EasyNLU
1.0.0
EasyNLU 是一個用 Java 編寫的用於行動應用程式的自然語言理解 (NLU) 函式庫。基於語法,它非常適合狹窄但需要嚴格控制的領域。
該專案有一個示例 Android 應用程序,可以透過自然語言輸入安排提醒:
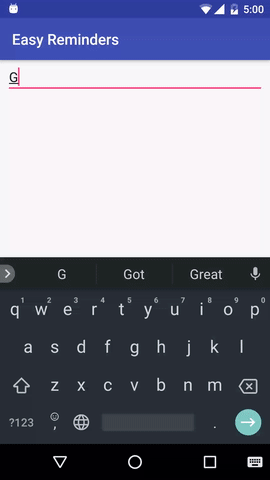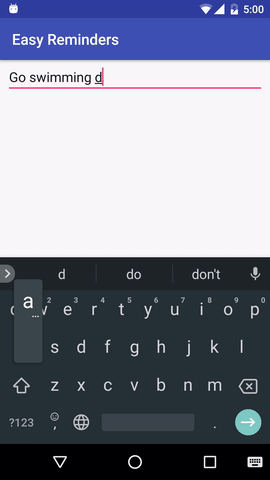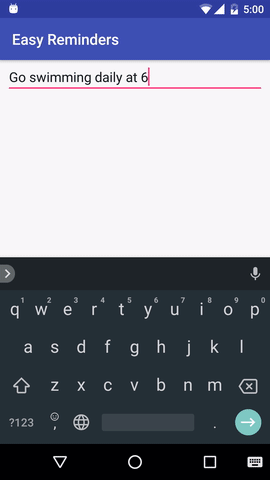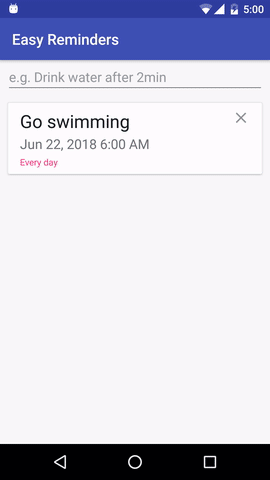
EasyNLU 在 Apache 2.0 下獲得許可。
EasyNLU 的核心是一個基於 CCG 的語意解析器。可以在這裡找到關於語義解析的很好的介紹。語義解析器可以解析輸入,如下所示:
明天下午5點去看牙醫
轉化為結構化形式:
{task: "Go to the dentist", startTime:{offset:{day:1}, hour:5, shift:"pm"}}
EasyNLU 提供結構化形式作為遞歸 Java 映射。然後可以將該結構化形式解析為「執行」的任務特定物件。例如,在範例專案中,結構化表單被解析為Reminder對象,該物件具有task 、 startTime和repeat等字段,並用於透過 AlarmManager 服務設定警報。
一般來說,以下是設定 NLU 功能的進階步驟:
在編寫任何規則之前,我們應該定義任務的範圍和結構化表單的參數。作為一個玩具範例,假設我們的任務是開啟和關閉藍牙、Wifi 和 GPS 等手機功能。所以這些字段是:
一個範例結構化形式是:
{feature: "bluetooth", action: "enable" }
此外,使用一些範例輸入來理解差異也很有幫助:
繼續這個玩具範例,我們可以說在頂層我們有一個設定操作,它必須具有一個功能和一個操作。然後我們使用規則來捕獲這些資訊:
Rule r1 = new Rule ( "$Setting" , "$Feature $Action" );
Rule r2 = new Rule ( "$Setting" , "$Action $Feature" );規則至少包含 LHS 和 RHS。按照慣例,我們在單字前面加上「$」來指示類別。類別代表單字或其他類別的集合。在上面的規則中, $Feature代表諸如藍牙、bt、wifi 等我們使用「詞彙」規則捕獲的單字:
List < Rule > lexicals = Arrays . asList (
new Rule ( "$Feature" , "bluetooth" ),
new Rule ( "$Feature" , "bt" ),
new Rule ( "$Feature" , "wifi" ),
new Rule ( "$Feature" , "gps" ),
new Rule ( "$Feature" , "location" ),
);為了標準化特徵名稱的變化,我們將$Features建構成子特徵:
List < Rule > featureRules = Arrays . asList (
new Rule ( "$Feature" , "$Bluetooth" ),
new Rule ( "$Feature" , "$Wifi" ),
new Rule ( "$Feature" , "$Gps" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" )
); $Action的相似之處:
List < Rule > actionRules = Arrays . asList (
new Rule ( "$Action" , "$EnableDisable" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" ),
new Rule ( "$EnableDisable" , "$Enable" ),
new Rule ( "$EnableDisable" , "$Disable" ),
new Rule ( "$OnOff" , "on" ),
new Rule ( "$OnOff" , "off" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
);注意“?”在第三條規則中;這意味著類別$Switch是可選的。為了確定解析是否成功,解析器會尋找稱為根類別的特殊類別。按照慣例,它表示為$ROOT 。我們需要新增一條規則來達到此類別:
Rule root = new Rule ( "$ROOT" , "$Setting" );有了這些規則集,我們的解析器應該能夠解析上面的範例,將它們轉換成所謂的語法樹。
如果我們無法提取句子的意思,那麼解析就沒有用。這種含義由結構化形式(NLP 術語中的邏輯形式)捕獲。在 EasyNLU 中,我們在規則定義中傳遞第三個參數來定義如何提取語義。我們使用帶有特殊標記的 JSON 語法來執行此操作:
new Rule ( "$Action" , "$EnableDisable" , "{action:@first}" ), @first告訴解析器選擇規則 RHS 第一個類別的值。在這種情況下,它將根據句子“啟用”或“禁用”。其他標記包括:
@identity :身分函數@last :選擇最後一個 RHS 類別的值@N : 選擇第 N 個RHS 類別的值,例如@3將選擇第 3 個@merge :合併所有類別的值。僅命名值(例如{action: enable} )將會合併@append :將所有類別的值追加到清單中。必須命名結果清單。只允許命名值在添加語義標記後,我們的規則變為:
List < Rule > rules = Arrays . asList (
new Rule ( "$ROOT" , "$Setting" , "@identity" ),
new Rule ( "$Setting" , "$Feature $Action" , "@merge" ),
new Rule ( "$Setting" , "$Action $Feature" , "@merge" ),
new Rule ( "$Feature" , "$Bluetooth" , "{feature: bluetooth}" ),
new Rule ( "$Feature" , "$Wifi" , "{feature: wifi}" ),
new Rule ( "$Feature" , "$Gps" , "{feature: gps}" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" ),
new Rule ( "$Action" , "$EnableDisable" , "{action: @first}" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" , "@last" ),
new Rule ( "$EnableDisable" , "$Enable" , "enable" ),
new Rule ( "$EnableDisable" , "$Disable" , "disable" ),
new Rule ( "$OnOff" , "on" , "enable" ),
new Rule ( "$OnOff" , "off" , "disable" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
);如果未提供語意參數,解析器將建立等於 RHS 的預設值。
若要執行解析器,請複製此儲存庫並將解析器模組匯入到您的 Android Studio/IntelliJ 專案中。 EasyNLU 解析器採用一個保存規則的Grammar物件、一個用於將輸入句子轉換為單字的Tokenizer物件以及一個可選的Annotator物件清單來註解數字、日期、地點等實體。
Grammar grammar = new Grammar ( rules , "$ROOT" );
Parser parser = new Parser ( grammar , new BasicTokenizer (), Collections . emptyList ());
System . out . println ( parser . parse ( "kill bt" ));
System . out . println ( parser . parse ( "wifi on" ));
System . out . println ( parser . parse ( "enable location" ));
System . out . println ( parser . parse ( "turn off GPS" ));您應該得到以下輸出:
23 rules
[{feature=bluetooth, action=disable}]
[{feature=wifi, action=enable}]
[{feature=gps, action=enable}]
[{feature=gps, action=disable}]
嘗試其他變化。如果範例變體的解析失敗,您將不會得到任何輸出。然後,您可以新增或修改規則並重複語法工程流程。
EasyNLU 現在支援結構化形式的清單。對於上述域,它可以處理類似的輸入
禁用 bt gps 定位
將這 3 個額外規則加入上面的語法:
new Rule("$Setting", "$Action $FeatureGroup", "@merge"),
new Rule("$FeatureGroup", "$Feature $Feature", "{featureGroup: @append}"),
new Rule("$FeatureGroup", "$FeatureGroup $Feature", "{featureGroup: @append}"),
執行一個新查詢,例如:
System.out.println(parser.parse("disable location bt gps"));
你應該得到這個輸出:
[{action=disable, featureGroup=[{feature=gps}, {feature=bluetooth}, {feature=gps}]}]
請注意,僅當查詢中存在多個要素時才會觸發這些規則
註釋器使特定類型的標記變得更容易,否則這些標記將很麻煩或完全不可能透過規則處理。以NumberAnnotator類別為例。它將檢測所有數字並將其註釋為$NUMBER 。然後您可以直接在規則中引用該類別,例如:
Rule r = new Rule("$Conversion", "$Convert $NUMBER $Unit $To $Unit", "{convertFrom: {unit: @2, quantity: @1}, convertTo: {unit: @last}}"
EasyNLU 目前附帶了一些註釋器:
NumberAnnotator :註解數字DateTimeAnnotator :註解一些日期格式。也提供了您使用DateTimeAnnotator.rules()新增的自己的規則TokenAnnotator :將輸入的每個標記註記為$TOKENPhraseAnnotator :將輸入的每個連續短語註釋為$PHRASE若要使用您自己的自訂註釋器,請實作Annotator介面並將其傳遞給解析器。請參閱內建註釋器以了解如何實作註釋器。
EasyNLU 支援從文字檔案載入規則。每條規則必須位於單獨的行中。左、右和語意必須用製表符分隔:
$EnableDisable ?$Switch $OnOff @last
注意不要使用自動將製表符轉換為空格的 IDE
隨著更多規則新增到解析器,您會發現解析器會為某些輸入找到多個解析。這是由於人類語言普遍存在歧義。要確定解析器對您的任務的準確性,您需要透過標籤的範例來運行它。
與前面的規則一樣,EasyNLU 採用純文字定義的範例。每一行應該是一個單獨的範例,並且應包含由製表符分隔的原始文字和結構化形式:
take my medicine at 4pm {task:"take my medicine", startTime:{hour:4, shift:"pm"}}
重要的是您的輸入要涵蓋可接受的數量或變化。如果讓不同的人來完成這項任務,你會得到更多的多樣性。範例的數量取決於領域的複雜性。此專案提供的範例資料集有 100 多個範例。
獲得數據後,您可以將其放入數據集。學習部分由trainer模組處理;將其匯入到您的專案中。像這樣載入資料集:
Dataset dataset = Dataset . fromText ( 'filename.txt' )我們評估解析器以確定兩種類型的準確性
為了運行評估,我們使用Model類別:
Model model = new Model(parser);
model.evaluate(dataset, 2);
評估函數的第二個參數是詳細程度。數字越大,輸出越詳細。 evaluate()函數透過每個範例運行解析器並顯示不正確的解析,最終顯示準確度。如果您獲得的準確率都在 90 左右,那麼就不需要訓練,您可能可以透過後處理來處理那些少數錯誤的解析。如果預言機準確率高但預測準確率低,那麼訓練系統將會有所幫助。如果預言機準確率本身就很低,那麼你需要做更多的文法工程。
為了獲得正確的解析,我們對它們進行評分並選擇得分最高的一個。 EasyNLU 使用簡單的線性模型來計算分數。使用帶有鉸鏈損失函數的隨機梯度下降 (SGD) 進行訓練。輸入特徵基於結構化表單中的規則計數和欄位。然後將訓練後的權重儲存到文字檔案中。
您可以調整一些模型/訓練參數以獲得更好的準確性。對於提醒模型,使用了以下參數:
HParams hparams = HParams . hparams ()
. withLearnRate ( 0.08f )
. withL2Penalty ( 0.01f )
. set ( SVMOptimizer . CORRECT_PROB , 0.4f );運行訓練程式碼如下:
Experiment experiment = new Experiment ( model , dataset , hparams , "yourdomain.weights" );
experiment . train ( 100 , false );這將訓練模型 100 個 epoch,訓練-測試分割為 0.8。它將顯示測試集的準確性並將模型權重保存到提供的檔案路徑中。若要在整個資料集上進行訓練,請將部署參數設為 true。您可以運行交互模式從控制台獲取輸入:
experiement.interactive();
注意:即使有大量範例,也不能保證訓練能夠產生高精度。對於某些場景,所提供的功能可能不夠具有區分性。如果您遇到這種情況,請記錄問題,我們可以找到其他功能。
模型權重是純文字檔。對於 Android 項目,您可以將其放置在assets資料夾中並使用 AssetManager 載入它。請參閱 ReminderNlu.java 以了解更多詳細資訊。您甚至可以將權重和規則儲存在雲端並透過無線方式更新您的模型(Firebase 有人嗎?)。
一旦解析器很好地將自然語言輸入轉換為結構化形式,您可能會希望該資料位於任務特定物件中。對於某些領域(例如上面的玩具範例),它可能非常簡單。對於其他人,您可能必須解析對日期、地點、聯絡人等內容的引用。值。請參考 ArgumentResolver.java 查看解析是如何完成的。
提示:定義規則時盡量減少解析邏輯,並在後處理中完成大部分工作。這將使規則更加簡單。


