turing
v0.3.8
Viglet Turing ES(https://openviglet.github.io/turing/)是開源解決方案(https://github.com/openturing),其主要功能是語義導航和聊天機器人。您可以從多個 NLP 中進行選擇來豐富資料。所有內容都在 Solr 作為搜尋引擎中建立索引。
有關 Turing ES 的技術文件可在 https://openviglet.github.io/docs/turing/ 取得。
要運行 Turing ES,只需執行以下幾行:
# Turing Appmvn -Dmaven.repo.local=D:repo spring-boot:run -pl turing-app -Dskip.npm# 使用 Angular 18 和 Primer CSS 的新 Turing ES UI.cd turing-ui## 歡迎登入### Consoleng 服務console## Searchng 服務sn## 聊天botng 服務converse
您可以使用 MariaDB、Solr 和 Nginx 啟動 Turing ES。
docker-compose up
管理控制台:http://localhost:2700。 (管理員/管理員)
語意導覽範例:http://localhost:2700/sn/Sample。
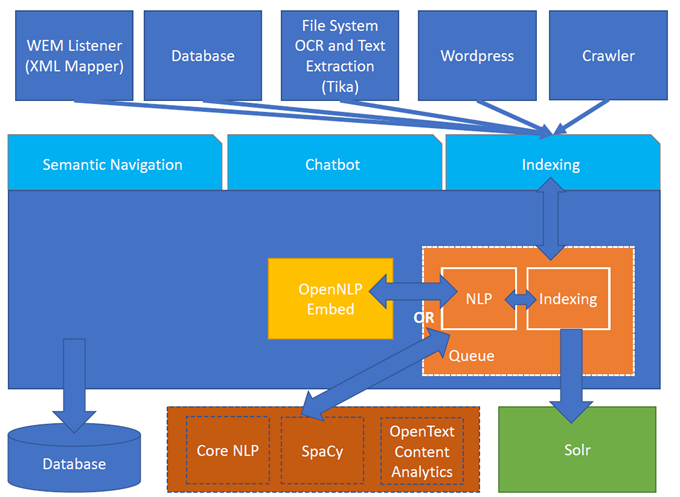
圖 1. Turing ES 架構
圖靈支持以下提供者:
Apache OpenNLP 是一個基於機器學習的工具包,用於處理自然語言文字。
網址:https://opennlp.apache.org/
它將數據轉化為見解,以實現更好的決策和資訊管理,同時釋放資源和時間。
網址:https://www.opentext.com/
CoreNLP 是您使用 Java 進行自然語言處理的一站式商店! CoreNLP 使用戶能夠匯出文字的語言註釋,包括標記和句子邊界、詞性、命名實體、數字和時間值、依賴和選區解析、共指、情緒、引用歸因和關係。 CoreNLP目前支援6種語言:阿拉伯語、中文、英語、法語、德語和西班牙語。
網址:https://stanfordnlp.github.io/CoreNLP/,
它是一個用於 Python 自然語言處理的免費開源程式庫。它具有 NER、POS 標記、依存分析、詞向量等功能。
網址:https://spacy.io
Polyglot 是一種支援大規模多語言應用程式的自然語言管道。
網址:https://polyglot.readthedocs.io
它可以讀取 PDF 和文件並轉換為純文本,還可以使用 OCR 檢測圖像中的文本以及將圖像轉換為文件。
語意導航使用連接器對來自多個來源的內容進行索引。
Apache Nutch 的插件,用於使用爬蟲索引內容。
了解更多信息,請訪問 https://docs.viglet.com/turing/connectors/#nutch
使用與 sqoop (https://sqoop.apache.org/) 相同概念的命令列來建立複雜查詢並根據結果將屬性對應到索引。
了解更多信息,請訪問 https://docs.viglet.com/turing/connectors/#database
命令列索引文件,透過 OCR 從 Word、Excel、PDF(包括圖像)等文件中提取文字。
了解更多信息,請訪問 https://docs.viglet.com/turing/connectors/#file-system
OpenText WEM Listener,用於將內容發佈到 Viglet Turing。
了解更多信息,請訪問 https://docs.viglet.com/turing/connectors/#wem
WordPress 外掛程式可讓您為貼文建立索引。
了解更多信息,請訪問 https://docs.viglet.com/turing/connectors/#wordpress
透過 NLP,可以檢測以下實體:
人們
地點
組織機構
錢
時間
百分比
定義將用作導航過濾器的屬性,整合顯示中的全部內容
透過內容中定義的屬性,可以使用它們根據使用者的設定檔限制其顯示。
Java API (https://github.com/openturing/turing-java-sdk) 方便了 Viglet Turing ES 的使用和訪問,無需消費者透過複雜的查詢來搜尋內容。
與您的客戶溝通並闡述複雜的意圖,取得報告並逐步發展您的互動。
其組成部分:
處理與最終用戶的對話。它是一個自然語言處理模組,可以理解人類語言的細微差別
意圖將最終使用者進行對話轉移的意圖進行分類。對於每個代理,您定義多個意圖,其中組合的意圖可以處理完整的對話。
操作字段是一個簡單的方便字段,有助於執行服務中的邏輯。
每個意圖參數都有一個類型,稱為實體類型,它準確地指示如何提取最終使用者表達式中的資料。
定義並糾正意圖。
顯示對話歷史記錄和報表。
Turing ES 使用 OCR 和 NLP 檢測 OpenText Blazon 文件的實體,產生 Blazon XML 以將實體顯示到文件中。
Turing ES 有許多元件:搜尋引擎、NLP、Converse(聊天機器人)、語意導航
造訪Turing ES時,會出現登入頁面。預設情況下,登入名稱/密碼是admin / admin
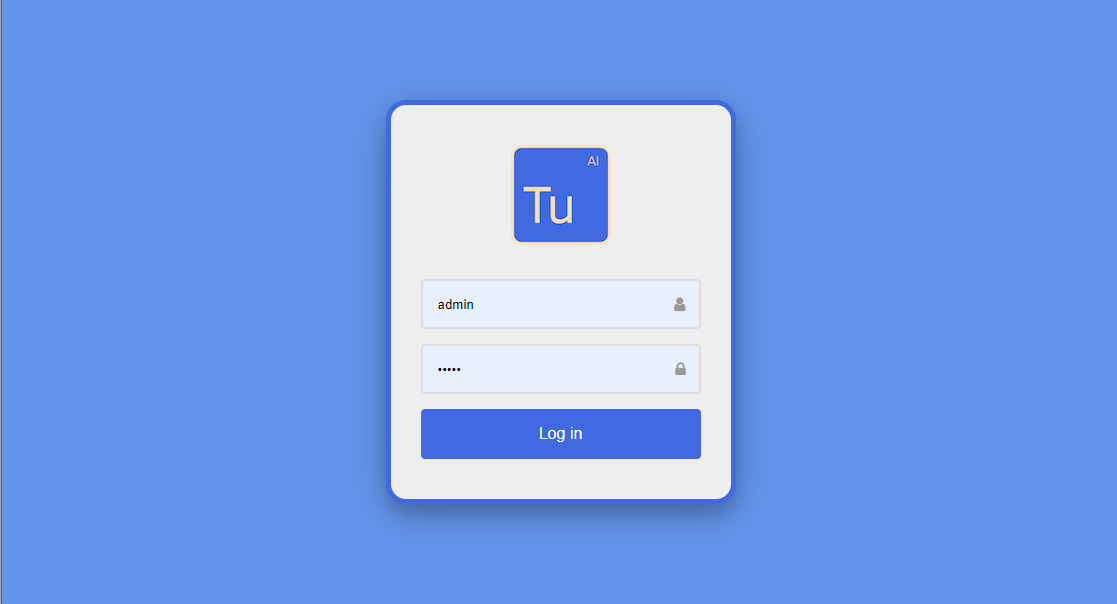
圖 2. 登入頁面
Turing 使用搜尋引擎來儲存和檢索 Converse(聊天機器人)和語義導航網站的資料。
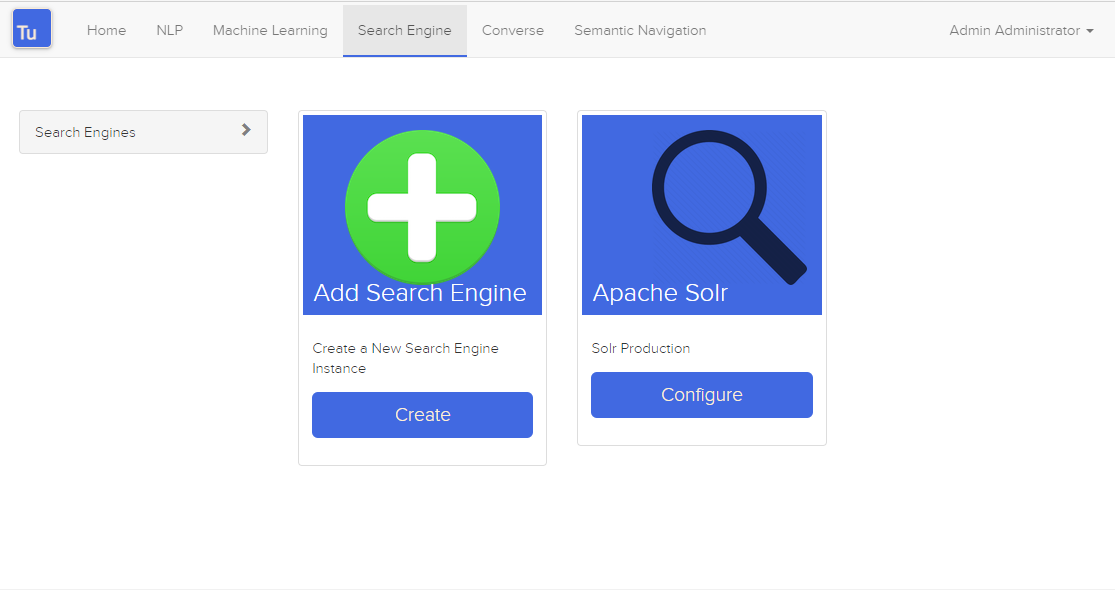
圖 3. 搜尋引擎頁面
可以建立或編輯具有以下屬性的搜尋引擎:
| 屬性 | 描述 |
|---|---|
姓名 | 搜尋引擎名稱 |
描述 | 搜尋引擎說明 |
小販 | 選擇搜尋引擎的供應商。目前,它僅支援 Solr。 |
主持人 | 安裝搜尋引擎服務的主機名 |
港口 | 搜尋引擎服務端口 |
語言 | 搜尋引擎服務的語言。 |
啟用 | 如果搜尋引擎已啟用。 |
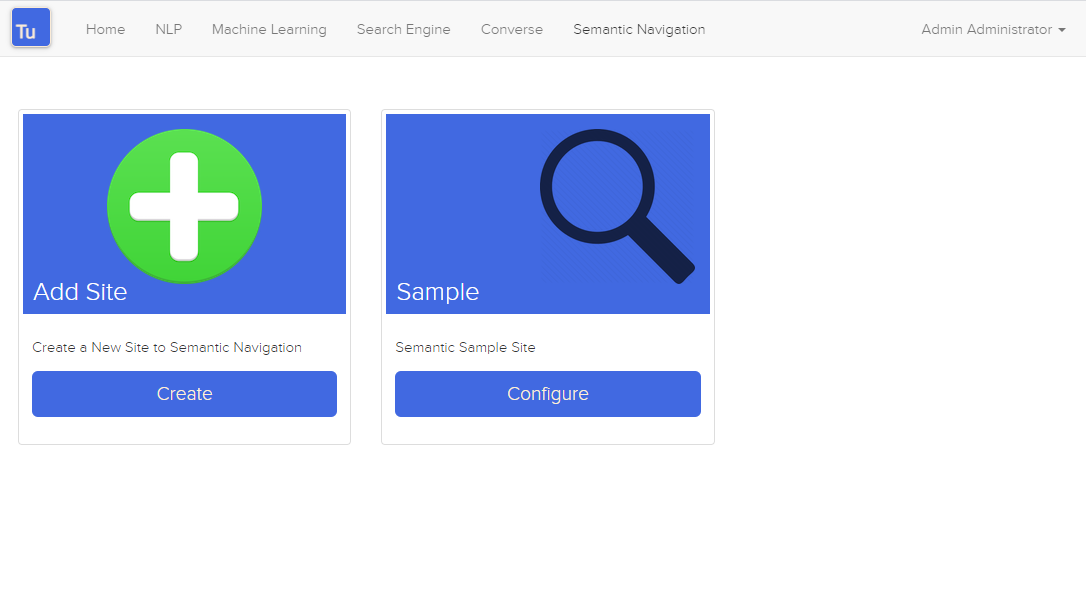
圖 4. 語意導覽頁面
語義導航網站的詳細資訊包含以下屬性:
| 屬性 | 描述 |
|---|---|
姓名 | 語義導航網站的名稱。 |
描述 | 語義導航站點的描述。 |
搜尋引擎 | 選擇在搜尋引擎部分中建立的搜尋引擎。語義導航網站將使用該搜尋引擎來儲存和檢索資料。 |
自然語言處理 | 選擇在 NLP 部分中建立的 NLP。語意導覽網站將使用此 NLP 在索引期間偵測實體。 |
同義詞庫 | 如果您使用同義詞庫。 |
語言 | 語義導航網站的語言。 |
核 | 將儲存和檢索資料的搜尋引擎核心的名稱。 |
欄位標籤包含一個包含以下列的表格: .語意導覽網站欄位列
| 列名 | 描述 |
|---|---|
類型 | 字段類型。它可以是: - NLP 使用的 NER(命名實體辨識)。 - Solr 使用的搜尋引擎。 |
場地 | 字段名稱。 |
啟用 | 該字段是否啟用。 |
MLT | 如果該欄位將在 MLT 中使用。 |
刻面 | 將此欄位用作構面(過濾器) |
突出顯示 | 如果該欄位將顯示突出顯示的行。 |
自然語言處理 | 該欄位是否由 NLP 處理以檢測實體 (NER),例如人員、組織和地點。 |
按一下欄位時,會出現一個新頁面,其中包含具有以下屬性的欄位詳細資訊:
| 屬性 | 描述 |
|---|---|
姓名 | 欄位名稱 |
描述 | 字段描述 |
類型 | 字段類型。它可以是: |
多值 | 如果是數組 |
構面名稱 | 搜尋頁面上構面(過濾器)的標籤名稱。 |
刻面 | 將此欄位用作構面(過濾器) |
突出顯示 | 如果該欄位將顯示突出顯示的行。 |
MLT | 如果該欄位將在 MLT 中使用。 |
啟用 | 如果該欄位已啟用。 |
必需的 | 如果需要該欄位。 |
預設值 | 如果內容在沒有這些欄位的情況下被索引,那就是預設值。 |
自然語言處理 | 該欄位是否由 NLP 處理以檢測實體 (NER),例如人員、組織和地點。 |
包含以下屬性:
| 部分 | 屬性 | 描述 |
|---|---|---|
外貌 | 每頁的項目數 | 將出現在搜尋中的項目數。 |
刻面 | 啟用方面? | 如果它將在搜尋中顯示 Facet(過濾器)。 |
每個方面的項目數 | 將出現在每個方面(過濾器)中的項目數。 | |
突出顯示 | 突出顯示已啟用? | 定義是否顯示突出顯示的行。 |
預標籤 | 將在學期開始時使用的 HTML 標籤。例如:<標記> | |
發布標籤 | 將在學期結束時使用的 HTML 標籤。例如:</標記> | |
MLT | 啟用更多類似功能? | 定義是否顯示MLT |
預設字段 | 標題 | 將用作 Solr schema.xml 中定義的標題的字段 |
文字 | 將用作 Solr schema.xml 中定義的標題的字段 | |
描述 | 將用作 Solr schema.xml 中定義的描述的字段 | |
日期 | 將用作 Solr schema.xml 中定義的日期的字段 | |
影像 | 將用作 Solr schema.xml 中定義的圖像 URL 的字段 | |
網址 | 將用作 Solr schema.xml 中定義的 URL 的字段 |
在Turing ES Console > Semantic Navigation > <SITE_NAME>中,按Configure按鈕,然後按Search Page按鈕。
它將開啟一個使用以下模式的搜尋頁面:
取得 http://localhost:2700/sn/<SITE_NAME>
此頁面透過 AJAX 請求 Turing Rest API。例如,以 JSON 格式傳回語意導覽網站的所有結果:
取得 http://localhost:2700/api/sn/<SITE_NAME>/search?p=1&q=*&sort=relevance
| 屬性 | 必需/可選 | 描述 | 例子 |
|---|---|---|---|
q | 必需的 | 搜尋查詢。 | q=foo |
p | 必需的 | 頁碼,第一頁為 1。 | p=1 |
種類 | 必需的 | 排序值: | 排序=相關性 |
fq[] | 選修的 | 查詢字段。使用下列模式按欄位過濾: FIELD : VALUE 。 | fq[]=標題:欄 |
tr[] | 選修的 | 目標規則。限制搜尋基於: FIELD : VALUE 。 | tr[]=部門:foobar |
列 | 選修的 | 查詢將傳回的行數。 | 行=10 |
在保險公司的內部網路上,使用 OpenText WEM 和與動態入口網站模組整合的 OpenText Portal,使用連接器:WEM、具有檔案系統的資料庫在 Viglet Turing ES 中建立綜合搜尋。透過這種方式,可以顯示搜尋內部網路的所有內容和文件,並具有定向規則,只允許顯示使用者有權存取的內容。 OpenText Portal 存取 Viglet Turing ES Java API,因此無需建立複雜的查詢來傳回結果。
創建了一組 API Rest,以使所有政府公司內容可供合作夥伴使用。所有這些內容都在 OpenText WEM 中,並使用 WEM 連接器在 Viglet Turing ES 上對內容進行索引。 Spring Boot 應用程式是使用 Rest API 集創建的,該應用程式透過 Viglet Turing ES Java API 使用 Turing ES 內容。
巴西大學網站是使用Viglet Shio CMS (https://viglet.com/shio)開發的,所有內容都在Viglet Turing ES中自動索引。此配置是在內容建模中進行的,搜尋模板的開發是在 Viglet Shio CMS 中進行的。


