GenDataAttribution
1.0.0
項目|紙
王勝宇1 , Alexei A. Efros 2 , 朱俊彥1 , 張理查3 .
卡內基美隆大學1 , 加州大學柏克萊分校2 , Adobe 研究中心2
在 ICCV,2023 年。
雖然大型文字到圖像模型能夠合成「新」圖像,但這些圖像必然是訓練資料的反映。此類模型中的資料歸因問題(訓練集中的哪些圖像對給定生成圖像的外觀負有最大責任)是一個困難但重要的問題。作為解決這個問題的第一步,我們透過「客製化」方法評估歸因,該方法將現有的大規模模型調整為給定的範例物件或風格。我們的主要見解是,這使我們能夠有效地創建合成圖像,這些圖像在計算上受到構造範例的影響。利用此類受樣本影響的影像的新資料集,我們能夠評估各種資料歸因演算法和不同的可能特徵空間。此外,透過對我們的資料集進行訓練,我們可以針對歸因問題調整標準模型,例如 DINO、CLIP 和 ViT。儘管該過程針對小型樣本集進行了調整,但我們仍展示了對較大樣本集的泛化。最後,透過考慮問題固有的不確定性,我們可以在一組訓練影像上分配軟歸因分數。
conda env create -f environment.yaml
conda activate gen-attr # Download precomputed features of 1M LAION images
bash feats/download_laion_feats.sh
# Download jpeg-ed 1M LAION images for visualization
bash dataset/download_dataset.sh laion_jpeg
# Download pretrained models
bash weights/download_weights.sh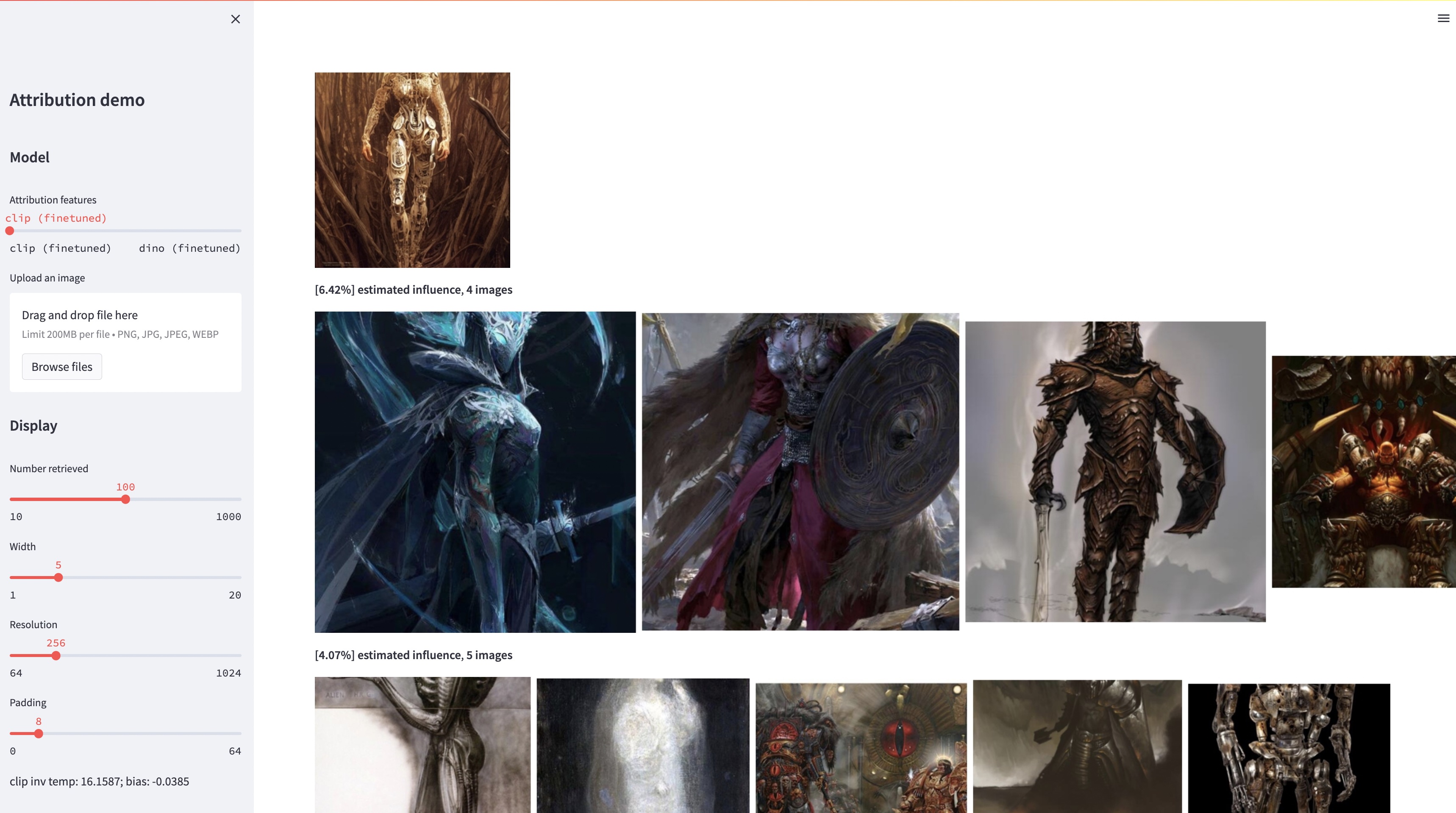
streamlit run streamlit_demo.py我們發布測試集進行評估。下載資料集:
# Download the exemplar real images
bash dataset/download_dataset.sh exemplar
# Download the testset portion of images synthesized from Custom Diffusion
bash dataset/download_dataset.sh testset
# (Optional, can download precomputed features instead!)
# Download the uncompressed 1M LAION subset in pngs
bash dataset/download_dataset.sh laion資料集的結構如下:
dataset
├── exemplar
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── synth
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── laion_subset
└── json
├──test_artchive.json
├──test_bamfg.json
├──...
所有範例影像儲存在dataset/exemplar中,所有合成影像儲存在dataset/synth中,png 格式的 1M laion 影像儲存在dataset/laion_subset中。 dataset/json中的 JSON 檔案指定訓練/驗證/測試分割,包括不同的測試案例,並用作真實標籤。 JSON 檔案中的每個條目都是獨特的微調模型。條目還記錄用於微調的範例影像以及模型生成的合成影像。我們有四個測試案例: test_artchive.json 、 test_bamfg.json 、 test_observed_imagenet.json和test_unobserved_imagenet.json 。
下載測試集、預先計算的 LAION 特徵和預訓練權重後,我們可以透過執行extract_feat.py來預計算測試集中的特徵,然後透過執行eval.py評估效能。以下是批量運行評估的 bash 腳本:
# precompute all features from the testset
bash scripts/preprocess_feats.sh
# run evaluation in batches
bash scripts/run_eval.sh指標儲存在results中的.pkl檔案中。目前,該腳本按順序運行每個命令。請隨意修改它以並行運行命令。下列指令會將.pkl檔解析為儲存為.csv檔的表:
python results_to_csv.py 12/18/2023 更新要下載僅在以物件為中心或以樣式為中心的模型上訓練的模型,請執行bash weights/download_style_object_ablation.sh
@inproceedings{wang2023evaluating,
title={Evaluating Data Attribution for Text-to-Image Models},
author={Wang, Sheng-Yu and Efros, Alexei A. and Zhu, Jun-Yan and Zhang, Richard},
booktitle={ICCV},
year={2023}
}
我們感謝 Aaron Hertzmann 閱讀早期草稿並提供富有洞察力的回饋。我們感謝 Adobe Research 的同事,包括 Eli Shechtman、Oliver Wang、Nick Kolkin、Taesung Park、John Collomosse 和 Sylvain Paris,以及 Alex Li 和 Yonglong Tian 的有益討論。我們感謝 Nupur Kumari 對自訂擴散訓練的指導,感謝 Ruihan Taka 校對草稿,感謝 Alex Li 提供提取穩定擴散特徵的指導,感謝 Dan Ruta 在 BAM-FG 資料集方面提供協助。我們感謝布萊恩·拉塞爾 (Bryan Russell) 進行流行病徒步旅行和集思廣益。這項工作是在 SYW 擔任 Adobe 實習生時開始的,並得到了 Adobe 捐贈和摩根大通教員研究獎的部分支持。


