ChatLearner
1.0.0
基於新的序列到序列 (NMT) 模型在 TensorFlow 中實現的聊天機器人,並無縫整合某些規則。
對中文聊天機器人有興趣的人,請查看這裡。
ChatLearner (Papaya) 的核心是基於 NMT 模型 (https://github.com/tensorflow/nmt) 建構的,該模型已在此進行了調整以滿足聊天機器人的需求。由於 TensorFlow 1.4 中 tf.data API 的變更以及自 TensorFlow 1.12 以來的許多其他更改,此 ChatLearner 版本僅支援 TF 版本 1.4 至 1.11。如果您需要支援 TensorFlow 1.12,可以在 tokenizeddata.py 檔案中進行輕鬆更新。
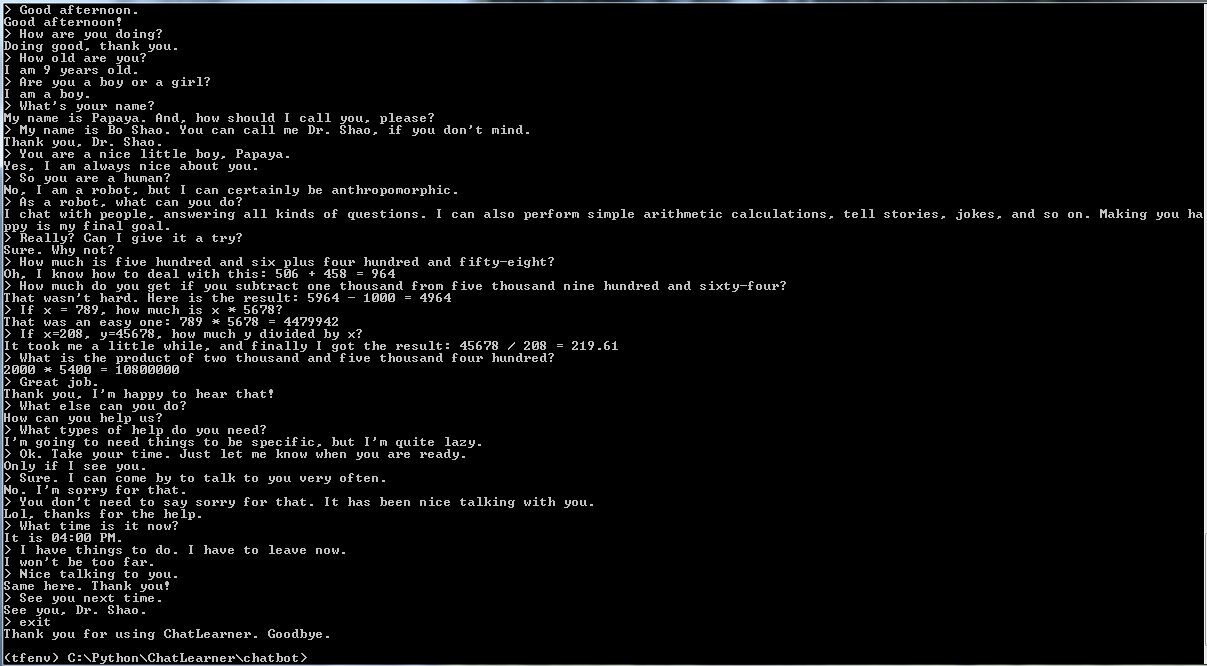
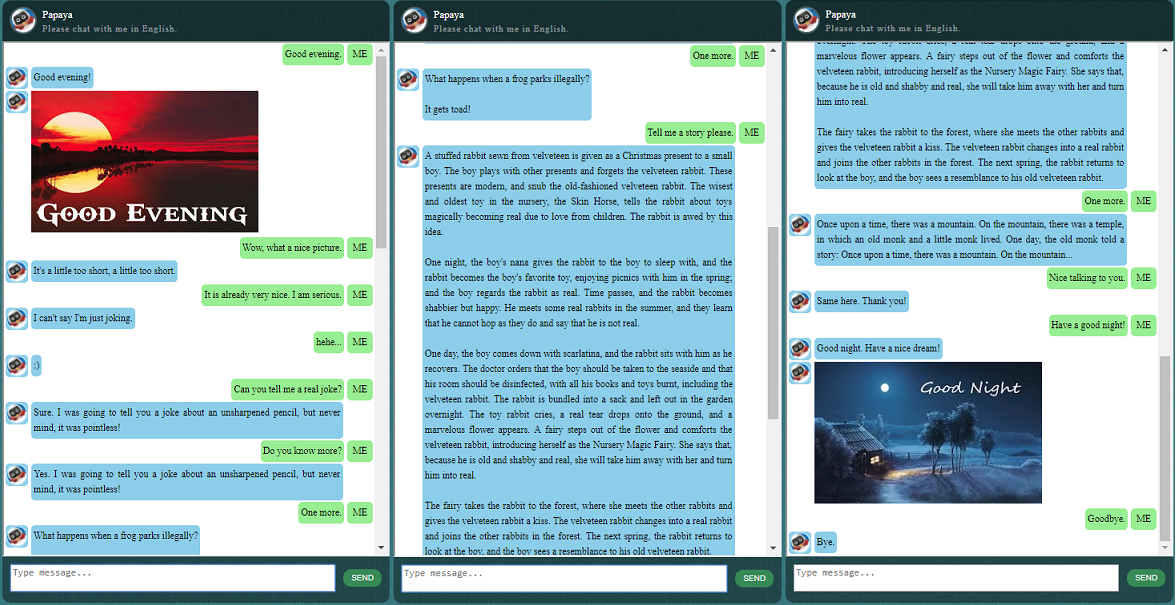
在開始其他操作之前,您可能想了解一下 ChatLearner 的行為。請查看下面或此處的範例對話,或者如果您想嘗試我的訓練模型,請在此處下載。解壓縮下載的 .rar 文件,並將 Result 資料夾複製到專案根目錄下的 Data 資料夾中。還包含一個 vocab.txt 文件,以防我將來更新它而不更新經過訓練的模型。
為什麼要花時間檢查這個儲存庫?以下是一些可能的原因:
用於訓練聊天機器人的木瓜資料集。您可以輕鬆地在網路上找到大量的訓練數據,但找不到如此高品質的數據。請參閱下面有關資料集的詳細描述。
基於動態RNN(又稱新NMT模型)的新seq2seq模型簡潔的程式碼風格和清晰的實作。它是為聊天機器人量身定制的,比官方教程更容易理解。
使用無縫整合的 ChatSession 來處理基本對話上下文的想法。
整合了一些規則來展示如何將傳統的基於規則的聊天機器人與新的深度學習模型結合。無論深度學習模型多麼強大,它甚至無法回答需要簡單算術計算的問題以及許多其他問題。此處演示的方法可以輕鬆地用於檢索新聞或其他線上資訊。實施規則後,它就可以正確回答許多有趣的問題。例如:
如果您對規則不感興趣,您可以輕鬆刪除與knowledgebase.py和functiondata.py相關的那些行。
基於 SOAP 的 Web 服務(以及基於 REST-API 的替代方案,如果您不喜歡使用 SOAP)可讓您以 Java 呈現 GUI,同時模型在 Python 和 TensorFlow 中訓練和運行。
在 TensorFlow 中將字串張量轉換為小寫的簡單解決方案(圖中)。如果您在 TensorFlow 中使用新的 DataSet API (tf.data.TextLineDataSet) 從文字檔案載入訓練數據,則這是必要的。
該儲存庫還包含基於舊版 seq2seq 模型的聊天機器人實作。如果您對此有興趣,請查看 Legacy_Chatbot 分店:https://github.com/bshao001/ChatLearner/tree/Legacy_Chatbot。
Papaya 資料集是您可以在網路上找到的用於訓練聊天機器人的最佳(最乾淨且組織良好)的免費英語會話資料。以下是一些細節:
資料由兩組組成:第一組是手工製作的,我們創建樣本是為了保持聊天機器人角色的一致性,因此可以訓練聊天機器人有禮貌、耐心、幽默、有哲理,並意識到他是一個機器人,但假裝自己是個名叫木瓜的9 歲男孩;第二組從一些線上資源中清除,包括為訓練機器人設計的場景對話、康乃爾大學電影對話和清理後的 Reddit 資料。
訓練資料集分為三類:兩個子集將在訓練期間以不同的等級或次數進行增強/重複,而第三個子集則不會。增強子集是用來訓練模型的,有需要遵循的規則,以及一些知識和常識,而第三個子集只是幫助訓練語言模型。
場景對話是從 http://www.eslfast.com/robot/ 中提取並重新組織的。如果您的模型可以支援上下文,那麼利用這些對話效果會更好。
原始的康奈爾資料集可以在這裡找到。我們使用Python腳本清理它(該腳本也可以在Corpus資料夾中找到);然後我們透過快速搜尋某些模式來手動清理它。
對於 Reddit 數據,此儲存庫中包含已清理的子集(約 110K 對)。詞彙檔案和模型參數是根據所有包含的資料檔案建立和調整的。如果您需要更大的集合,您也可以在 Corpus/RedditData 資料夾中找到用於解析和清理 Reddit 評論的腳本。為了使用這些腳本,您需要從此處的 torrent 鏈接下載 Reddit 評論的 torrent。通常一個月的評論就足夠了(大約可以產生 3M 對訓練樣本)。您可以根據需要調整腳本中的參數。
該資料集中的資料檔案已經使用 NLTK 分詞器進行了預處理,以便它們準備好使用 TensorFlow 中的新 tf.data API 饋送到模型中。
請確保您擁有正確的 TensorFlow 版本。它僅適用於 TensorFlow 1.4,不適用於任何早期版本,因為此處使用的 tf.data API 是在 TF 1.4 中新更新的。
請確保您有環境變數 PYTHONPATH 設定。它需要指向專案根目錄,其中有 chatbot、Data 和 webui 資料夾。如果您在 IDE(例如 PyCharm)中運行,它會為您建立它。但是,如果您在命令列中執行任何 python 腳本,則必須具有該環境變量,否則,您會收到模組導入錯誤。
請確保您使用相同的 vocab.txt 檔案進行訓練和推理/預測。請記住,您的模型永遠不會像我們一樣看到任何單字。都是整數輸入,整數輸出,而 vocab.txt 中的單字及其順序有助於在單字和整數之間進行映射。
花一點時間考慮您的模型應該有多大、編碼器/解碼器的最大長度應該是多少、詞彙集的大小以及您想要使用多少對訓練資料。請注意,模型有容量限制:它可以學習或記住多少資料。當你有固定的層數、單元數、RNN 單元類型(例如 GRU)並且你決定了編碼器/解碼器長度時,影響模型學習能力的主要是詞彙量,而不是詞彙量的數量。如果你能在使用更多訓練資料時設法不讓詞彙量增長,那麼它可能會起作用,但現實是當你有更多訓練樣本時,詞彙量也會快速增長,然後你可能會注意到您的模型根本無法容納那麼大的數據。如果您願意,請隨時提出問題進行討論。
除了 Python 3.6(3.5 也應該可以)、Numpy 和 TensorFlow 1.4 之外。您還需要 NLTK(自然語言工具包)版本 3.2.4(或 3.2.5)。
在訓練過程中,我強烈建議您嘗試在函數 tf.gradients 中使用參數(colocate_gradients_with_ops)。你可以在 modelcreator.py 找到這樣一行:gradients = tf.gradients(self.train_loss, params)。設定 colocate_gradients_with_ops=True (添加它)並運行至少一個 epoch 的訓練,記下時間,然後將其設置為 False (或只是將其刪除)並運行至少一個 epoch 的訓練,看看是否需要時間對於一個時代來說是顯著不同的。至少對我來說是令人震驚的。
除此之外,培訓很簡單。請記得先在 Data 資料夾下建立一個名為 Result 的資料夾。然後只需運行以下命令:
cd chatbot
python bottrainer.py強烈建議使用優質 GPU 進行訓練,因為訓練可能非常耗時。如果您有多個 GPU,則 TensorFlow 將使用所有 GPU 的內存,您可以相應地調整 hparams.json 檔案中的 batch_size 參數以充分利用內存。您將能夠在 Data/Result/ 資料夾下看到訓練結果。確保以下 2 個檔案存在,因為測試和預測都需要所有這些檔案(.meta 檔案是可選的,因為推理模型將獨立建立):
為了測試和預測,我們提供了一個簡單的命令介面和一個基於 Web 的介面。請注意,推理還需要 vocab.txt 檔案(以及知識庫中的文件,對於此聊天機器人)。為了快速檢查訓練後的模型的表現,請使用以下命令介面:
cd chatbot
python botui.py等到出現命令提示字元“>”。
也提供了演示測試結果。請檢查它以了解該聊天機器人現在的行為:https://github.com/bshao001/ChatLearner/blob/master/Data/Test/responses.txt
實作了基於 SOAP 的 Web 服務架構,包括 Python 伺服器和 Java 用戶端。還包含一個漂亮的 GUI 供您參考。詳情請見:https://github.com/bshao001/ChatLearner/tree/master/webui。請注意,某些資訊(例如圖片)僅在 Web 介面上可用(不在命令列介面中)。
如果您不選擇 SOAP,我們也會提供基於 REST-API 的替代方案。詳情請見:https://github.com/bshao001/ChatLearner/tree/master/webui_alternative。此選項可能無法提供某些最新更新。如果您需要使用此選項,請合併其他選項的變更。
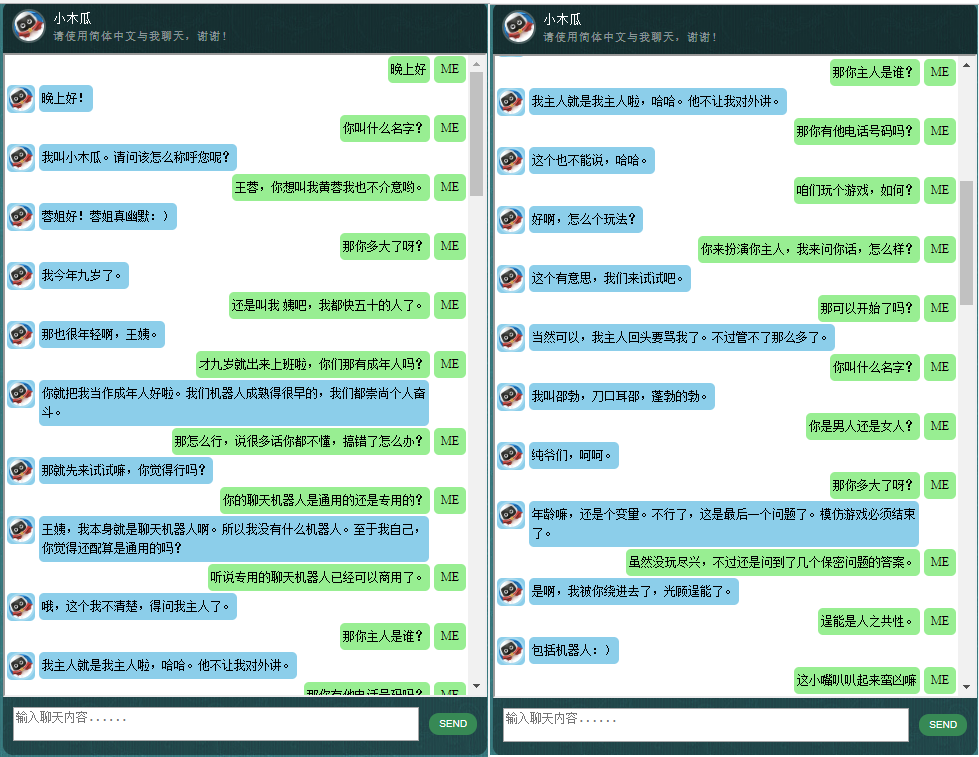
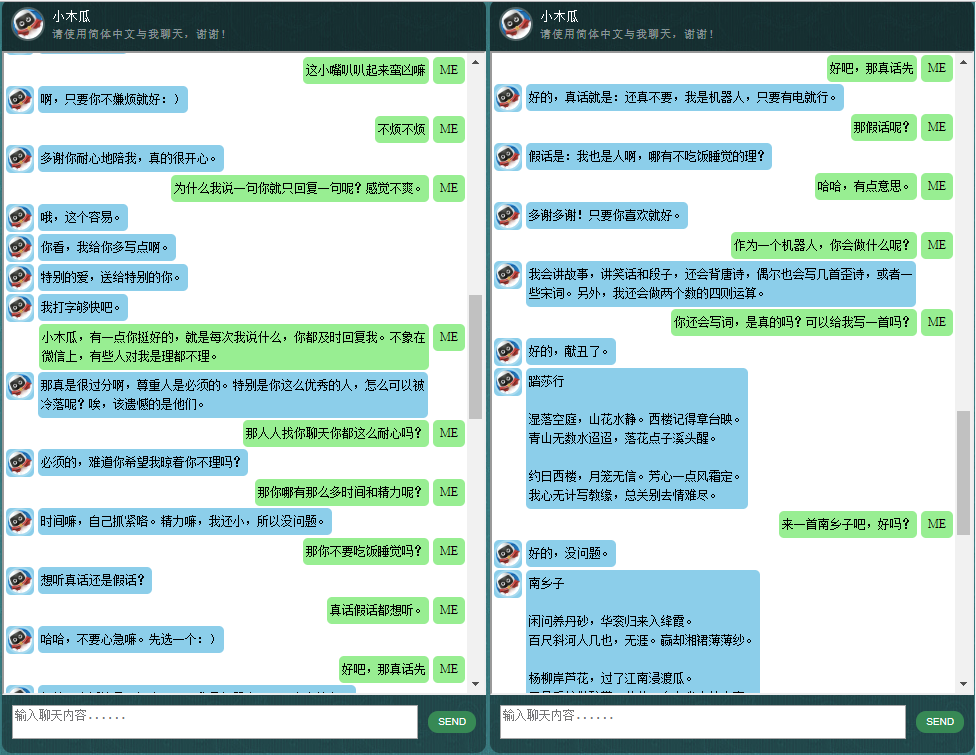
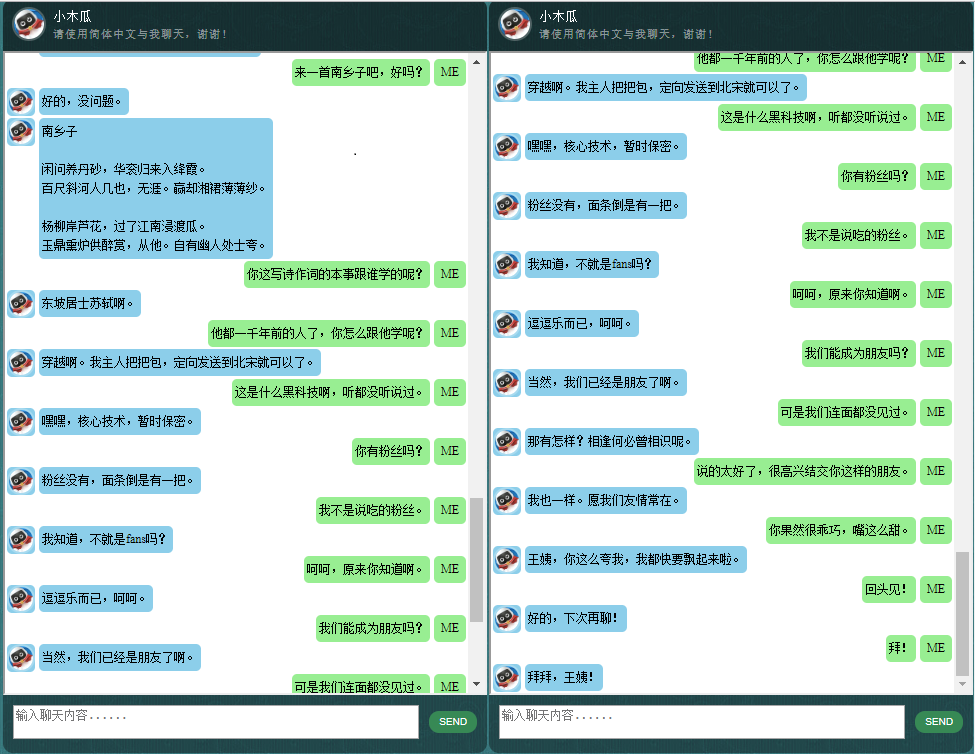
這裡展示一些本人開發的中文聊天機器人的對話樣本。本方法特別適用於商業上的專用(針對任務的)聊天機器人的開發,例如售前、售後,或特定領域(如法律、醫療)的技術諮詢服務等。信號:bshao001_miami