Python 異常值檢測 (PyOD)
部署、文件、統計資料和許可證

先讀我的內容
歡迎使用 PyOD,這是一個全面但易於使用的 Python 庫,用於檢測多變量資料中的異常。無論您要處理小型專案還是大型資料集,PyOD 都提供一系列演算法來滿足您的需求。
- 對於時間序列異常值檢測,請使用 TODS。
- 對於圖形異常值檢測,請使用 PyGOD。
- 效能比較和資料集:我們有一篇 45 頁的全面異常檢測基準論文。完全開源的 ADBench 在 57 個基準資料集上比較了 30 種異常檢測演算法。
- 在異常檢測資源中了解有關異常檢測的更多信息
- 分散式系統上的 PyOD :您也可以在 databricks 上執行 PyOD。
關於PyOD
PyOD 成立於 2017 年,已成為檢測多元資料中異常/異常物件的首選Python 庫。這個令人興奮但具有挑戰性的領域通常被稱為異常值檢測或異常檢測。
PyOD 包含 50 多種偵測演算法,從經典的 LOF (SIGMOD 2000) 到尖端的 ECOD 和 DIF (TKDE 2022 和 2023)。自2017年以來,PyOD已成功應用於許多學術研究計畫和商業產品,下載量超過2,200萬次。它也得到了機器學習社群的廣泛認可,有各種專門的貼文/教程,包括 Analytics Vidhya、KDnuggets 和 Towards Data Science。
PyOD 的特點是:
- 跨各種演算法的統一、使用者友善的介面。
- 模型範圍廣泛,從經典技術到PyTorch中最新的深度學習方法。
- 高效能和高效率,利用 numba 和 joblib 進行 JIT 編譯和平行處理。
- 快速訓練和預測,透過 SUOD 框架實現[50]。
使用 5 行程式碼進行異常值偵測:
# Example: Training an ECOD detector
from pyod . models . ecod import ECOD
clf = ECOD ()
clf . fit ( X_train )
y_train_scores = clf . decision_scores_ # Outlier scores for training data
y_test_scores = clf . decision_function ( X_test ) # Outlier scores for test data
選擇正確的演算法:不確定從哪裡開始?考慮這些強大且可解釋的選項:
- ECOD:使用 ECOD 進行異常值偵測的範例
- 隔離森林:使用隔離森林進行異常值檢測的範例
或者,探索 MetaOD 以取得資料驅動的方法。
引用 PyOD :
PyOD 論文發表在 Journal of Machine Learning Research (JMLR)(MLOSS track)。如果您在科學出版物中使用 PyOD,我們希望引用以下論文:
@文章{zhao2019pyod,
作者 = {Zhao、Yue 和 Nasrullah、Zain 和 Li、Zheng},
title = {PyOD:用於可擴充異常值偵測的 Python 工具箱},
期刊={機器學習研究期刊},
年 = {2019},
體積 = {20},
數字={96},
頁數 = {1-7},
網址 = {http://jmlr.org/papers/v20/19-011.html}
}
或者:
Zhao, Y.、Nasrullah, Z. 和 Li, Z.,2019。機器學習研究期刊 (JMLR),20(96),第 1-7 頁。
有關異常檢測的更廣泛視角,請參閱我們的 NeurIPS 論文 ADBench:異常檢測基準論文和 ADGym:深度異常檢測的設計選擇:
@文章{han2022adbench,
title={Adbench:異常檢測基準},
作者={韓、宋橋和胡、西陽和黃、海亮和薑、敏奇和趙、岳},
期刊={神經資訊處理系統的進展},
音量={35},
頁數={32142--32159},
年={2022}
}
@文章{jian2023adgym,
title={ADGym:深度異常偵測的設計選擇},
作者={蔣、敏奇與侯、超川與鄭、敖與韓、松橋與黃、海亮與文、青松與胡、西陽與趙、岳},
期刊={神經資訊處理系統的進展},
音量={36},
年={2023}
}
目錄:
- 安裝
- API 備忘錄和參考
- ADBench 基準測試和資料集
- 模型保存和載入
- SUOD 快速列車
- 異常值閾值
- 實現的演算法
- 異常值檢測快速入門
- 如何貢獻
- 納入標準
安裝
PyOD 旨在使用pip或conda輕鬆安裝。由於更新和增強頻繁,我們建議使用最新版本的 PyOD:
pip install pyod # normal install
pip install --upgrade pyod # or update if needed
conda install -c conda-forge pyod
或者,您可以克隆並運行 setup.py 檔案:
git clone https://github.com/yzhao062/pyod.git
cd pyod
pip install .
所需的依賴項:
- Python 3.8 或更高版本
- 作業庫
- 繪圖庫
- numpy>=1.19
- 數字>=0.51
- scipy>=1.5.1
- scikit_learn>=0.22.0
可選依賴項(請參閱下面的詳細資訊) :
- 組合(可選,models/combination.py和FeatureBagging必需)
- pytorch(可選,AutoEncoder 和其他深度學習模型所需)
- suod(可選,運行 SUOD 模型所需)
- xgboost(可選,XGBOD 必需)
- pythresh(可選,閾值處理所需)
API 備忘錄和參考
完整的 API 參考可在 PyOD 文件中找到。以下是所有探測器的快速備忘單:
- fit(X) :安裝偵測器。在無監督方法中參數 y 被忽略。
- Decision_function(X) :使用擬合偵測器預測 X 的原始異常分數。
- 預測(X) :使用擬合的偵測器確定樣本是否為異常值作為二進位標籤。
- Predict_proba(X) :使用擬合偵測器估計樣本為異常值的機率。
- Predict_confidence(X) :基於每個樣本評估模型的置信度(適用於predict和predict_proba)[35]。
擬合模型的關鍵屬性:
- Decision_scores_ :訓練資料的離群值。分數越高通常表示行為越異常。異常值通常具有較高的分數。
- labels_ :訓練資料的二進位標籤,其中 0 表示正常值,1 表示異常值/異常。
ADBench 基準測試和資料集
我們剛剛發布了 45 頁、最全面的 ADBench:異常檢測基準 [15]。完全開源的 ADBench 在 57 個基準資料集上比較了 30 種異常檢測演算法。
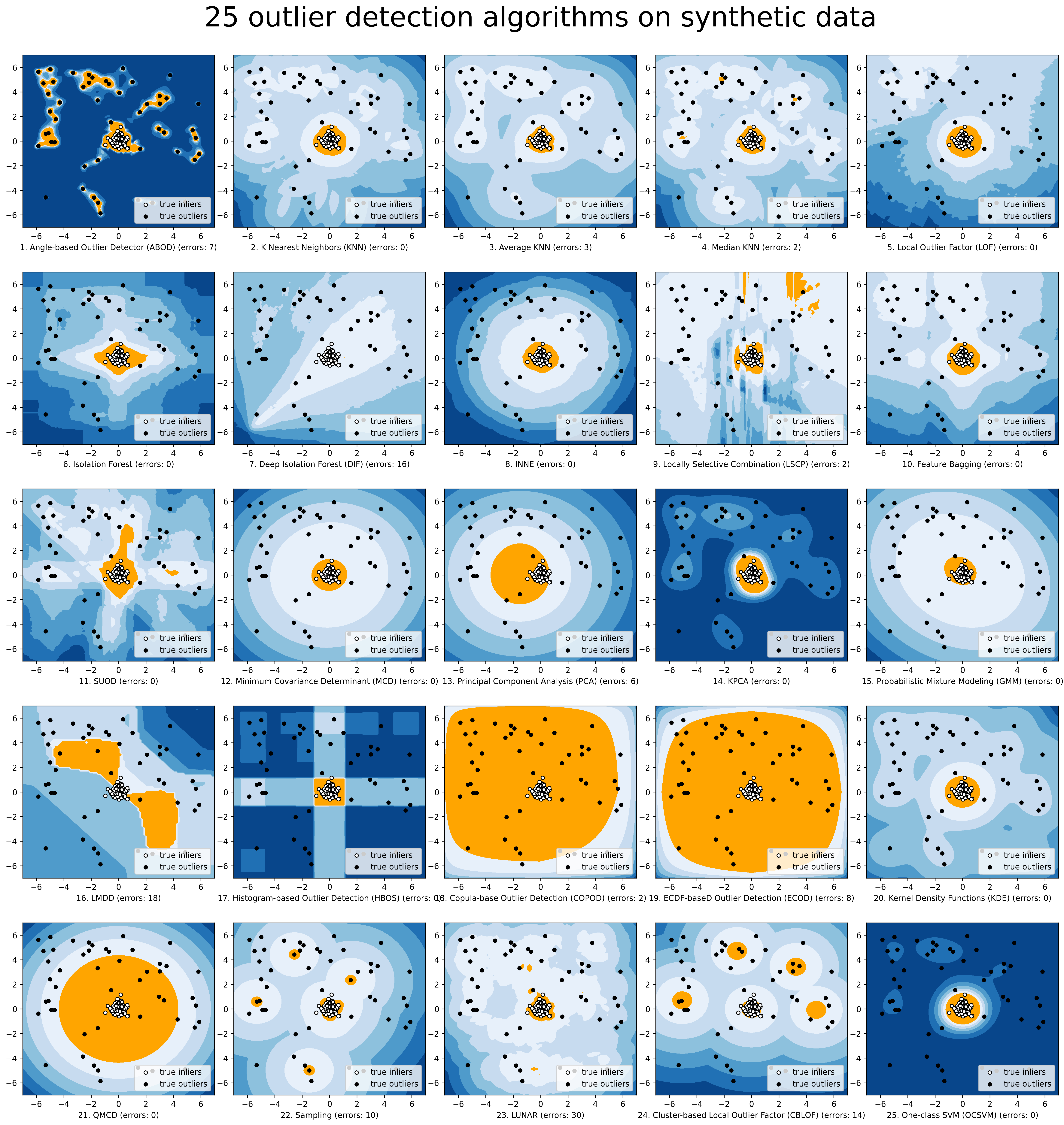
ADBench的組織架構如下:

為了更簡單的視覺化,我們透過compare_all_models.py對所選模型進行比較。
模型保存和載入
PyOD 在模型持久性方面採用了與 sklearn 類似的方法。有關說明,請參閱模型持久性。
簡而言之,我們建議使用 joblib 或 pickle 來儲存和載入 PyOD 模型。有關範例,請參閱“examples/save_load_model_example.py”。簡而言之,簡單如下:
from joblib import dump , load
# save the model
dump ( clf , 'clf.joblib' )
# load the model
clf = load ( 'clf.joblib' )
眾所周知,保存神經網路模型存在挑戰。檢查 #328 和 #88 以取得臨時解決方法。
SUOD 快速列車
快速訓練與預測:利用 SUOD 框架 [50],可以在 PyOD 中使用大量偵測模型進行訓練和預測。請參閱 SUOD 論文和 SUOD 範例。
from pyod . models . suod import SUOD
# initialized a group of outlier detectors for acceleration
detector_list = [ LOF ( n_neighbors = 15 ), LOF ( n_neighbors = 20 ),
LOF ( n_neighbors = 25 ), LOF ( n_neighbors = 35 ),
COPOD (), IForest ( n_estimators = 100 ),
IForest ( n_estimators = 200 )]
# decide the number of parallel process, and the combination method
# then clf can be used as any outlier detection model
clf = SUOD ( base_estimators = detector_list , n_jobs = 2 , combination = 'average' ,
verbose = False )
異常值閾值
設定污染等級時可以採取更多基於數據的方法。透過使用閾值方法,可以用用於分離異常值和異常值的經過測試的技術來代替猜測任意值。請參閱 PyThresh 以更深入地了解閾值。
from pyod . models . knn import KNN
from pyod . models . thresholds import FILTER
# Set the outlier detection and thresholding methods
clf = KNN ( contamination = FILTER ())
請參閱閾值處理中支援的閾值處理方法。
實現的演算法
PyOD 工具包由四個主要功能組組成:
(i) 個體檢測演算法:
| 類型 | 縮寫 | 演算法 | 年 | 參考號 |
|---|
| 機率論 | ECOD | 使用經驗累積分佈函數的無監督異常值檢測 | 2022年 | [28] |
| 機率論 | ABOD | 基於角度的異常值檢測 | 2008年 | [22] |
| 機率論 | 快速ABOD | 使用近似法進行基於角度的快速異常值檢測 | 2008年 | [22] |
| 機率論 | 慢性阻塞性肺病 | COPOD:基於 Copula 的異常值偵測 | 2020年 | [27] |
| 機率論 | 瘋狂的 | 中位數絕對偏差 (MAD) | 1993年 | [19] |
| 機率論 | 求救 | 隨機異常值選擇 | 2012年 | [20] |
| 機率論 | 品質管理中心 | 準蒙特卡羅差異異常值偵測 | 2001年 | [11] |
| 機率論 | 凱德 | 使用核密度函數進行異常值檢測 | 2007年 | [24] |
| 機率論 | 取樣 | 透過採樣進行基於距離的快速異常值檢測 | 2013年 | [42] |
| 機率論 | 高斯模型 | 用於異常值分析的機率混合建模 | | [1] [第2章] |
| 線性模型 | 主成分分析 | 主成分分析(到特徵向量超平面的加權投影距離總和) | 2003年 | [41] |
| 線性模型 | 關鍵主成分分析法 | 核主成分分析 | 2007年 | [18] |
| 線性模型 | MCD | 最小協方差行列式(使用馬哈拉諾比斯距離作為離群值) | 1999年 | [16][37] |
| 線性模型 | 光碟 | 使用庫克距離進行異常值檢測 | 1977年 | [10] |
| 線性模型 | 開放式空間向量機 | 一類支援向量機 | 2001年 | [40] |
| 線性模型 | 低密度脂蛋白 | 基於偏差的異常值檢測 (LMDD) | 1996年 | [6] |
| 基於鄰近度 | 洛夫 | 局部離群因素 | 2000年 | [8] |
| 基於鄰近度 | COF | 基於連接性的異常值因素 | 2002年 | [43] |
| 基於鄰近度 | (增量)COF | 基於記憶體高效連接的離群因素(速度較慢,但降低儲存複雜度) | 2002年 | [43] |
| 基於鄰近度 | CBLOF | 基於聚類的局部離群因子 | 2003年 | [17] |
| 基於鄰近度 | 基因定位 | LOCI:使用局部相關積分進行快速異常值檢測 | 2003年 | [33] |
| 基於鄰近度 | HBOS | 基於直方圖的異常值分數 | 2012年 | [12] |
| 基於鄰近度 | kNN | k 最近鄰(使用到第 k 個最近鄰的距離作為離群值) | 2000年 | [36] |
| 基於鄰近度 | 平均KNN | 平均 kNN(使用到 k 個最近鄰的平均距離作為離群值) | 2002年 | [5] |
| 基於鄰近度 | 醫學KNN | 中位數 kNN(使用到 k 個最近鄰的中位數距離作為異常值得分) | 2002年 | [5] |
| 基於鄰近度 | 草皮 | 子空間異常值檢測 | 2009年 | [23] |
| 基於鄰近度 | 桿 | 基於旋轉的異常值檢測 | 2020年 | [4] |
| 離群值集合 | 愛森林 | 隔離森林 | 2008年 | [29] |
| 離群值集合 | 伊內 | 使用最近鄰整合的基於隔離的異常檢測 | 2018年 | [7] |
| 離群值集合 | 差值 | 用於異常檢測的深度隔離森林 | 2023年 | [45] |
| 離群值集合 | FB | 特徵裝袋 | 2005年 | [25] |
| 離群值集合 | LSCP | LSCP:並行異常值集合的局部選擇性組合 | 2019年 | [49] |
| 離群值集合 | XGBOD | 基於極端增強的異常值檢測(監督) | 2018年 | [48] |
| 離群值集合 | 洛達 | 輕量級在線異常檢測器 | 2016年 | [34] |
| 離群值集合 | 蘇奧德 | SUOD:加速大規模無監督異質異常值偵測(加速) | 2021年 | [50] |
| 神經網路 | 自動編碼器 | 全連接自動編碼器(使用重建誤差作為離群值) | | [1] [第 3 章] |
| 神經網路 | VAE | 變分自動編碼器(使用重建誤差作為離群值) | 2013年 | [21] |
| 神經網路 | β-VAE | 變分自動編碼器(所有透過改變伽瑪和容量定制的損失項) | 2018年 | [9] |
| 神經網路 | SO_GAAL | 單一目標生成對抗主動學習 | 2019年 | [30] |
| 神經網路 | MO_GAAL | 多目標生成對抗主動學習 | 2019年 | [30] |
| 神經網路 | 深SVDD | 深度一類分類 | 2018年 | [38] |
| 神經網路 | 阿諾甘 | 使用生成對抗網路進行異常偵測 | 2017年 | [39] |
| 神經網路 | 阿拉德 | 對抗性學習異常檢測 | 2018年 | [47] |
| 神經網路 | AE1支援向量機 | 基於自動編碼器的一類支援向量機 | 2019年 | [31] |
| 神經網路 | 開發網 | 使用偏差網路進行深度異常檢測 | 2019年 | [32] |
| 基於圖的 | R圖 | 透過 R 圖表檢測異常值 | 2017年 | [46] |
| 基於圖的 | 月亮 | LUNAR:透過圖神經網路統一局部異常值檢測方法 | 2022年 | [13] |
(ii) 離群值集合與離群值偵測器組合架構:
| 類型 | 縮寫 | 演算法 | 年 | 參考號 |
|---|
| 離群值集合 | FB | 特徵裝袋 | 2005年 | [25] |
| 離群值集合 | LSCP | LSCP:平行異常值集合的局部選擇性組合 | 2019年 | [49] |
| 離群值集合 | XGBOD | 基於極端增強的異常值檢測(監督) | 2018年 | [48] |
| 離群值集合 | 洛達 | 輕量級在線異常檢測器 | 2016年 | [34] |
| 離群值集合 | 蘇奧德 | SUOD:加速大規模無監督異構異常值偵測(加速) | 2021年 | [50] |
| 離群值集合 | 伊內 | 使用最近鄰整合的基於隔離的異常檢測 | 2018年 | [7] |
| 組合 | 平均的 | 透過平均分數進行簡單組合 | 2015年 | [2] |
| 組合 | 加權平均 | 透過將分數與偵測器權重進行平均來進行簡單組合 | 2015年 | [2] |
| 組合 | 最大化 | 透過取最大分數進行簡單組合 | 2015年 | [2] |
| 組合 | 澳奧姆 | 最大值的平均值 | 2015年 | [2] |
| 組合 | MOA | 平均值最大化 | 2015年 | [2] |
| 組合 | 中位數 | 透過取分數的中位數進行簡單組合 | 2015年 | [2] |
| 組合 | 多數票 | 透過獲得標籤的多數票進行簡單組合(可以使用權重) | 2015年 | [2] |
(iii) 實用函數:
| 類型 | 姓名 | 功能 | 文件 |
|---|
| 數據 | 產生數據 | 綜合數據生成;正常資料由多元高斯生成,異常值由均勻分佈生成 | 產生數據 |
| 數據 | 產生資料簇 | 集群中的綜合數據生成;可以使用多個叢集建立更複雜的資料模式 | 產生資料簇 |
| 統計數據 | 皮爾森 | 計算兩個樣本的加權皮爾遜相關性 | 皮爾森 |
| 公用事業 | 取得標籤n | 透過將 1 分配給前 n 個異常值分數,將原始異常值分數轉換為二進位標籤 | 取得標籤n |
| 公用事業 | precision_n_scores 精度 | 計算精度@等級n | precision_n_scores 精度 |
異常值檢測快速入門
PyOD 透過一些特色貼文和教程得到了機器學習社群的廣泛認可。
Analytics Vidhya :使用 PyOD 庫在 Python 中學習異常值檢測的精彩教程
KDnuggets :離群值偵測方法的直覺式視覺化,PyOD 離群值偵測方法概述
邁向資料科學:傻瓜式異常檢測
「examples/knn_example.py」示範了使用 kNN 偵測器的基本 API。值得注意的是,所有其他演算法的 API 都是一致/相似的。
有關運行範例的更詳細說明可以在範例目錄中找到。
初始化 kNN 偵測器、擬合模型並進行預測。
from pyod . models . knn import KNN # kNN detector
# train kNN detector
clf_name = 'KNN'
clf = KNN ()
clf . fit ( X_train )
# get the prediction label and outlier scores of the training data
y_train_pred = clf . labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf . decision_scores_ # raw outlier scores
# get the prediction on the test data
y_test_pred = clf . predict ( X_test ) # outlier labels (0 or 1)
y_test_scores = clf . decision_function ( X_test ) # outlier scores
# it is possible to get the prediction confidence as well
y_test_pred , y_test_pred_confidence = clf . predict ( X_test , return_confidence = True ) # outlier labels (0 or 1) and confidence in the range of [0,1]
透過 ROC 和 Precision @ Rank n (p@n) 評估預測。
from pyod . utils . data import evaluate_print
# evaluate and print the results
print ( " n On Training Data:" )
evaluate_print ( clf_name , y_train , y_train_scores )
print ( " n On Test Data:" )
evaluate_print ( clf_name , y_test , y_test_scores )
查看範例輸出和視覺化。
On Training Data :
KNN ROC : 1.0 , precision @ rank n : 1.0
On Test Data :
KNN ROC : 0.9989 , precision @ rank n : 0.9
visualize ( clf_name , X_train , y_train , X_test , y_test , y_train_pred ,
y_test_pred , show_figure = True , save_figure = False )
視覺化(knn_figure):
參考
| [1] | (1, 2) Aggarwal, CC, 2015。資料探勘(第 237-263 頁)。施普林格、查姆. |
| [2] | (1, 2, 3, 4, 5, 6, 7) Aggarwal, CC 和 Sathe, S., 2015。 ACM SIGKDD 探索通訊,17(1),第 24-47 頁。 |
| [3] | Aggarwal, CC 和 Sathe, S.,2017。施普林格。 |
| [4] | Almardeny, Y.、Boujnah, N. 和 Cleary, F.,2020。 IEEE 知識與資料工程彙刊。 |
| [5] | (1, 2) Angiulli, F. 與 Pizzuti, C.,2002 年 8 月。高維空間中的快速異常值檢測。歐洲資料探勘與知識發現原理會議,第 15-27 頁。 |
| [6] | Arning, A.、Agrawal, R. 與 Raghavan, P.,1996 年 8 月。大型資料庫中偏差檢測的線性方法。在KDD (第 1141 卷,第 50 期,第 972-981 頁)。 |
| [7] | (1, 2) Bandaragoda, TR、Ting, KM、Albrecht, D.、Liu, FT、Zhu, Y. 和 Wells, JR,2018,使用最近鄰整合的基於隔離的異常檢測。計算智能,34(4),第 968-998 頁。 |
| [8] | Breunig, MM、Kriegel, HP、Ng, RT 與 Sander, J.,2000 年 5 月。 LOF:識別基於密度的局部異常值。 ACM Sigmod 記錄,29(2),第 93-104 頁。 |
| [9] | 伯吉斯,克里斯多福·P.,等人。 “了解 beta-VAE 中的解纏結。” arXiv 預印本 arXiv:1804.03599 (2018)。 |
| [10] | Cook, RD, 1977。技術計量學,19(1),第 15-18 頁。 |
| [11] | Fang, KT 和 Ma, CX, 2001。複雜性雜誌,17(4),第 608-624 頁。 |
| [12] | Goldstein, M. 和 Dengel, A.,2012。在KI-2012:海報和示範軌道,第 59-63 頁。 |
| [13] | Goodge, A.、Hooi, B.、Ng, SK 與 Ng, WS,2022 年 6 月。 Lunar:透過圖神經網路統一局部異常值檢測方法。 AAAI 人工智慧會議論文集。 |
| [14] | Gopalan, P.、Sharan, V. 和 Wieder, U.,2019。 《神經資訊處理系統進展》,第 15783-15793 頁。 |
| [15] | Han, S.、Hu, X.、Huang, H.、Jiang, M. 和 Zhu, Y.,2022。 arXiv 預印本 arXiv:2206.09426。 |
| [16] | Hardin, J. 和 Rocke, DM, 2004。計算統計與資料分析,44(4),第 625-638 頁。 |
| [17] | He, Z.、Xu, X. 和 Deng, S.,2003。模式識別字母,24(9-10),第 1641-1650 頁。 |
| [18] | Hoffmann, H., 2007。模式識別,40(3),第 863-874 頁。 |
| [19] | Iglewicz, B. 和 Hoaglin, DC,1993。阿斯克出版社。 |
| [20] | Janssens, JHM、Huszár, F.、Postma, EO 和 van den Herik, HJ, 2012。技術報告 TiCC TR 2012-001,蒂爾堡大學蒂爾堡認知與溝通中心,荷蘭蒂爾堡。 |
| [21] | Kingma, DP 和 Welling, M.,2013。 arXiv 預印本 arXiv:1312.6114。 |
| [22] | (1, 2) Kriegel, HP 與 Zimek, A.,2008 年 8 月。高維度資料中基於角度的異常值檢測。在KDD '08 ,第 444-452 頁。 ACM。 |
| [23] | Kriegel, HP、Kröger, P.、Schubert, E. 與 Zimek, A.,2009 年 4 月。高維度資料軸平行子空間中的異常值偵測。載於亞太知識發現與資料探勘會議,第 831-838 頁。施普林格、柏林、海德堡。 |
| [24] | Latecki, LJ、Lazarevic, A. 與 Pokrajac, D.,2007 年 7 月。使用核密度函數進行離群值檢測。在模式識別中的機器學習和資料探勘國際研討會(第 61-75 頁)。施普林格、柏林、海德堡。 |
| [25] | (1, 2) Lazarevic, A. 和 Kumar, V.,2005 年 8 月。用於異常值檢測的特徵裝袋。在KDD '05中。 2005年。 |
| [26] | Li, D.、Chen, D.、Jin, B.、Shi, L.、Goh, J. 和 Ng, SK,2019 年 9 月。 MAD-GAN:使用生成對抗網路對時間序列資料進行多變量異常檢測。國際人工神經網路會議(第 703-716 頁)。施普林格、查姆. |
| [27] | Li, Z.、Zhao, Y.、Botta, N.、Ionescu, C. 和 Hu, X. COPOD:基於 Copula 的異常值檢測。 IEEE 國際資料探勘會議 (ICDM) ,2020 年。 |
| [28] | Li, Z.、Zhao, Y.、Hu, X.、Botta, N.、Ionescu, C. 和 Chen, HG ECOD:使用經驗累積分佈函數的無監督離群值檢測。 IEEE 知識與資料工程彙刊 (TKDE) ,2022 年。 |
| [29] | 劉 FT、丁 KM 和周 ZH,2008 年 12 月。隔離森林。國際資料探勘會議,第 413-422 頁。 IEEE。 |
| [30] | (1, 2) Liu, Y., Li, Z., Zhou, C., Jiang, Y., Sun, J., Wang, M. andHe, X., 2019。生成對抗主動學習。 IEEE 知識與資料工程彙刊。 |
| [31] | Nguyen,明尼蘇達州和 Vien,NA,2019 年。資料庫中的機器學習和知識發現:歐洲會議,ECML PKDD,2018 年。 |
| [32] | 龐冠松、沈春華和安東·範·登·亨格爾。 “利用偏差網路進行深度異常檢測。” 《KDD》 ,第 353-362 頁。 2019. |
| [33] | Papadimitriou, S.、Kitakawa, H.、Gibbons, PB 與 Faloutsos, C.,2003 年 3 月。 LOCI:使用局部相關積分進行快速異常值檢測。 ICDE '03 ,第 315-326 頁。 IEEE。 |
| [34] | (1, 2) Pevný, T., 2016。機器學習,102(2),第 275-304 頁。 |
| [35] | Perini, L.、Vercruyssen, V.、Davis, J. 量化異常檢測器在範例預測中的置信度。歐洲機器學習與資料庫知識發現聯合會議 (ECML-PKDD) ,2020 年。 |
| [36] | Ramaswamy, S.、Rastogi, R. 與 Shim, K.,2000 年 5 月。從大型資料集中挖掘異常值的有效演算法。 ACM Sigmod 記錄,29(2),第 427-438 頁。 |
| [37] | Rousseeuw, PJ 和 Driessen, KV,1999。技術計量學,41(3),第 212-223 頁。 |
| [38] | Ruff, L.、Vandereulen, R.、Goernitz, N.、Deecke, L.、Siddiqui, SA、Binder, A.、Müller, E. 和 Kloft, M.,2018 年 7 月。深度一類分類。國際機器學習會議(第 4393-4402 頁)。 PMLR。 |
| [39] | Schlegl, T.、Seeböck, P.、Waldstein, SM、Schmidt-Erfurth, U. 和 Langs, G.,2017 年 6 月。使用生成對抗網路進行無監督異常檢測,以指導標記發現。醫學影像資訊處理國際會議(第 146-157 頁)。施普林格、查姆. |
| [40] | Scholkopf, B.、Platt, JC、Shawe-Taylor, J.、Smola, AJ 和 Williamson, RC,2001。神經計算,13(7),第 1443-1471 頁。 |
| [41] | Shyu, ML, Chen, SC, Sarinnapakorn, K. and Chang, L., 2003。佛羅裡達州科勒爾蓋布爾斯邁阿密大學電機與電腦工程系。 |
| [42] | Sugiyama, M. 和 Borgwardt, K.,2013。神經資訊處理系統的進展,26。 |
| [43] | (1, 2)唐俊、陳志、傅 AWC 和張 DW,2002 年 5 月。增強低密度模式異常值檢測的效能。載於亞太知識發現與資料探勘會議,第 535-548 頁。施普林格、柏林、海德堡。 |
| [44] | Wang, X., Du, Y., Lin, S., Cui, P., Shen, Y. and Yang, Y., 2019。 ,用於異常檢測。基於知識的系統。 |
| [45] | Xu, H., Pang, G., Wang, Y., Wang, Y., 2023。 IEEE 知識與資料工程彙刊。 |
| [46] | You, C.、Robinson, DP 和 Vidal, R.,2017。 IEEE 電腦視覺與模式辨識會議論文集。 |
| [47] | Zenati, H.、Romain, M.、Foo, CS、Lecouat, B. 與 Chandrasekhar, V.,2018 年 11 月。對抗性學習異常檢測。 2018 年 IEEE 國際資料探勘會議 (ICDM)(第 727-736 頁)。 IEEE。 |
| [48] | (1, 2) Zhao, Y. 和 Hryniewicki,MK XGBOD:透過無監督表示學習改進有監督異常值檢測。 IEEE 國際神經網路聯合會議,2018。 |
| [49] | (1, 2)趙 Y.、納斯魯拉 Z.、Hryniewicki, MK 和李 Z.,2019 年 5 月。 LSCP:並行異常值集合中的局部選擇性組合。 2019 年 SIAM 國際資料探勘會議 (SDM) 論文集,第 585-593 頁。工業與應用數學學會。 |
| [50] | (1,2,3,4)趙Y.,胡X.,程C.,王C.,萬C.,王W.,楊J.,白H.,李,Z.,肖,C. ,王,Y.,喬,Z.,孫,J.和阿科格魯,L.(2021)。 SUOD:加速大規模無監督異質異常值偵測。機器學習和系統會議(MLSys) 。 |


