stumpy
v1.13.0

STUMPY 是一個強大且可擴展的Python 庫,它可以有效地計算稱為矩陣輪廓的東西,這只是一種學術說法,即「對於時間序列中的每個(綠色)子序列,自動識別其相應的最近鄰居(灰色)」:
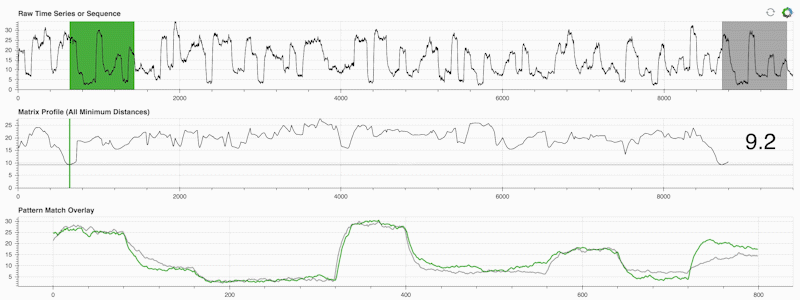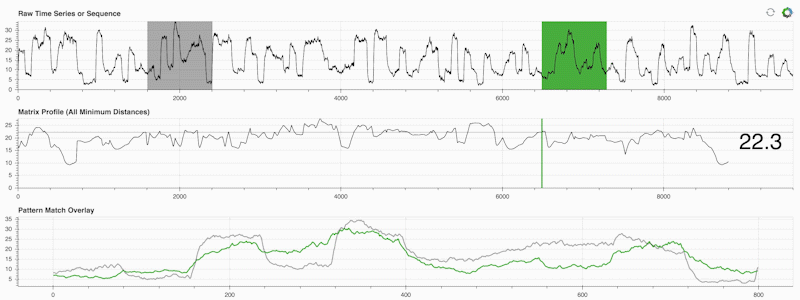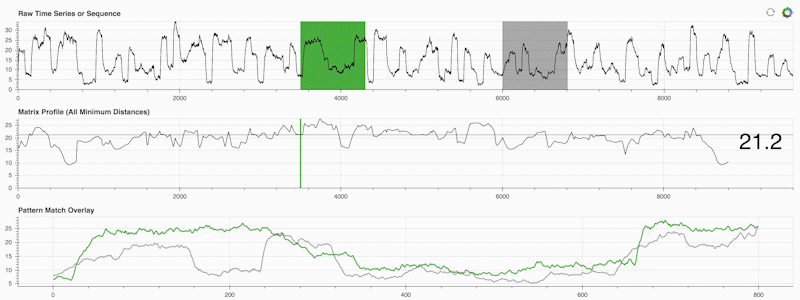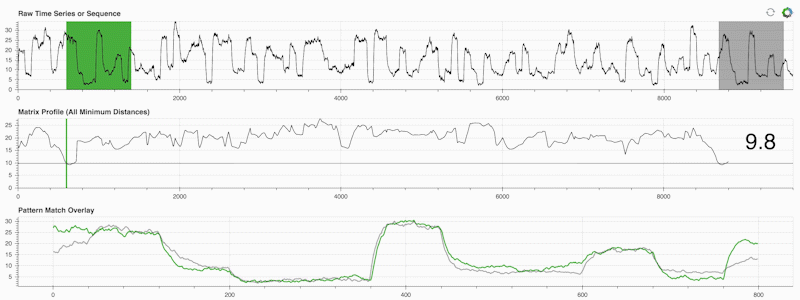
重要的是,一旦計算出矩陣輪廓(上面的中間面板),它就可以用於各種時間序列資料探勘任務,例如:
無論您是學者、資料科學家、軟體開發人員或時間序列愛好者,STUMPY 的安裝都很簡單,我們的目標是讓您更快獲得時間序列見解。請參閱文件以取得更多資訊。
請參閱我們的 API 文件以獲取可用函數的完整列表,並參閱我們的資訊教學課程以取得更全面的範例用例。下面,您將找到快速示範如何使用 STUMPY 的程式碼片段。
STUMP 的典型用法(一維時間序列資料):
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )透過 STUMPED 使用 Dask 分佈式使用一維時間序列資料:
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stumped ( dask_client , your_time_series , m = window_size )使用 GPU-STUMP 處理一維時間序列資料的 GPU 使用:
import stumpy
import numpy as np
from numba import cuda
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
all_gpu_devices = [ device . id for device in cuda . list_devices ()] # Get a list of all available GPU devices
matrix_profile = stumpy . gpu_stump ( your_time_series , m = window_size , device_id = all_gpu_devices )使用MSTUMP的多維時間序列資料:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstump ( your_time_series , m = window_size )使用Dask Distributed MSTUMPED進行分散式多維時間序列資料分析:
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstumped ( dask_client , your_time_series , m = window_size )具有錨定時間序列鏈 (ATSC) 的時間序列鏈:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
left_matrix_profile_index = matrix_profile [:, 2 ]
right_matrix_profile_index = matrix_profile [:, 3 ]
idx = 10 # Subsequence index for which to retrieve the anchored time series chain for
anchored_chain = stumpy . atsc ( left_matrix_profile_index , right_matrix_profile_index , idx )
all_chain_set , longest_unanchored_chain = stumpy . allc ( left_matrix_profile_index , right_matrix_profile_index )使用快速低成本單能語意分割 (FLUSS) 進行語意分割:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
subseq_len = 50
correct_arc_curve , regime_locations = stumpy . fluss ( matrix_profile [:, 1 ],
L = subseq_len ,
n_regimes = 2 ,
excl_factor = 1
)支援的 Python 和 NumPy 版本根據 NEP 29 棄用政策確定。
Conda 安裝(首選):
conda install -c conda-forge stumpyPyPI 安裝,假設您安裝了 numpy、scipy 和 numba:
python -m pip install stumpy若要從來源安裝 Stumpy,請參閱文件中的說明。
為了充分理解和欣賞底層演算法和應用程序,您必須閱讀原始出版物。有關如何使用 STUMPY 的更詳細範例,請查閱最新文件或瀏覽我們的實作教學。
我們測試了使用 Numba JIT 編譯版本的程式碼對隨機產生的不同長度的時間序列資料(即np.random.rand(n) )以及不同的 CPU 和 GPU 硬體資源計算精確矩陣設定檔的效能。
原始結果在下表中顯示為小時:分鐘:秒.毫秒,視窗大小恆定為 m = 50。您可能需要捲動到表的右側才能查看所有執行時間。
| 我 | n = 2我 | GPU-STOMP | 樹樁.2 | 樹樁.16 | 難住了.128 | 難住了.256 | GPU-STUMP.1 | GPU-STUMP.2 | GPU-STUMP.DGX1 | GPU-STUMP.DGX2 |
|---|---|---|---|---|---|---|---|---|---|---|
| 6 | 64 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.77 | 00:00:06.08 | 00:00:00.03 | 00:00:01.63 | 南 | 南 |
| 7 | 128 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.93 | 00:00:07.29 | 00:00:00.04 | 00:00:01.66 | 南 | 南 |
| 8 | 256 | 00:00:10.00 | 00:00:00.00 | 00:00:00.01 | 00:00:05.95 | 00:00:07.59 | 00:00:00.08 | 00:00:01.69 | 00:00:06.68 | 00:00:25.68 |
| 9 | 第512章 | 00:00:10.00 | 00:00:00.00 | 00:00:00.02 | 00:00:05.97 | 00:00:07.47 | 00:00:00.13 | 00:00:01.66 | 00:00:06.59 | 00:00:27.66 |
| 10 | 1024 | 00:00:10.00 | 00:00:00.02 | 00:00:00.04 | 00:00:05.69 | 00:00:07.64 | 00:00:00.24 | 00:00:01.72 | 00:00:06.70 | 00:00:30.49 |
| 11 | 2048 | 南 | 00:00:00.05 | 00:00:00.09 | 00:00:05.60 | 00:00:07.83 | 00:00:00.53 | 00:00:01.88 | 00:00:06.87 | 00:00:31.09 |
| 12 | 4096 | 南 | 00:00:00.22 | 00:00:00.19 | 00:00:06.26 | 00:00:07.90 | 00:00:01.04 | 00:00:02.19 | 00:00:06.91 | 00:00:33.93 |
| 13 | 8192 | 南 | 00:00:00.50 | 00:00:00.41 | 00:00:06.29 | 00:00:07.73 | 00:00:01.97 | 00:00:02.49 | 00:00:06.61 | 00:00:33.81 |
| 14 | 16384 | 南 | 00:00:01.79 | 00:00:00.99 | 00:00:06.24 | 00:00:08.18 | 00:00:03.69 | 00:00:03.29 | 00:00:07.36 | 00:00:35.23 |
| 15 | 32768 | 南 | 00:00:06.17 | 00:00:02.39 | 00:00:06.48 | 00:00:08.29 | 00:00:07.45 | 00:00:04.93 | 00:00:07.02 | 00:00:36.09 |
| 16 | 65536 | 南 | 00:00:22.94 | 00:00:06.42 | 00:00:07.33 | 00:00:09.01 | 00:00:14.89 | 00:00:08.12 | 00:00:08.10 | 00:00:36.54 |
| 17 號 | 131072 | 00:00:10.00 | 00:01:29.27 | 00:00:19.52 | 00:00:09.75 | 00:00:10.53 | 00:00:29.97 | 00:00:15.42 | 00:00:09.45 | 00:00:37.33 |
| 18 | 262144 | 00:00:18.00 | 00:05:56.50 | 00:01:08.44 | 00:00:33.38 | 00:00:24.07 | 00:00:59.62 | 00:00:27.41 | 00:00:13.18 | 00:00:39.30 |
| 19 | 524288 | 00:00:46.00 | 00:25:34.58 | 00:03:56.82 | 00:01:35.27 | 00:03:43.66 | 00:01:56.67 | 00:00:54.05 | 00:00:19.65 | 00:00:41.45 |
| 20 | 1048576 | 00:02:30.00 | 01:51:13.43 | 00:19:54.75 | 00:04:37.15 | 00:03:01.16 | 00:05:06.48 | 00:02:24.73 | 00:00:32.95 | 00:00:46.14 |
| 21 | 2097152 | 00:09:15.00 | 09:25:47.64 | 03:05:07.64 | 00:13:36.51 | 00:08:47.47 | 00:20:27.94 | 00:09:41.43 | 00:01:06.51 | 00:01:02.67 |
| 22 | 4194304 | 南 | 36:12:23.74 | 10:37:51.21 | 00:55:44.43 | 00:32:06.70 | 01:21:12.33 | 00:38:30.86 | 00:04:03.26 | 00:02:23.47 |
| 23 | 8388608 | 南 | 143:16:09.94 | 38:42:51.42 | 03:33:30.53 | 02:00:49.37 | 05:11:44.45 | 02:33:14.60 | 00:15:46.26 | 00:08:03.76 |
| 24 | 16777216 | 南 | 南 | 南 | 14:39:11.99 | 07:13:47.12 | 20:43:03.80 | 09:48:43.42 | 01:00:24.06 | 00:29:07.84 |
| 南 | 17729800 | 09:16:12.00 | 南 | 南 | 15:31:31.75 | 07:18:42.54 | 23:09:22.43 | 10:54:08.64 | 01:07:35.39 | 00:32:51.55 |
| 25 | 33554432 | 南 | 南 | 南 | 56:03:46.81 | 26:27:41.29 | 83:29:21.06 | 39:17:43.82 | 03:59:32.79 | 01:54:56.52 |
| 26 | 67108864 | 南 | 南 | 南 | 211:17:37.60 | 106:40:17.17 | 328:58:04.68 | 157:18:30.50 | 15:42:15.94 | 07:18:52.91 |
| 南 | 100000000 | 291:07:12.00 | 南 | 南 | 南 | 234:51:35.39 | 南 | 南 | 35:03:44.61 | 16:22:40.81 |
| 27 | 134217728 | 南 | 南 | 南 | 南 | 南 | 南 | 南 | 64:41:55.09 | 29:13:48.12 |
GPU-STOMP:這些結果來自原始 Matrix Profile II 論文 - NVIDIA Tesla K80(包含 2 個 GPU),並作為效能基準進行比較。
STUMP.2:stumpy.stump 總共使用 2 個 CPU 執行 - 2 個 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 處理器,在沒有 Dask 的單一伺服器上與 Numba 並行。
STUMP.16:stumpy.stump 總共使用 16 個 CPU 執行 - 16 個 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 處理器,在沒有 Dask 的單一伺服器上與 Numba 並行。
STUMPED.128:stumpy.stumped 總共使用 128 個 CPU 執行 - 8 個 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 處理器 x 16 個伺服器,與 Numba 並行,並使用 Dask Distributed 進行分發。
STUMPED.256:stumpy.stumped 總共使用 256 個 CPU 執行 - 8 個 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 處理器 x 32 個伺服器,與 Numba 並行,並使用 Dask Distributed 進行分發。
GPU-STUMP.1:stumpy.gpu_stump 使用 1x NVIDIA GeForce GTX 1080 Ti GPU 執行,每塊 512 個線程,200W 功率限制,使用 Numba 編譯為 CUDA,並使用 Python 多處理並行化
GPU-STUMP.2:stumpy.gpu_stump 使用 2 個 NVIDIA GeForce GTX 1080 Ti GPU 執行,每塊 512 個線程,200W 功率限制,使用 Numba 編譯為 CUDA,並使用 Python 多處理並行化
GPU-STUMP.DGX1:stumpy.gpu_stump 使用 8x NVIDIA Tesla V100 執行,每塊 512 個線程,使用 Numba 編譯為 CUDA,並使用 Python 多處理並行化
GPU-STUMP.DGX2:stumpy.gpu_stump 使用 16x NVIDIA Tesla V100 執行,每塊 512 個線程,使用 Numba 編譯為 CUDA,並使用 Python 多處理並行化
測試編寫在tests目錄中並使用 PyTest 進行處理,並且需要coverage.py進行程式碼覆蓋率分析。可以透過以下方式執行測試:
./test.shSTUMPY 支援 Python 3.9+,由於使用 unicode 變數名稱/標識符,與 Python 2.x 不相容。鑑於依賴性較小,STUMPY 可能可以在舊版本的 Python 上運行,但這超出了我們的支援範圍,我們強烈建議您升級到最新版本的 Python。
首先,請檢查 Github 上的討論和問題,看看您的問題是否已經得到解答。如果沒有可用的解決方案,請隨時提出新的討論或問題,作者將嘗試以合理及時的方式回應。
我們歡迎任何形式的貢獻!始終歡迎文件方面的幫助,特別是擴展教程。要做出貢獻,請分叉該項目,進行更改並提交拉取請求。我們將盡力與您解決任何問題,並將您的程式碼合併到主分支中。
如果您已在科學出版物中使用此程式碼庫並希望引用它,請使用開源軟體雜誌文章。
SM 法,(2019)。 STUMPY:用於時間序列資料探勘的強大且可擴展的 Python 函式庫。開源軟體雜誌,4(39), 1504。
@article { law2019stumpy ,
author = { Law, Sean M. } ,
title = { {STUMPY: A Powerful and Scalable Python Library for Time Series Data Mining} } ,
journal = { {The Journal of Open Source Software} } ,
volume = { 4 } ,
number = { 39 } ,
pages = { 1504 } ,
year = { 2019 }
}是的,Chin-Chia Michael 等人。 (2016) 矩陣設定檔 I:時間序列的所有對相似性連接:包括 Motifs、Discords 和 Shapelet 的統一視圖。 ICDM:1317-1322。關聯
朱彥等人。 (2016) Matrix Profile II:利用新穎的演算法和 GPU 突破時間序列主題和連結的一億個障礙。 ICDM:739-748。關聯
是的,Chin-Chia Michael 等人。 (2017) 矩陣剖面 VI:有意義的多維主題發現。 ICDM:565-574。關聯
朱彥等人。 (2017) 矩陣簡介 VII:時間序列鏈:時間序列資料探勘的新原語。 ICDM:695-704。關聯
加爾加比、沙加耶格等人。 (2017) 矩陣簡介 VIII:超人表現水準的領域不可知線上語意分割。 ICDM:117-126。關聯
朱彥等人。 (2017) 利用新穎的演算法和 GPU 打破時間序列主題和連結的 10 個千萬億的成對比較障礙。凱斯:203-236。關聯
朱彥等人。 (2018) 矩陣概要 XI:SCRIMP++:互動速度的時間序列基序發現。 ICDM:837-846。關聯
是的,Chin-Chia Michael 等人。 (2018) 時間序列連結、主題、不和諧與 Shapelet:利用矩陣輪廓的統一視圖。資料最小知識光碟:83-123。關聯
加爾加比、沙加耶格等人。 (2018)“矩陣概要 XII:MPdist:一種新穎的時間序列距離測量,可在更具挑戰性的場景中進行資料探勘。” ICDM:965-970。關聯
齊默曼、札卡里等人。 (2019) Matrix Profile XIV:使用 GPU 擴展時間序列基序發現,每天突破數十億次配對比較。 SoCC '19:74-86。關聯
阿克巴里尼亞、禮薩和貝特蘭德·克洛茲。 (2019) 使用不同距離函數的高效率矩陣輪廓計算。 arXiv:1901.05708。關聯
卡姆加爾、卡維等人。 (2019) 矩陣剖面 XV:利用時間序列共識模式來找出時間序列集中的結構。 ICDM:1156-1161。關聯


