Dialog
1.0.0
Dialog是日本聊天機器人專案。
此專案中使用的架構是 EncoderDecoder 模型,具有 BERT Encoder 和 Transformer Decoder。
文章用日文寫的。
您可以在google colab上執行訓練和評估腳本,而無需建置環境。
請點擊以下連結。
請注意,在訓練筆記本中,註釋末尾描述了下載命令,但尚未測試。因此,如果您執行訓練筆記本並且無法下載訓練後的權重文件,請手動下載。
用日文寫的博客
@ycat3 透過使用該項目進行句子生成和用於語音合成的 Parallel Wavenet 創建了文字轉語音範例。原始碼不共享,但如果您利用 Parallel Wavenet,則可以重現它。該部落格有一些音訊樣本,所以請嘗試聽一下。
如果我有很多空閒時間,我想創建一個應用程序,允許我們透過語音合成和語音識別與人工智慧進行語音對話,但現在由於準備考試而無法做到這一點......
2個時期
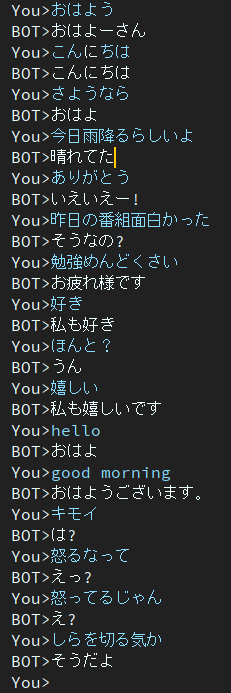
該模型仍然存在響應遲鈍的問題。
為了解決這個問題我現在正在研究。
然後我發現這篇論文解決了這個問題。
神經對話生成的另一種促進多樣性的目標函數
作者來自奈良科學技術研究所(又稱 NAIST)。
他們提出了神經對話生成的新目標函數。
我希望這個方法可以幫助我解決這個問題。
在谷歌驅動器中。
需要的包有
如果因軟體包原因而出現錯誤,請安裝缺少的軟體包。
例如,如果您使用 conda。
# create new environment
$ conda create -n dialog python=3.7
# activate new environment
$ activate dialog
# install pytorch
$ conda install pytorch torchvision cudatoolkit={YOUR_VERSION} -c pytorch
# install rest of depending package except for MeCab
$ pip install transformers tqdm neologdn emoji
# #### Already installed MeCab #####
# ## Ubuntu ###
$ pip install mecab-python3
# ## Windows ###
# check that "path/to/MeCab/bin" are added to system envrionment variable
$ pip install mecab-python-windows
# #### Not Installed MeCab #####
# install Mecab in accordance with your OS.
# method described in below is one of the way,
# so you can use your way if you'll be able to use transformers.BertJapaneseTokenizer.
# ## Ubuntu ###
# if you've not installed MeCab, please execute following comannds.
$ apt install aptitude
$ aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
$ pip install mecab-python3
# ## Windows ###
# Install MeCab from https://github.com/ikegami-yukino/mecab/releases/tag/v0.996
# and add "path/to/Mecab/bin" to system environment variable.
# then run the following command.
$ pip install mecab-python-windows # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_training_data'如果您準備好開始訓練,請執行主腳本。
$ python main.py # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_pretrained'$ python run_eval.py如果您想獲取更多對話數據,請使用 get_tweet.py
請注意,您必須更改consumer_key和access_token才能使用此腳本。
然後,執行以下命令。
# usage
$ python get_tweet.py " query " " Num of continuous utterances "
# Example
# This command works until occurs errors
# and makes a file named "tweet_data_私は_5.txt" in "./data"
$ python get_tweet.py 私は 5如果執行範例指令,如果最後一句包含“私は”,腳本將開始收集連續 5 個句子。
但是,您將 3 個或更多數字設為“連續話語”,make_training_data.py 會自動建立一對話語。
然後執行以下命令。
$ python make_training_data.py腳本使用“./data/tweet_data_*.txt”製作訓練數據,就像名稱一樣。
編碼器:BERT
解碼器:Vanilla Transformer 的解碼器
損失:交叉熵
優化器:AdamW
分詞器:Bert JapaneseTokenizer
如果您想了解更多有關 BERT 或 Transformer 架構的信息,請參閱以下文章。


