vaex
Version linked to the paper
Vaex 是一個高效能 Python 函式庫,用於惰性外核資料幀(類似於 Pandas),用於視覺化和探索大型表格資料集。它在N 維網格上每秒計算超過十億( 10^9 )個樣本/行的統計數據,例如平均值、總和、計數、標準差等。視覺化是使用直方圖、密度圖和3D 體積渲染完成的,允許對大數據進行互動式探索。 Vaex 使用記憶體映射、零記憶體複製策略和惰性計算來實現最佳效能(不浪費記憶體)。
用點:
$ pip install vaex
或康達:
$ conda install -c conda-forge vaex
有關更多詳細信息,請參閱文檔
支援 HDF5 和 Apache Arrow。

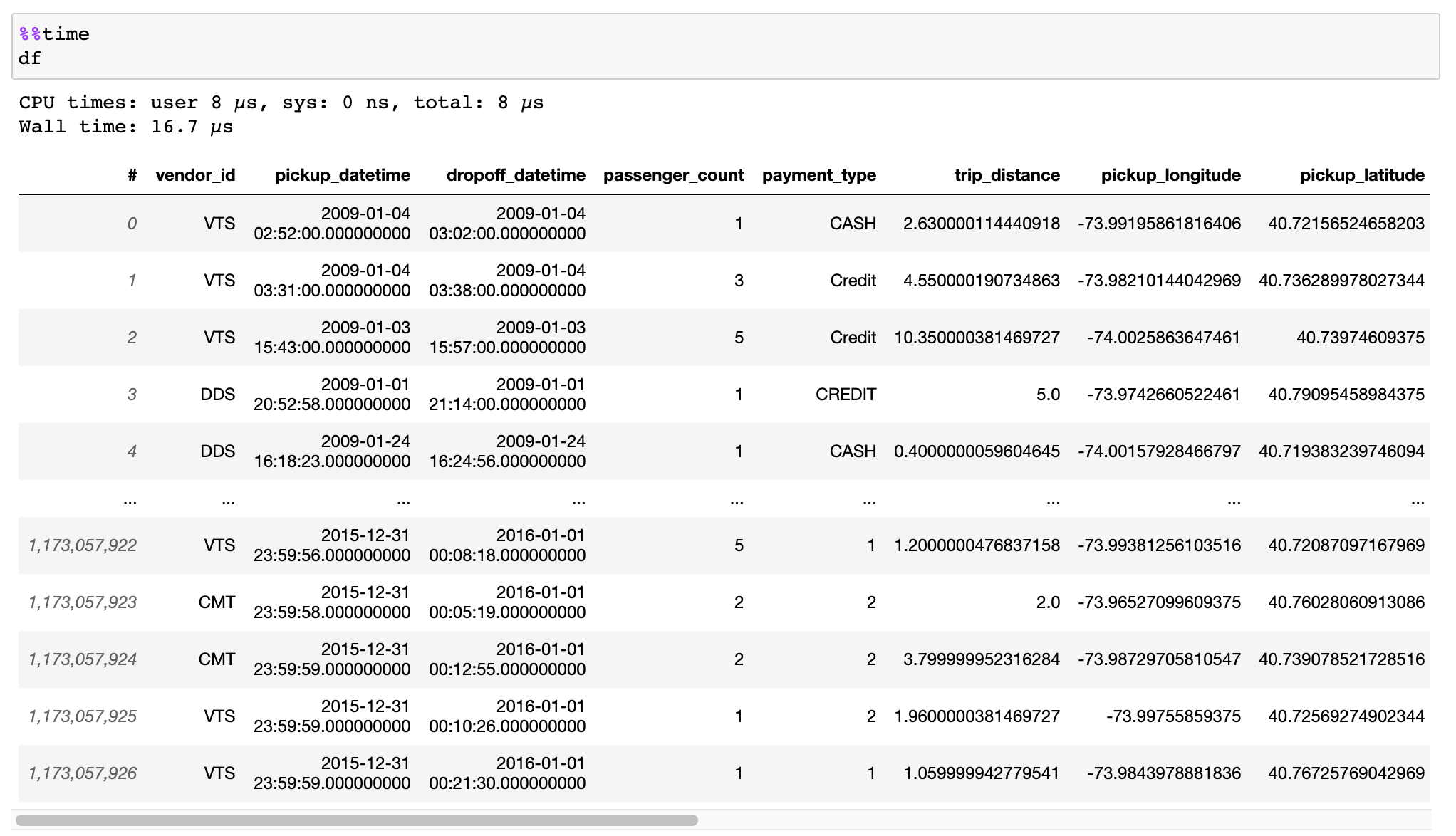
閱讀有關如何有效率地轉換來自 CSV 檔案、Pandas DataFrame 或其他來源的資料的文件。
支援來自 S3 的延遲流與記憶體映射結合。

不要在特徵工程上浪費記憶體或時間,我們會在需要時(懶惰地)轉換您的資料。
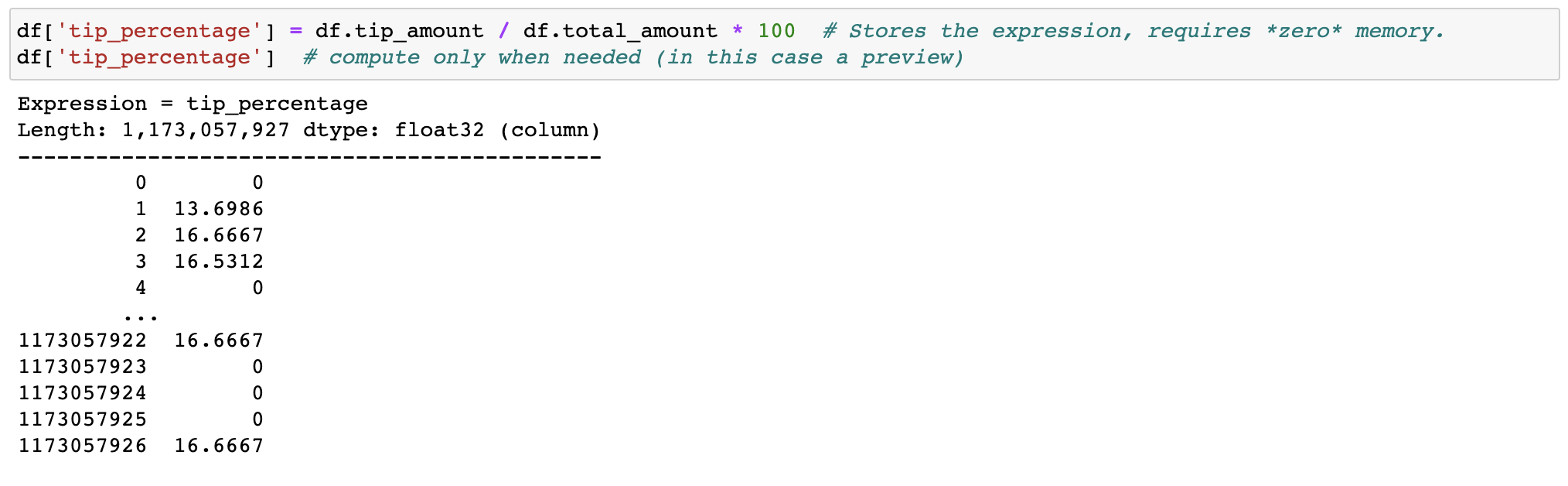
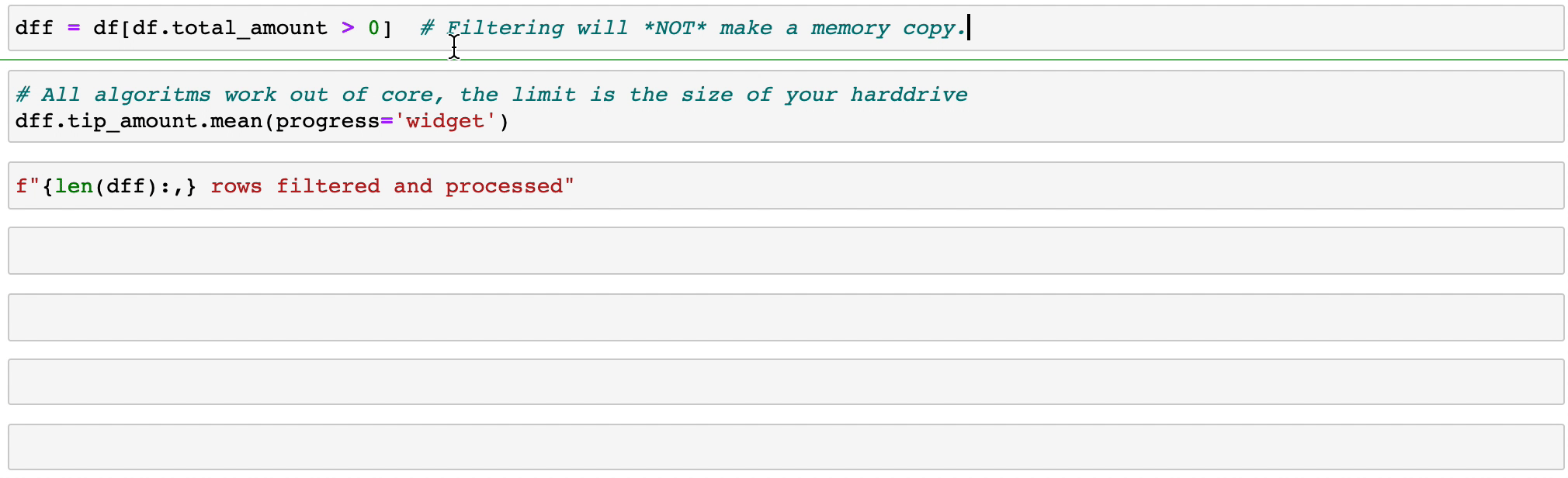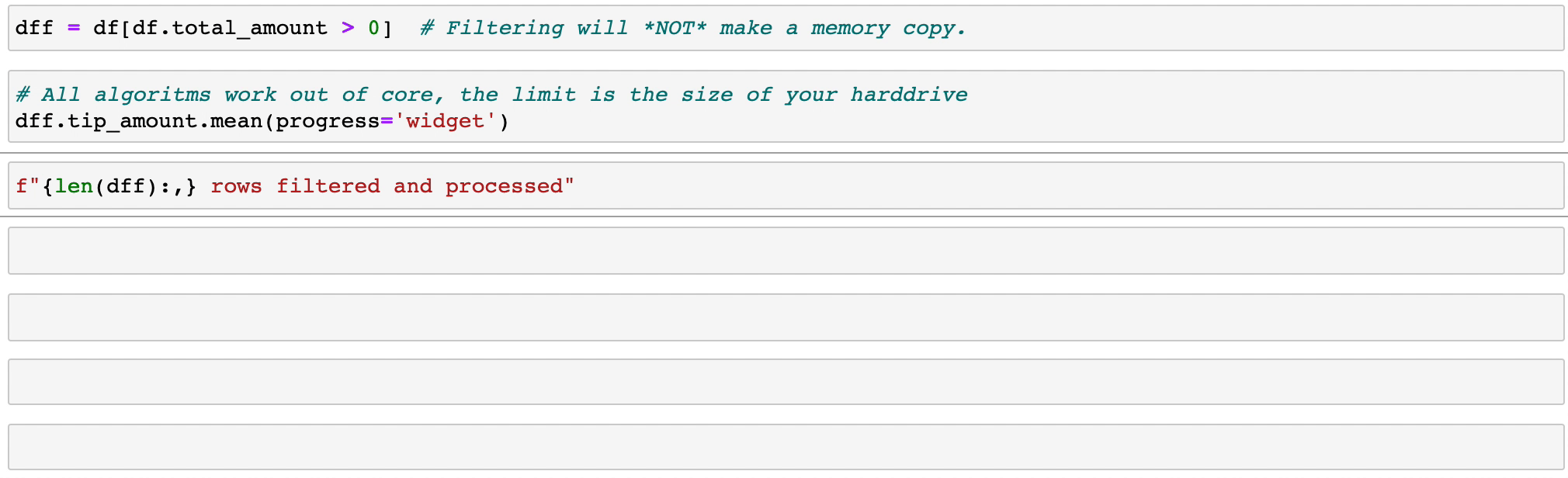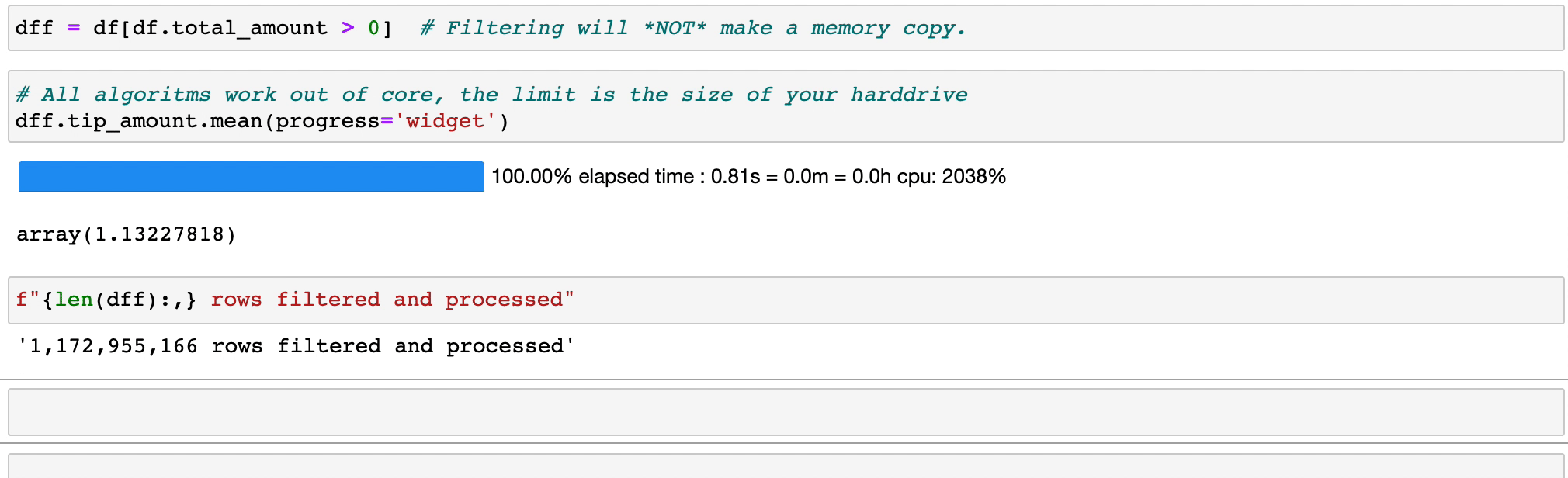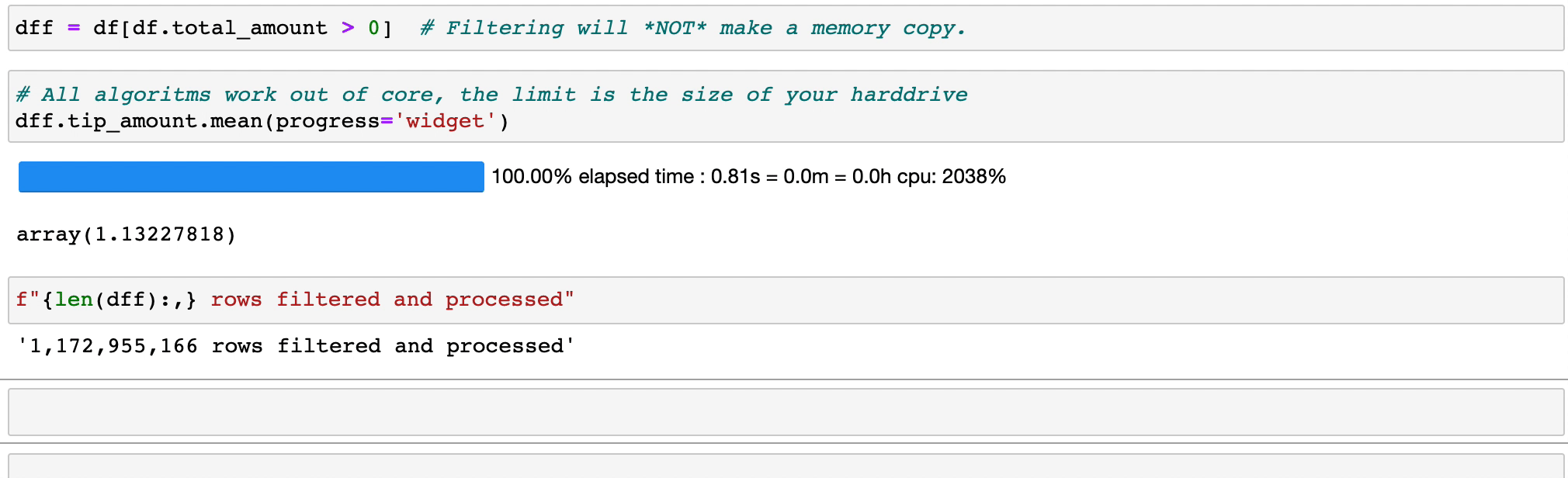
過濾和求值表達式不會因為複製而浪費記憶體;資料在磁碟上保持不變,並且僅在需要時進行串流傳輸。延遲需要集群之前的時間。
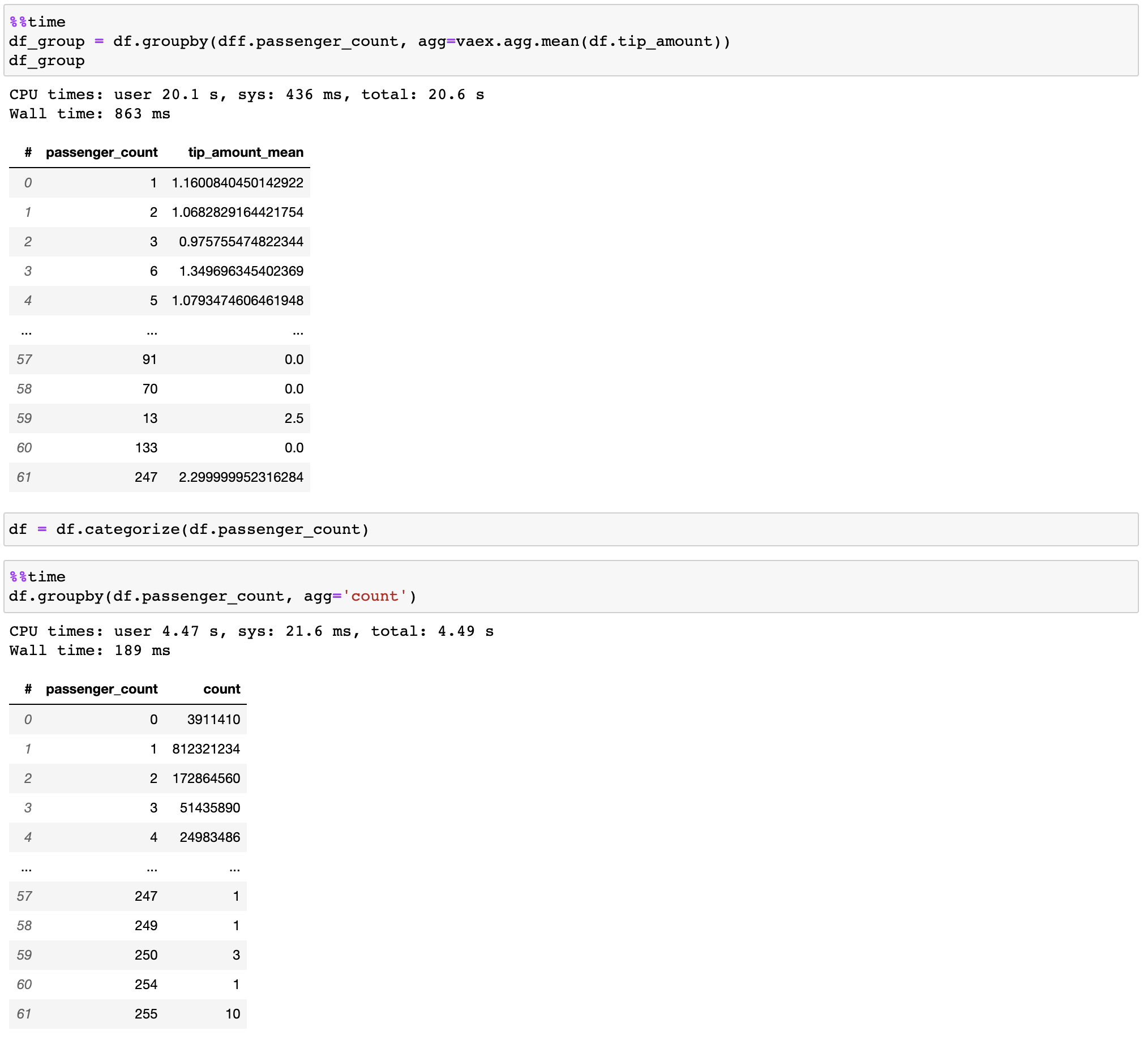
Vaex 實現並行、高效能的groupby操作,特別是在使用類別時(> 10 億/秒)。
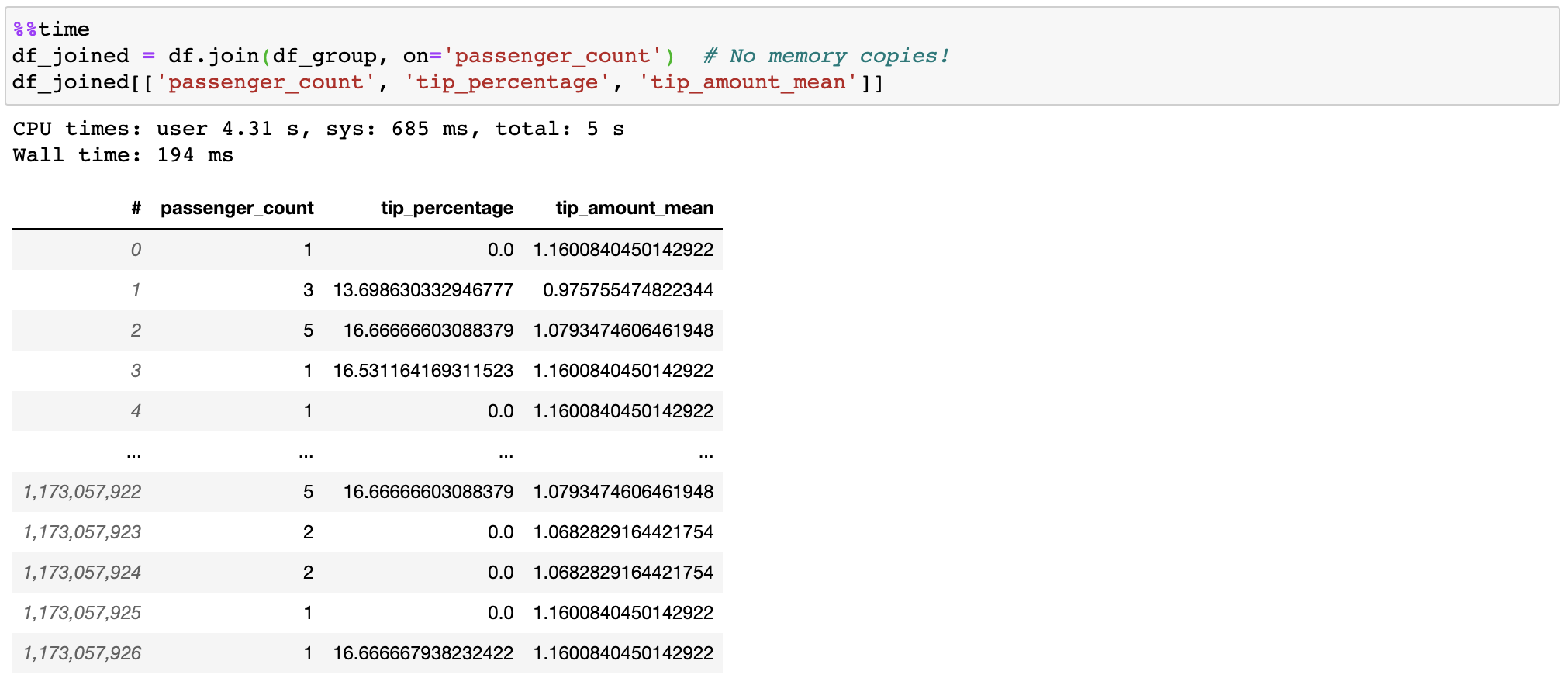
Vaex 在加入時不會複製/具體化「正確」的表,從而節省了千兆位元組的記憶體。透過亞秒連接十億行,速度相當快!
請參閱貢獻頁面。
加入我們的 Slack 頻道中的討論!
文章
按照我們的教學進行操作
觀看我們最近的演講:
請聯絡我們以取得數據科學解決方案、培訓或企業支援:https://vaex.io/


