idt
1.0.0

影像資料集工具 (IDT) 是一款 CLI 應用程序,旨在讓您更輕鬆、更快速地建立用於深度學習的影像資料集。該工具透過從多個搜尋引擎(例如 duckgo、bing 和 deviantart)中抓取映像來實現此目的。 IDT 還優化圖像資料集,儘管此功能是可選的,但使用者可以縮小和壓縮圖像以獲得最佳檔案大小和尺寸。使用idt建立的範例資料集總共包含 23.688 個影像文件,僅重 559.2 MB。
我很自豪地宣布我們的最新版本! ??
發生了什麼變化
您可以透過 pip 或複製此儲存庫來安裝它。
user@admin:~ $ pip3 install idt
或者
user@admin:~ $ git clone https://github.com/deliton/idt.git && cd idt
user@admin:~/idt $ sudo python3 setup.py install
開始使用 IDT 最快的方法是執行簡單的「run」命令。只需在您最喜歡的控制台中編寫如下內容:
user@admin:~ $ idt run -i apples 這將快速下載 50 張蘋果圖片。預設情況下,它使用 duckgo 搜尋引擎來執行此操作。運行命令接受以下選項:
| 選項 | 描述 |
|---|---|
| -i或--input | 關鍵字來尋找所需的圖像。 |
| -s或--size | 要下載的圖像數量。 |
| -e或--engine | 所需的搜尋引擎(選項:duckgo、bing、bing_api 和 flickr_api) |
| --調整大小方法 | 選擇影像的調整大小方法。 (選項:long_side、short_side 和 smartcrop) |
| -is或--image-size | 選項設定所需的影像尺寸比例。預設=512 |
| -ak或--api-key | 如果您使用的搜尋引擎需要 API 金鑰,則需要此選項 |
IDT 需要一個設定檔來告訴它如何組織資料集。您可以使用以下命令創建它:
user@admin:~ $ idt init此命令將觸發設定檔建立器並詢問所需的資料集參數。在此範例中,我們建立一個包含您最喜歡的汽車影像的資料集。該命令將詢問的第一個參數是您的資料集應具有什麼名稱?在此範例中,我們將資料集命名為“我最喜歡的汽車”
Insert a name for your dataset: : My favorite cars然後該工具將詢問每次搜尋需要多少個樣本來安裝您的資料集。為了為深度學習建立良好的資料集,需要許多圖像,並且由於我們使用搜尋引擎來抓取圖像,因此需要使用不同關鍵字進行多次搜尋才能安裝大小合適的資料集。該值將對應於每次搜尋時應下載的圖像數量。在此範例中,我們需要一個每個類別包含 250 個影像的資料集,並且我們將使用 5 個關鍵字來掛載每個類別。因此,如果我們在此輸入數字 50,IDT 將下載所提供的每個關鍵字的 50 張圖片。如果我們提供 5 個關鍵字,我們應該會獲得所需的 250 張圖像。
How many samples per search will be necessary? : 50該工具現在將詢問圖像尺寸比率。由於使用大圖像來訓練神經網路是不可行的,因此我們可以選擇以下圖像尺寸比率之一並將圖像縮小到該尺寸。在此範例中,我們將選擇 512x512,儘管 256x256 對於此任務來說是更好的選擇。
Choose images resolution:
[1] 512 pixels / 512 pixels (recommended)
[2] 1024 pixels / 1024 pixels
[3] 256 pixels / 256 pixels
[4] 128 pixels / 128 pixels
[5] Keep original image size
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
What is the desired image size ratio: 1然後選擇“longer_side”作為調整大小方法。
[1] Resize image based on longer side
[2] Resize image based on shorter side
[3] Smartcrop
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
Desired Image resize method: : longer_side
現在您必須選擇資料集應有幾個類別/資料夾。在這個例子中,這部分可能非常個人化,但我最喜歡的汽車是:雪佛蘭 Impala、路虎攬勝極光、特斯拉 Model X 和(為什麼不)AvtoVAZ Lada。因此,在本例中,我們有 4 個類,每個類別對應一個最喜歡的類別。
How many image classes are required? : 4然後,系統會要求您在可用的搜尋引擎之間進行選擇。在這個例子中,我們將使用 DuckGO 來搜尋圖像。
Choose a search engine:
[1] Duck GO (recommended)
[2] Bing
[3] Bing API
[4] Flickr API
Select option:: 1現在我們必須做一些重複的表格填寫。我們必須命名每個類別以及將用於查找圖像的所有關鍵字。請注意,這部分稍後可以透過您自己的程式碼進行更改,以產生更多的類別和關鍵字。
Class 1 name: : Chevrolet Impala輸入第一個類別名稱後,系統會要求我們提供所有關鍵字來尋找資料集。請記住,我們告訴程式下載每個關鍵字的 50 張圖像,因此在本例中我們必須提供 5 個關鍵字才能取得所有 250 張圖像。每個關鍵字必須用逗號 (,) 分隔
In order to achieve better results, choose several keywords that will
be provided to the search engine to find your class in different settings.
Example:
Class Name: Pineapple
keywords: pineapple, pineapple fruit, ananas, abacaxi, pineapple drawing
Type in all keywords used to find your desired class, separated by commas: Chevrolet Impala 1967 car photos,
chevrolet impala on the road, chevrolet impala vintage car, chevrolet impala convertible 1961, chevrolet impala 1964 lowrider
然後重複填寫類別名稱及其關鍵字的過程,直到填寫完所需的 4 個類別。
Dataset YAML file has been created successfully. Now run idt build to mount your dataset!您的資料集設定檔已建立。現在只需執行以下命令,看看奇蹟發生:
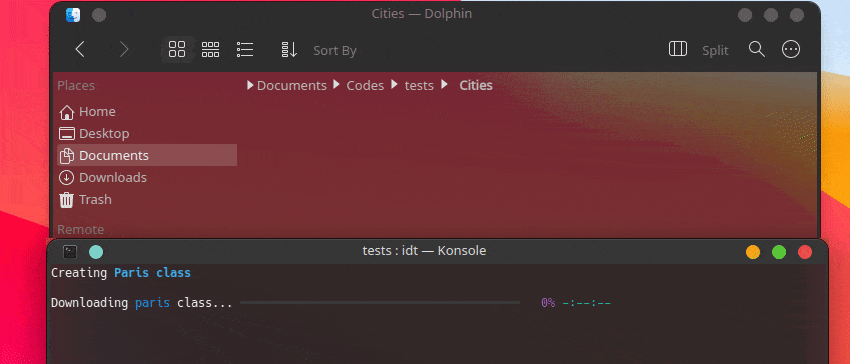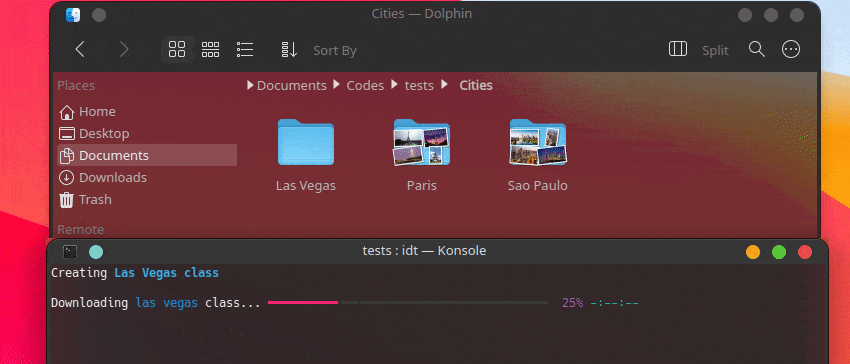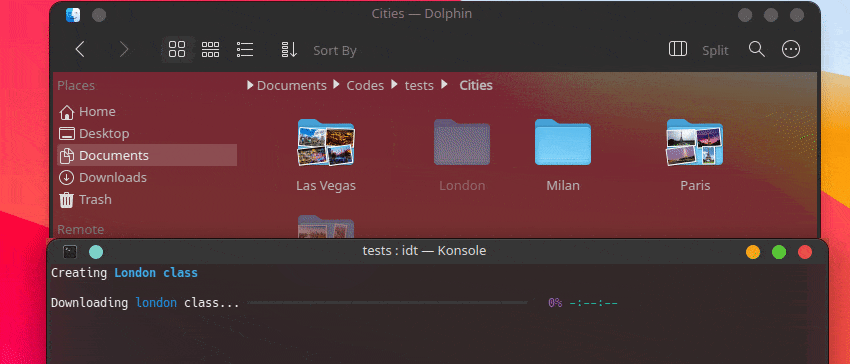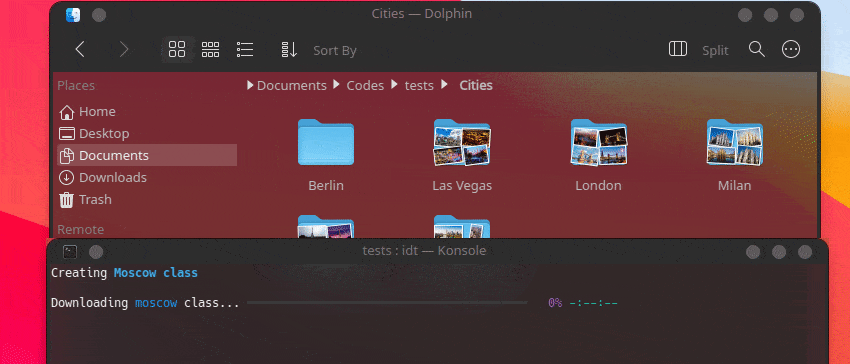
user@admin:~ $ idt build並等待資料集正在安裝:
Creating Chevrolet Impala class
Downloading Chevrolet Impala 1967 car photos [#########################-----------] 72% 00:00:12
最後,所有圖像都將位於具有資料集名稱的資料夾中。此外,包含資料集統計資訊的 csv 檔案也包含在資料集的根資料夾中。
由於深度學習通常要求您將資料集拆分為訓練/驗證資料夾的子集,因此該專案也可以為您執行此操作!只需運行:
user@admin:~ $ idt split現在您必須選擇一個訓練/有效比例。在此範例中,我選擇保留 70% 的圖像用於訓練,其餘圖像則保留用於驗證:
Choose the desired proportion of images of each class to be distributed in train/valid folders.
What percentage of images should be distributed towards training?
(0-100): 70
70 percent of the images will be moved to a train folder, while 30 percent of the remaining images
will be stored in a validation folder.
Is that ok? [Y/n]: y就是這樣!現在應該可以透過對應的 train/valid 子目錄來找到資料集分割。
這個專案是我在業餘時間開發的,仍然需要付出很多努力才能消除錯誤。非常感謝拉取請求和貢獻者,請隨意以任何方式做出貢獻!


