DeepMorphy
1.0.0
DeepMorphy 是一種基於神經網路的俄語詞法分析器。
DeepMorphy 是俄語的詞法分析器。作為 .Net Standard 2.0 庫提供。能:
DeepMorphy 中的術語部分借用自 pymorphy2 形態分析器。
Grammeme (英文 grammeme)- 單字的文法類別之一的意思(例如,過去式、單數、陽性)。
語法類別是一組互斥的語法,它們描述了一些共同特徵(例如,性別、時態、格等)。 DeepMorphy 支援的所有類別和語法的清單位於此處。
標籤(英文標籤)- 一組表徵給定單字的語法(例如,單字刺蝟的標籤 - 名詞、單數、主格、陽性)。
Lemma (英語引理)是單字的正常形式。
詞形還原(eng. lemmatization) - 將單字還原為正常形式。
詞位是一個單字的所有形式的集合。
DeepMorphy 的核心要素是神經網路。對於大多數單字,形態分析和詞形還原是由網路執行的。某些類型的單字由預處理器處理。
有 3 個預處理器:
這個網路是在張量流框架上建構和訓練的。 Opencorpora 字典用作資料集。透過 TensorFlowSharp 整合到 .Net 中。
DeepMorphy 中單字解析的計算圖由 11 個「子網路」組成:
改變單字形式的問題是透過1 seq2seq網路來解決的。
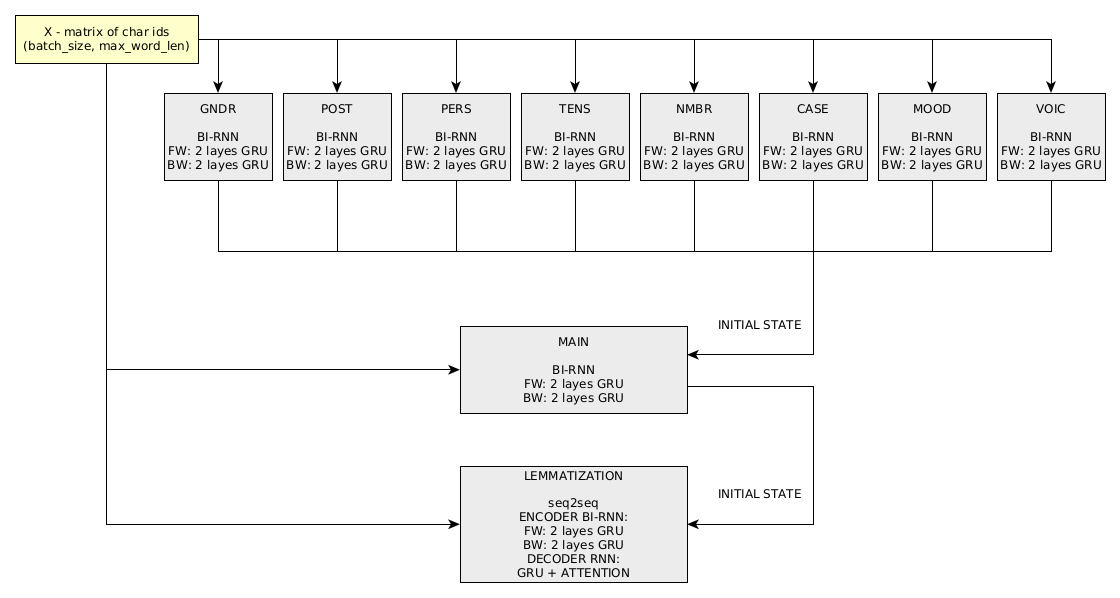
訓練依序進行,先依類別訓練網路(順序無關緊要)。接下來,訓練主要的標籤分類、詞形還原和用於改變單字形式的網路。訓練是在 3 個 Titan X GPU 上進行的,可以在此處查看最新版本測試資料集的網路效能指標。
DeepMorphy for .NET 是一個 .Net Standard 2.0 函式庫。唯一的依賴項是 TensorflowSharp 庫(神經網路透過它啟動)。
該庫在 Nuget 中發布,因此透過它安裝是最簡單的。
如果有套件管理器:
Install-Package DeepMorphy
如果項目支援PackageReference:
<PackageReference Include="DeepMorphy"/>
如果有人想從原始碼構建,那麼 C# 原始碼就在這裡。 Rider用於開發(一切都應該在工作室組裝,沒有任何問題)。
所有操作都是透過 MorphAnalyzer 類別物件執行的:
var morph = new MorphAnalyzer ( ) ;理想情況下,最好將其用作單例;創建物件時,會花費一些時間載入字典和網路。線程安全。創建時可以將以下參數傳遞給建構函數:
對於解析,使用 Parse 方法(它採用帶有用於分析的單字的 IEnumerable 作為輸入,傳回帶有分析結果的 IEnumerable)。
var results = morph . Parse ( new string [ ]
{
"королёвские" ,
"тысячу" ,
"миллионных" ,
"красотка" ,
"1-ый"
} ) . ToArray ( ) ;
var morphInfo = results [ 0 ] ;支援的語法類別、語法及其鍵的列表位於此處。如果您需要找出最可能的語法(標籤)組合,那麼您需要使用 MorphInfo 物件的 BestTag 屬性。
// выводим лучшую комбинацию граммем для слова
Console . WriteLine ( morphInfo . BestTag ) ;根據單字本身,並不總是能夠明確地確定其語法類別的含義(請參閱同音異義詞),因此 DeepMorphy 允許您查看給定單字的頂部標籤(Tags 屬性)。
// выводим все теги для слова + их вероятность
foreach ( var tag in morphInfo . Tags )
Console . WriteLine ( $ " { tag } : { tag . Power } " ) ;任何標籤中是否存在語法組合:
// есть ли в каком-нибудь из тегов прилагательные единственного числа
morphInfo . HasCombination ( "прил" , "ед" ) ;最有可能的標籤中是否存在語法組合:
// ясляется ли лучший тег прилагательным единственного числа
morphInfo . BestTag . Has ( "прил" , "ед" ) ;從最佳標籤中檢索特定語法類別:
// выводит часть речи лучшего тега и число
Console . WriteLine ( morphInfo . BestTag [ "чр" ] ) ;
Console . WriteLine ( morphInfo . BestTag [ "число" ] ) ;當您同時需要有關多個語法類別的資訊(例如,詞性和數字)時,可以使用標籤。如果您只對一種類別感興趣,那麼您可以使用 MorphInfo 物件語法類別含義機率的介面。
// выводит самую вероятную часть речи
Console . WriteLine ( morphInfo [ "чр" ] . BestGramKey ) ;您也可以按文法類別取得機率分佈:
// выводит распределение вероятностей для падежа
foreach ( var gram in morphInfo [ "падеж" ] . Grams )
{
Console . WriteLine ( $ " { gram . Key } : { gram . Power } " ) ;
}如果與詞法分析一起,您需要取得單字的詞條,則必須如下建立分析器:
var morph = new MorphAnalyzer ( withLemmatization : true ) ;引理可以從單字標籤中獲得:
Console . WriteLine ( morphInfo . BestTag . Lemma ) ;檢查給定單字是否有引理:
morphInfo . HasLemma ( "королевский" ) ;CanBeSameLexeme 方法可用來尋找單字素的單字:
// выводим все слова, которые могут быть формой слова королевский
var words = new string [ ]
{
"королевский" ,
"королевские" ,
"корабли" ,
"пересказывают" ,
"королевского"
} ;
var results = morph . Parse ( words ) . ToArray ( ) ;
var mainWord = results [ 0 ] ;
foreach ( var morphInfo in results )
{
if ( mainWord . CanBeSameLexeme ( morphInfo ) )
Console . WriteLine ( morphInfo . Text ) ;
}如果只需要詞形還原而不需要詞法解析,那麼就需要使用 Lemmatize 方法:
var tasks = new [ ]
{
new LemTask ( "синяя" , morph . TagHelper . CreateTag ( "прил" , gndr : "жен" , nmbr : "ед" , @case : "им" ) ) ,
new LemTask ( "гуляя" , morph . TagHelper . CreateTag ( "деепр" , tens : "наст" ) )
} ;
var lemmas = morph . Lemmatize ( tasks ) . ToArray ( ) ;
foreach ( var lemma in lemmas )
Console . WriteLine ( lemma ) ;DeepMorphy 可以更改詞位中單字的形式;支援的詞形變化清單位於此處。字典單字只能在字典中可用的形式內進行更改。要更改單字的形式,請使用 Inflect 方法;它將 InflectTask 物件的枚舉作為輸入(包含來源單字、來源單字的標籤以及應放置該單字的標籤)。輸出是具有所需表單的枚舉(如果無法處理表單,則為 null)。
var tasks = new [ ]
{
new InflectTask ( "синяя" ,
morph . TagHelper . CreateTag ( "прил" , gndr : "жен" , nmbr : "ед" , @case : "им" ) ,
morph . TagHelper . CreateTag ( "прил" , gndr : "муж" , nmbr : "ед" , @case : "им" ) ) ,
new InflectTask ( "гулять" ,
morph . TagHelper . CreateTag ( "инф_гл" ) ,
morph . TagHelper . CreateTag ( "деепр" , tens : "наст" ) )
} ;
var results = morph . Inflect ( tasks ) ;
foreach ( var result in results )
Console . WriteLine ( result ) ;也可以使用 Lexeme 方法來獲取單字的所有形式(對於字典單詞,它會傳回字典中的所有內容,對於其他單詞,它會傳回受支援的詞形變化的所有形式)。
var word = "лемматизировать" ;
var tag = m . TagHelper . CreateTag ( "инф_гл" ) ;
var results = m . Lexeme ( word , tag ) . ToArray ( ) ;這個演算法的特點之一是,當改變形式或生成詞位時,網路可以「發明」單字的不存在(假設)形式,即語言中未使用的形式。例如,下面你會看到「will run」這個詞,儘管目前語言中並沒有特別使用它。
var tasks = new [ ]
{
new InflectTask ( "победить" ,
m . TagHelper . CreateTag ( "инф_гл" ) ,
m . TagHelper . CreateTag ( "гл" , nmbr : "ед" , tens : "буд" , pers : "1л" , mood : "изъяв" ) )
} ;
Console . WriteLine ( m . Inflect ( tasks ) . First ( ) ) ; 


