 280 |
| # 話語數 | 9989 | 1109 | 2610 |
| 發言者數量 | 260 | 47 | 100 |
| # 情緒轉變 | 4003 | 第427章 | 1003 |
| 平均。話語的持續時間 | 3.59秒 | 3.59秒 | 3.58秒 |
請造訪 https://affective-meld.github.io 以了解更多詳情。
| 火車 | 開發者 | 測試 | |
|---|---|---|---|
| 憤怒 | 1109 | 153 | 第345章 |
| 厭惡 | 第271章 | 22 | 68 |
| 害怕 | 268 | 40 | 50 |
| 喜悅 | 第1743章 | 163 | 第402章 |
| 中性的 | 4710 | 第470章 | 第1256章 |
| 悲傷 | 第683章 | 111 | 208 |
| 驚喜 | 1205 | 150 | 第281章 |
多模態資料分析利用多個平行資料通道的資訊進行決策。隨著人工智慧的快速發展,多模態情感識別引起了人們的主要研究興趣,這主要是由於它在許多具有挑戰性的任務中的潛在應用,例如對話生成、多模態互動等。識別系統可用於透過以下方式產生適當的回應:分析使用者情緒。儘管關於多模態情感辨識的工作有很多,但真正關注於理解對話中的情緒的研究卻很少。然而,他們的工作僅限於二元對話理解,因此無法擴展到具有兩個以上參與者的多方對話中的情緒識別。 EmotionLines 只能用作文字情緒識別的資源,因為它不包括來自其他形式(例如視覺和音訊)的資料。同時,應該指出的是,目前還沒有可用於情緒辨識研究的多模態多方會話資料集。在這項工作中,我們針對多模式場景擴展、改進和進一步開發了 EmotionLines 資料集。連續輪流中的情緒辨識面臨一些挑戰,而上下文理解就是其中之一。對話中的情緒變化和情緒流動使得準確的上下文建模成為一項艱鉅的任務。在此資料集中,由於我們可以存取每個對話的多模式資料來源,我們假設它將改進上下文建模,從而有利於整體情緒識別效能。此資料集也可用於開發多模式情緒對話系統。 IEMOCAP、SEMAINE 是多模式會話資料集,其中包含每個話語的情緒標籤。然而,這些資料集本質上是二元的,這證明了我們的 Multimodal-EmotionLines 資料集的重要性。其他公開可用的多模態情緒和情緒辨識資料集是 MOSEI、MOSI、MOUD。然而,這些數據集都不是對話性的。
第一步涉及尋找 EmotionLines 資料集中每個對話中每個話語的時間戳記。為了實現這一目標,我們爬取了所有劇集的字幕文件,其中包含話語的開始和結束時間戳。這個過程使我們能夠獲取劇集 ID、劇集 ID 和劇集中每個話語的時間戳。我們在獲取時間戳時設定了兩個約束:(a)對話中話語的時間戳必須按升序排列,(b)對話中的所有話語必須屬於同一情節和場景。透過這兩個條件的約束發現,在 EmotionLines 中,少數對話由多個自然對話組成。我們從資料集中過濾掉了這些案例。由於這個糾錯步驟,在我們的例子中,與 EmotionLine 相比,我們有不同數量的對話。在獲得每個話語的時間戳後,我們從來源劇集中提取其對應的視聽片段。另外,我們也從這些影片片段中取出了音訊內容。最後,資料集包含每個對話的視覺、音訊和文字模式。
解釋該資料集的論文可以找到 - https://arxiv.org/pdf/1810.02508.pdf
請造訪 - http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz 下載原始資料。資料以 .mp4 格式存儲,可以在 XXX.tar.gz 檔案中找到。註解可以在 https://github.com/declare-lab/MELD/tree/master/data/MELD 中找到。
| 列名 | 描述 |
|---|---|
| 先生號 | 話語序號主要用於不同版本或多副本不同子集時引用話語 |
| 發聲 | 來自 EmotionLines 的個人話語作為字串。 |
| 揚聲器 | 與話語相關的說話者的名字。 |
| 情緒 | 說話者在言語中表達的情緒(中性、喜悅、悲傷、憤怒、驚訝、恐懼、厭惡)。 |
| 情緒 | 說話者在話語中表達的情緒(正向、中立、負向)。 |
| 對話ID | 對話索引從0開始。 |
| 話語ID | 對話中特定話語的索引,從 0 開始。 |
| 季節 | 季節號。特定話語所屬的《老友記》電視節目。 |
| 插曲 | 劇集號。該話語所屬特定季節的《老友記》電視節目。 |
| 開始時間 | 給定劇集中話語的開始時間,格式為「hh:mm:ss,ms」。 |
| 結束時間 | 給定劇集中話語的結束時間,格式為「hh:mm:ss,ms」。 |
有 13 個 pickle 文件,其中包含用於訓練基線模型的資料和特徵。以下是每個 pickle 檔案的簡要說明。
import pickle
data , W , vocab , word_idx_map , max_sentence_length , label_index = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_avg_emb , val_text_avg_emb , test_text_avg_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_CNN_emb , val_text_CNN_emb , test_text_CNN_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_emb , val_text_emb , test_text_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_bimodal_emb , val_bimodal_emb , test_bimodal_emb = pickle . load ( open ( filepath , 'rb' ))'./utils/' 中提供了 2 個 python 腳本:
為了進行實驗,所有標籤都表示為 one-hot 編碼,其索引如下:
對於情緒分類的基線,使用了以下類別權重。索引與上面提到的相同。類別權重:[4.0、15.0、15.0、3.0、1.0、6.0、3.0]。
請按照以下步驟運行基線 -
./data/pickles/baseline/baseline.py如下所示:python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]python baseline.py -classify Sentiment -modality text -trainpython baseline.py -h取得參數的幫助文字。./data/models/中。 如果您發現該資料集對您的研究有用,請引用以下論文
S. Poria、D. Hazarika、N. Majumder、G. Naik、E. Cambria、R. Mihalcea。 MELD:用於對話中情緒辨識的多模式多方資料集。 2019年亞冠。
Chen, SY, Hsu, CC, Kuo, CC 和 Ku, LW EmotionLines:多方對話的情感語料庫。 arXiv 預印本 arXiv:1802.08379 (2018)。
多模態 EmoryNLP 情緒檢測資料集是透過增強和擴展 EmoryNLP 情緒檢測資料集而創建的。它包含與 EmoryNLP 情緒檢測資料集中相同的對話實例,但它還包含音訊和視覺模式以及文字。多模態 EmoryNLP 資料集中存在《老友記》電視劇中的 800 多個對話和 9000 多個話語。多位發言者參與了對話。對話中的每句話都被標記為這七種情緒中的任何一種:中性、快樂、和平、強大、害怕、瘋狂和悲傷。註釋是從原始資料集中藉用的。
| 統計數據 | 火車 | 開發者 | 測試 |
|---|---|---|---|
| 模態# | {a,v,t} | {a,v,t} | {a,v,t} |
| # 獨特的單字 | 9,744 | 2,123 | 2,345 |
| 平均。話語長度 | 7.86 | 6.97 | 7.79 |
| 最大限度。話語長度 | 78 | 60 | 61 |
| 平均。每個場景的情緒數量 | 4.10 | 4.00 | 4.40 |
| 對話數量 | 第659章 | 89 | 79 |
| # 話語數 | 7551 | 第954章 | 第984章 |
| 發言者數量 | 250 | 46 | 48 |
| # 情緒轉變 | 4596 | 第575章 | 第653章 |
| 平均。話語的持續時間 | 5.55秒 | 5.46秒 | 5.27秒 |
| 火車 | 開發者 | 測試 | |
|---|---|---|---|
| 快樂 | 第1677章 | 205 | 217 |
| 瘋狂的 | 第785章 | 97 | 86 |
| 中性的 | 2485 | 第322章 | 288 |
| 和平 | 638 | 82 | 111 |
| 強大的 | 第551章 | 70 | 96 |
| 傷心 | 第474章 | 51 | 70 |
| 害怕的 | 第941章 | 127 | 116 |
該資料集的影片剪輯可以從此連結下載。註解檔案可以在 https://github.com/SenticNet/MELD/tree/master/data/emorynlp 中找到。有 3 個 .csv 檔案。這些 csv 檔案第一列中的每個條目都包含一個話語,可以在此處找到其相應的視訊剪輯。每個話語及其影片剪輯均按季號、集號、場景 ID 和話語 ID 進行索引。例如, sea1_ep2_sc6_utt3.mp4表示該剪輯對應於第 1 季的話語。 1,劇集編號。 2、scene_id 6和utterance_id 3。此索引與原始資料集一致。 .csv檔案和影片檔案依原始資料集分為訓練集、驗證集和測試集。註釋直接借用自原始 EmoryNLP 資料集(Zahiri 等人(2018))。
| 列名 | 描述 |
|---|---|
| 發聲 | 來自 EmoryNLP 的單一話語作為字串。 |
| 揚聲器 | 與話語相關的說話者的名字。 |
| 情緒 | 說話者在話語中表達的情緒(中性、快樂、平和、強大、害怕、瘋狂和悲傷)。 |
| 場景ID | 對話索引從0開始。 |
| 話語ID | 對話中特定話語的索引,從 0 開始。 |
| 季節 | 季節號。特定話語所屬的《老友記》電視節目。 |
| 插曲 | 劇集號。該話語所屬特定季節的《老友記》電視節目。 |
| 開始時間 | 給定劇集中話語的開始時間,格式為「hh:mm:ss,ms」。 |
| 結束時間 | 給定劇集中話語的結束時間,格式為「hh:mm:ss,ms」。 |
注意:由於字幕不一致,有一些話語我們無法找到開始和結束時間。此類言論已從資料集中刪除。然而,我們鼓勵用戶從原始資料集中找到相應的話語並為其生成影片剪輯。
如果您發現該資料集對您的研究有用,請引用以下論文
S.扎希里和JD Choi。使用基於序列的捲積神經網路對電視節目腳本進行情緒偵測。 AAAI 情緒內容分析研討會,AFFCON'18,2018。
S. Poria、D. Hazarika、N. Majumder、G. Naik、E. Cambria、R. Mihalcea。 MELD:用於對話中情緒辨識的多模式多方資料集。 2019年亞冠。


