amazon bedrock rag
1.0.0
檢索增強生成(RAG)是優化大型語言模型輸出的過程,因此它在產生回應之前引用訓練資料來源之外的權威知識庫。大型語言模型 (LLM) 經過大量資料訓練,並使用數十億個參數為回答問題、翻譯語言和完成句子等任務產生原始輸出。 RAG 將法學碩士本已強大的功能擴展到特定領域或組織的內部知識庫,而無需重新訓練模型。這是一種提高 LLM 輸出的經濟有效的方法,因此它在各種情況下都保持相關性、準確性和有用性。在此了解有關 RAG 的更多資訊。
Amazon Bedrock 是一項完全託管的服務,透過單一 API 提供來自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等領先 AI 公司的高效能基礎模型 (FM) 以及廣泛的一組構建具有安全性、隱私性和負責任的人工智慧的生成式人工智慧應用所需的功能。使用 Amazon Bedrock,您可以輕鬆地針對您的使用案例試驗和評估頂級 FM,使用微調和 RAG 等技術使用您的資料私下自訂它們,並建立使用您的企業系統和資料來源執行任務的代理程式。由於 Amazon Bedrock 是無伺服器的,因此您無需管理任何基礎設施,並且可以使用您已經熟悉的 AWS 服務將生成式 AI 功能安全地整合和部署到您的應用程式中。
Amazon Bedrock 知識庫是一項完全託管的功能,可協助您實施從擷取到擷取和提示增強的整個 RAG 工作流程,而無需建立與資料來源的自訂整合和管理資料流。內建會話上下文管理,因此您的應用程式可以輕鬆支援多輪對話。
作為創建知識庫的一部分,您可以配置您選擇的資料來源和向量儲存。資料來源連接器可讓您將專有資料連接到知識庫。配置資料來源連接器後,您可以將資料與知識庫同步或保持最新,並使資料可供查詢。 Amazon Bedrock 首先將您的文件或內容拆分為可管理的區塊,以實現高效的資料檢索。然後將區塊轉換為嵌入並寫入向量索引(資料的向量表示),同時維護到原始文件的對應。向量嵌入允許在數學上比較文字的相似性。
該專案使用兩個資料來源實施;一個資料來源用於儲存在 Amazon S3 中的文檔,另一個資料來源用於儲存在網站上發布的內容。在 Amazon OpenSearch Serverless 中建立向量搜尋集合以進行向量儲存。
問答聊天機器人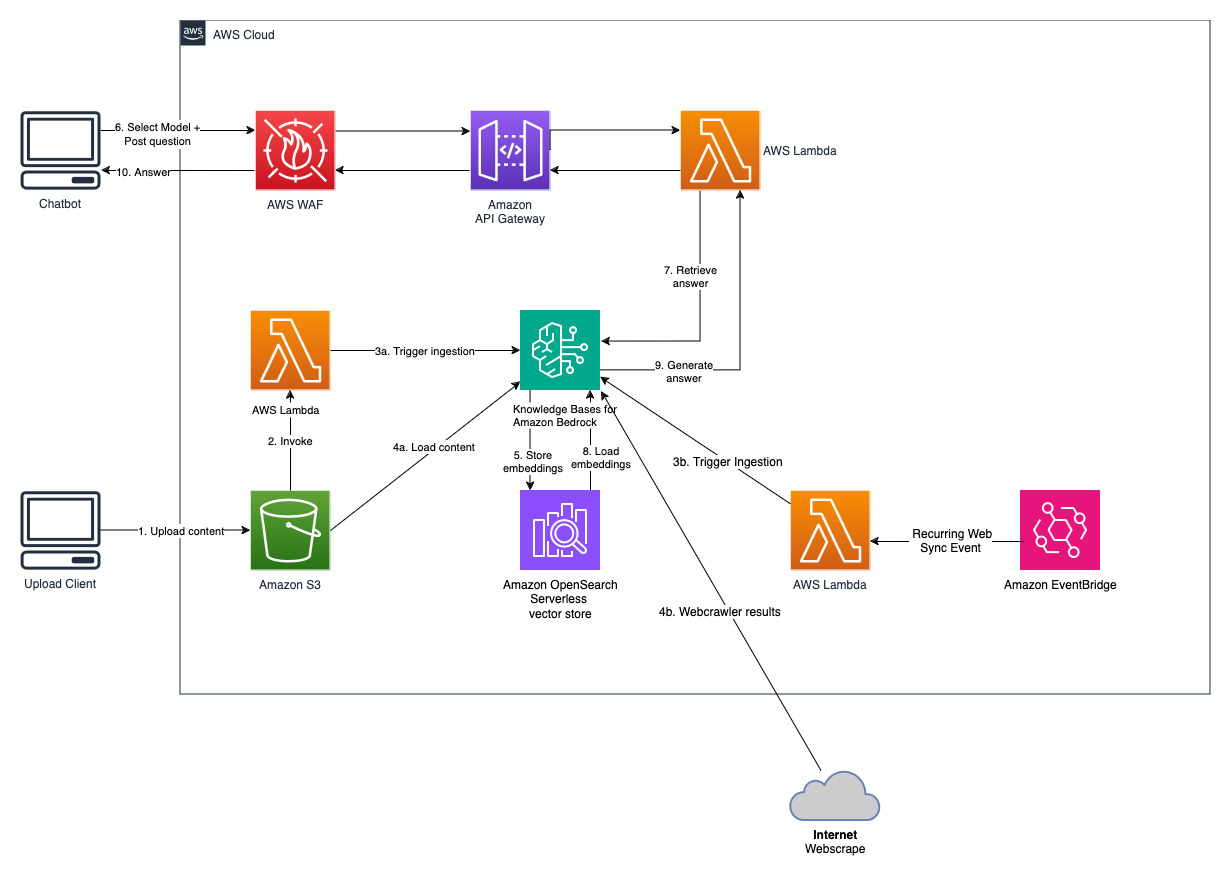
為 Web 資料來源新增網站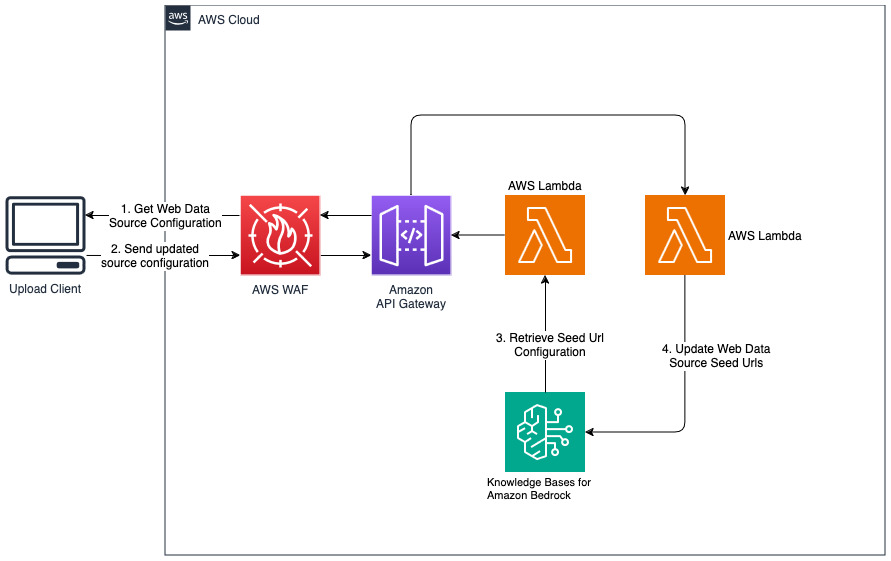
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
提供允許以 CIDR 格式存取 API 閘道的用戶端 IP 位址,作為「allowedip」上下文變數的一部分。
部署完成後,
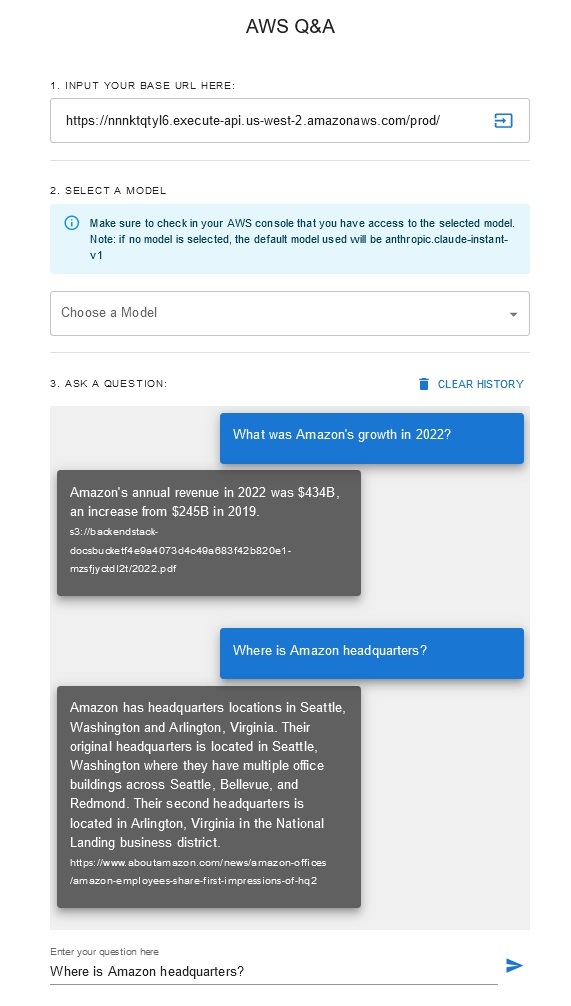
該解決方案允許使用者在檢索和生成階段選擇他們想要使用的基礎模型。預設模型是Anthropic Claude Instant 。對於知識庫嵌入模型,此解決方案使用Amazon Titan Embeddings G1 - 文字模型。確保您有權存取這些基礎模型。
取得最近公開發布的 Amazon 年度報告,並將其複製到前面提到的 S3 儲存桶名稱中。為了進行快速測試,您可以使用 AWS S3 主控台複製 Amazon 的 2022 年年度報告。 S3 儲存桶中的內容將自動與知識庫同步,因為解決方案部署會監視 S3 儲存桶中的新內容並觸發攝取工作流程。
部署的解決方案使用 URL https://www.aboutamazon.com/news/amazon-offices初始化名為「WebCrawlerDataSource」的 Web 資料來源。您需要手動將此 Web 爬網程式資料來源與 AWS 主控台中的知識庫同步,以搜尋網站內容,因為網站擷取計畫在將來進行。從基於 Amazon Bedrock 的知識控制台中選擇此資料來源並啟動「同步」操作。有關詳細信息,請參閱將您的資料來源與 Amazon Bedrock 知識庫同步。請注意,只有同步完成後,問答聊天機器人才可以使用網站內容。將網站設定為資料來源時,請使用本指南。
使用“cdk destroy”刪除在此解決方案部署中建立的雲端資源堆疊。


