context search engine
1.0.0

該專案的主要目標是透過提供用戶友好的介面來展示向量搜尋功能,該介面使用戶能夠在文字文檔語料庫中執行上下文搜尋。透過利用 Hugging Face 的 BERT 和 Facebook 的 FAISS 的強大功能,我們根據用戶查詢的語義而不是單純的關鍵字來匹配返回高度相關的文字段落。該計畫是希望更深入了解上下文文本搜尋世界並透過最先進的 NLP 技術增強其應用程式的開發人員、研究人員和愛好者的起點。
我的目標是確保我們從頭開始了解幕後的向量資料庫。
應用程式螢幕截圖:
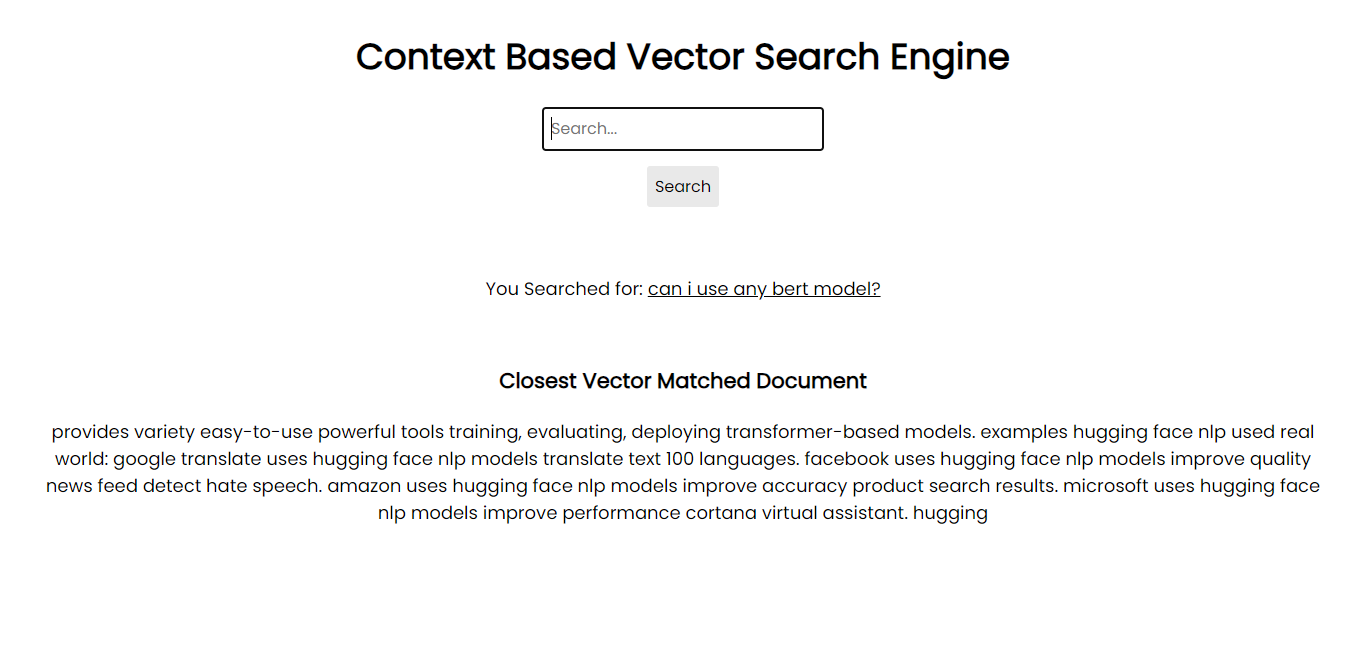
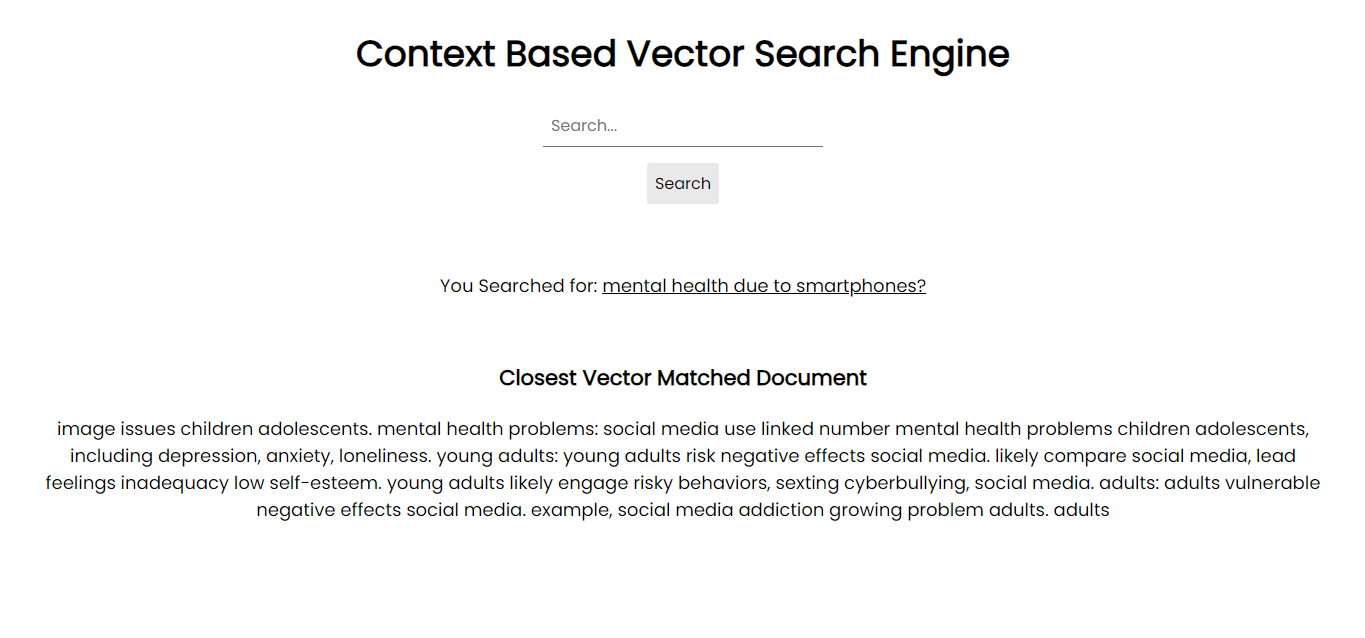
為了在您的系統上運行,您可以使用需求檔案透過 pip 安裝所有必需的軟體包:
pip install -r requirements.txt供您參考,我使用的是 Python 3.10.1。
但是,如果您有 GPU,則需要安裝 FAISS GPU 以實現更快、更大的資料庫整合。
該項目的目前版本包括:
雖然該專案提供了一個功能性上下文搜尋系統,但它被設計為模組化,允許潛在的擴展和整合到更大的系統或應用程式中。
該專案的基礎在於相信與傳統的基於關鍵字的方法相比,現代 NLP 技術可以提供更準確且上下文相關的搜尋結果。以下是我們方法的細分:
根據該方法,我將專案分為兩個部分:
第 1 部分:產生可搜尋向量數據
在本節中,我們首先從文件中讀取輸入,將其分解為更小的區塊,使用基於 BERT 的模型建立向量,然後使用 FAISS 有效地儲存它。這是說明相同內容的流程圖。
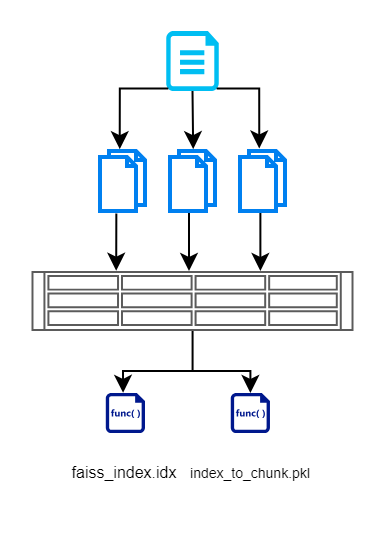
我們建立 FAISS 索引文件,其中包含分塊文件的向量表示。我們也儲存每個區塊的索引。這是維護,以便我們不必再次查詢資料庫/文件。這有助於我們刪除冗餘的讀取操作。
我們使用 create_index.py 執行此部分。它將產生上述2個文件。如果您需要使用其他模型,您願意從 HuggingFace hub 進行操作嗎?
注意:如果您在設定維度超參數時發現問題,請檢查模型 config.json 檔案以查找有關您嘗試使用的模型維度的詳細資訊。
第 2 部分:建立可搜尋的應用程式介面
在本節中,我的目標是建立一個允許使用者與文件互動的介面。我優先考慮簡約設計,不會造成額外的障礙。
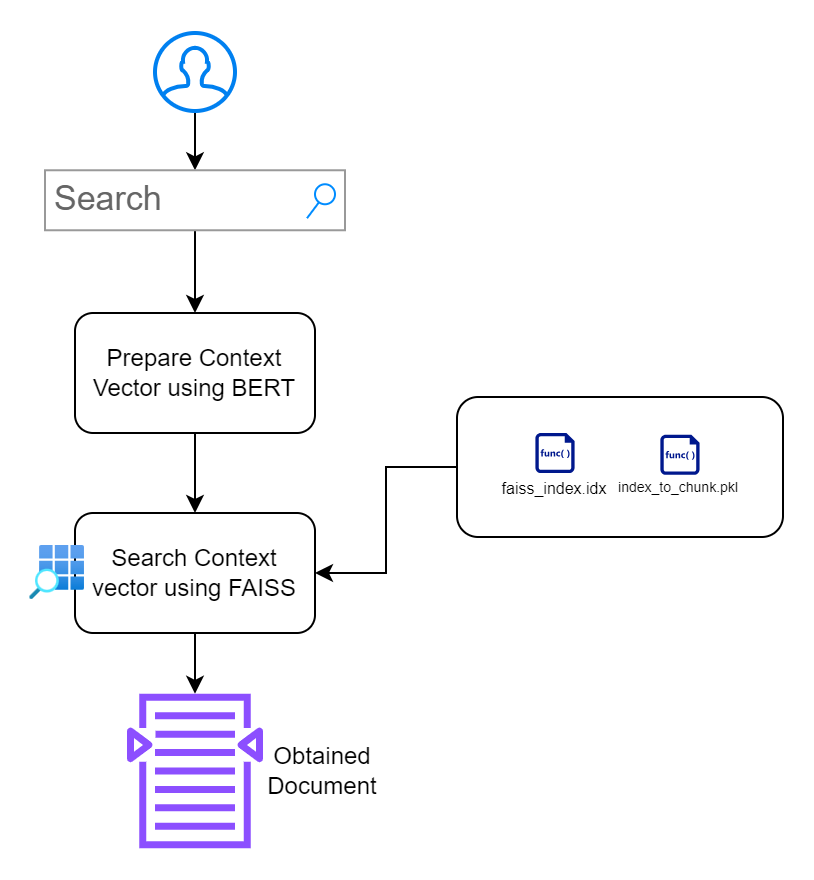
index.html :用於輸入搜尋查詢的前端 HTML 頁面。app.py :為前端提供服務並處理搜尋查詢的 Flask 應用程式。search_engine.py :包含嵌入生成、FAISS 搜尋和關鍵字突出顯示的邏輯。 /context_search/
- templates/
- index.html
- static/
- css/
- style.css
- images/
- img1.png
- img2.png
- Approach.png files
- app.py
- search_engine.py
- create_index.py
- index_to_chunk.pkl
- faiss_index.idxfaiss_index.idx ) 以及從索引到文字區塊的隨附映射 ( index_to_chunk.pkl )。 python app.py
-- OR --
flask run --host=127.0.0.1 --port=5000
http://localhost:5000 。總是有改進的空間。以下是一些潛在的改進和可整合的附加功能:
該專案已獲得 MIT 許可。請隨意引用、修改、分發和貢獻。閱讀更多。
如果您有興趣改進這個項目,歡迎您做出貢獻!請在此儲存庫上開啟拉取請求或問題。我基本上優先考慮上述事情來進行改進。其他拉取請求也會被考慮,但優先順序較低。
預先感謝您的關注。 :快樂的: 。


