3DDFA
1.0.0
郭建柱.

[更新]
2022.5.14 :推薦一個人臉分析的Python實作:face_pose_augmentation。2020.8.30 :ECCV-20的預訓練模型和代碼在3DDFA_V2上公開,版權由郭建柱和CBSR組解釋。2020.8.2 :更新該專案的簡單c++連接埠。2020.7.3 : 擴展工作Towards Fast, Accuracy and Stable 3D Dense Face Alignment被ECCV 2020接受。2019.9.15 :一些更新,詳細資訊請參閱提交。2019.6.17 : 新增 zjjMaiMai 貢獻的影片示範。2019.5.2 :使用 PyTorch v1.1.0 評估 CPU 的推理速度,請參閱此處和 speed_cpu.py。2019.4.27 :一個簡單的渲染管道,以約 25 毫秒/幀(720p)的速度運行,有關更多詳細信息,請參閱rendering.py。2019.4.24 : 提供obama的demo構建,更多詳情請參見demo@obama/readme.md。2019.3.28 :一些更新。2018.12.23 :新增幾個功能:深度影像估計、PNCC、PAF 功能和 obj 序列化。有關更多詳細信息,請參閱dump_depth 、 dump_pncc 、 dump_paf 、 dump_obj選項。2018.12.2 :支援無地標人臉裁剪,請參閱dlib_landmark選項。2018.12.1 :完善程式碼並新增姿態估計功能,請參閱 utils/estimate_pose.py 以了解更多詳細資訊。2018.11.17 : 最佳化程式碼並將 3d 頂點映射到原始影像空間。2018.11.11 :更新端對端推理管道:根據一張任意圖像推斷/序列化 3D 人臉形狀和 68 個地標,請參閱下面的 readme.md 以了解更多詳細資訊。2018.10.4 : 在視覺化中加入Matlab面網格渲染示範。2018.9.9 : 在 benchmark 中加入臉部裁切的預處理。[多]
該倉庫包含論文的 pytorch 改進版本:全姿勢範圍內的臉部對齊:3D 整體解決方案。新增了原始論文以外的幾項工作,包括即時訓練、訓練策略。因此,這個 repo 是原始作品的改良版。目前,該倉庫發布了MobileNet-V1結構的預訓練第一階段pytorch模型、預處理的訓練和測試資料集以及程式碼庫。請注意,在 GeForce GTX TITAN X 上,每個影像的推理時間約為 0.27 毫秒(輸入批次為 128 個影像作為輸入批次)。
本項目將在業餘時間持續更新,歡迎提出任何有意義的問題和 PR。
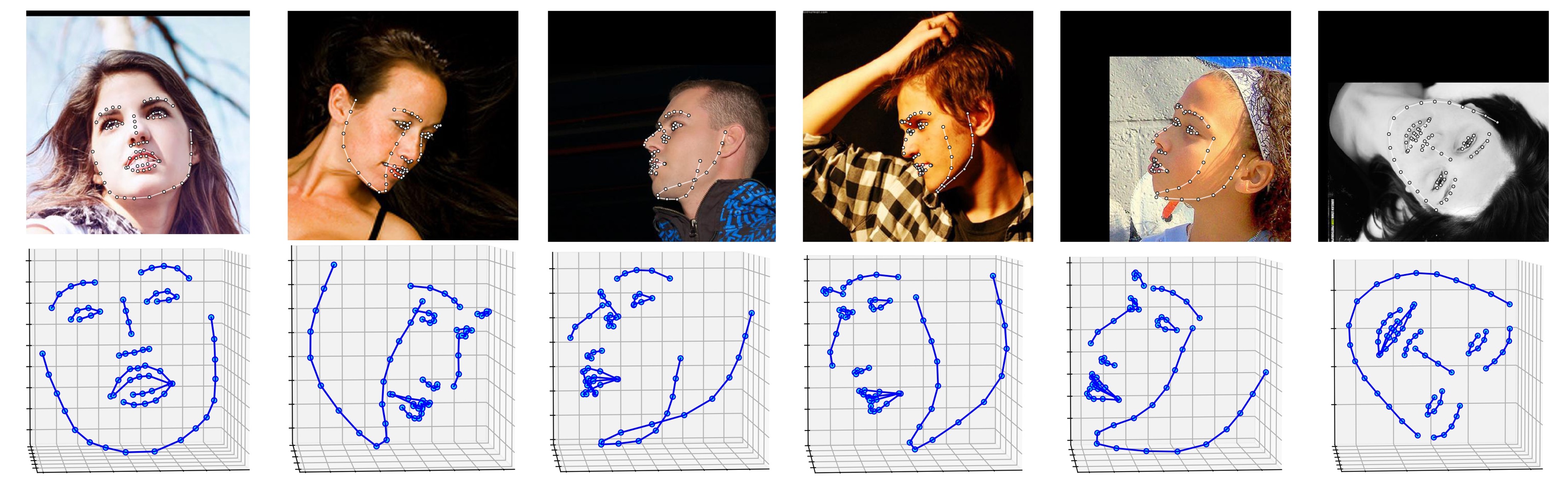
ALFW-2000 資料集上的幾個結果(從模型Phase1_wpdc_vdc.pth.tar推斷)如下所示。





# installation structions
sudo pip3 install torch torchvision # for cpu version. more option to see https://pytorch.org
sudo pip3 install numpy scipy matplotlib
sudo pip3 install dlib==19.5.0 # 19.15+ version may cause conflict with pytorch in Linux, this may take several minutes. If 19.5 version raises errors, you may try 19.15+ version.
sudo pip3 install opencv-python
sudo pip3 install cython
另外,我強烈建議使用Python3.6+而不是舊版本,因為它有更好的設計。
克隆此存儲庫(這可能需要一些時間,因為它有點大)
git clone https://github.com/cleardusk/3DDFA.git # or [email protected]:cleardusk/3DDFA.git
cd 3DDFA
然後,在Google Drive或百度雲中下載dliblandmark預訓練模型,並將其放入models目錄中。 (為了減小此存儲庫的大小,我刪除了一些包括此模型在內的大尺寸二進位文件,因此您應該下載它:))
建置 cython 模組(只需一行即可建置)
cd utils/cython
python3 setup.py build_ext -i
這是為了加速深度估計和 PNCC 渲染,因為 Python 在 for 迴圈中太慢。
使用任意圖像作為輸入運行main.py
python3 main.py -f samples/test1.jpg
如果您可以在終端機中看到這些輸出,則表示運行成功。
Dump tp samples/test1_0.ply
Save 68 3d landmarks to samples/test1_0.txt
Dump obj with sampled texture to samples/test1_0.obj
Dump tp samples/test1_1.ply
Save 68 3d landmarks to samples/test1_1.txt
Dump obj with sampled texture to samples/test1_1.obj
Dump to samples/test1_pose.jpg
Dump to samples/test1_depth.png
Dump to samples/test1_pncc.png
Save visualization result to samples/test1_3DDFA.jpg
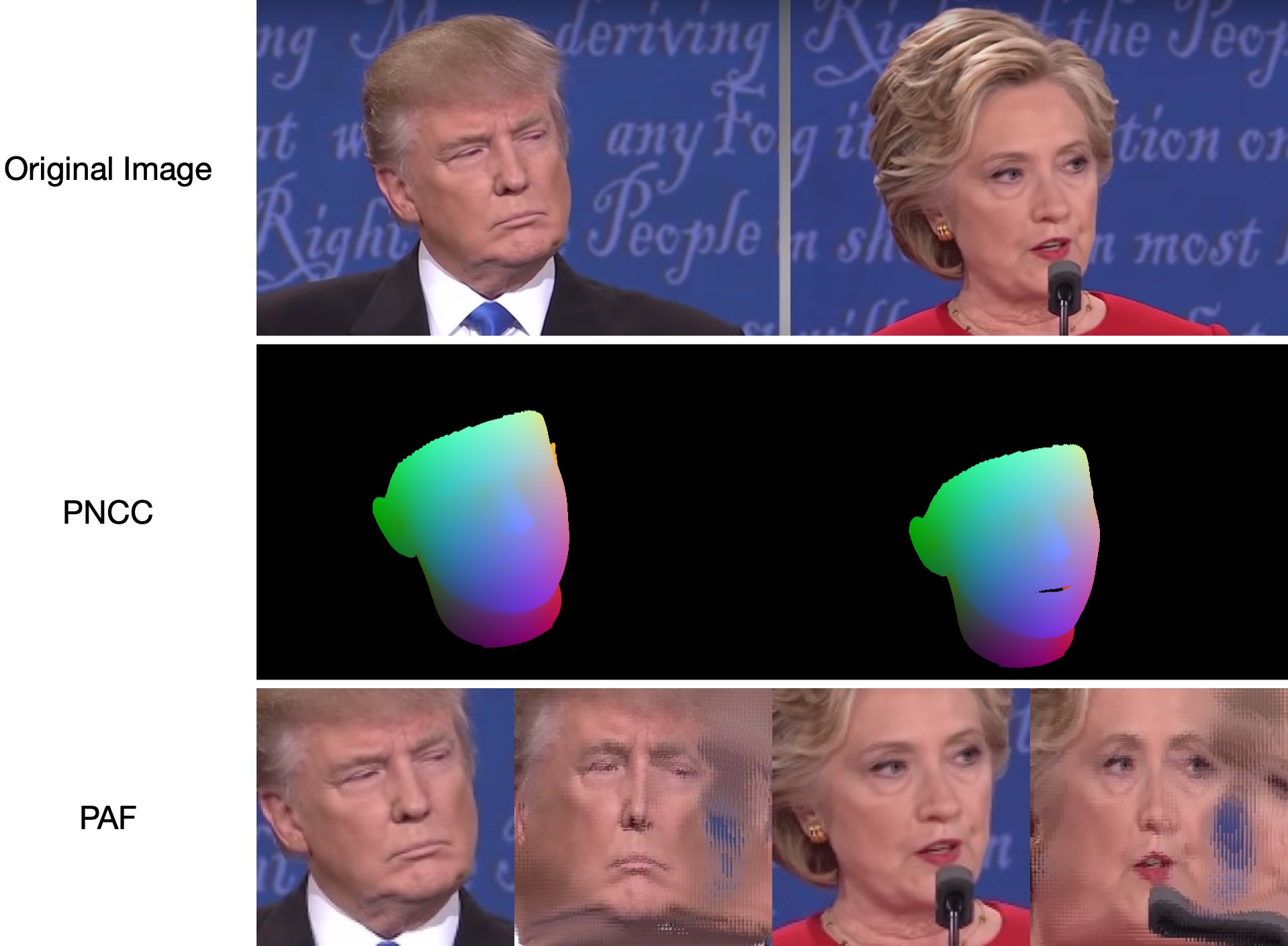
由於test1.jpg有兩個面,因此預測有兩個.ply和.obj檔案(可以透過 Meshlab 或 Microsoft 3D Builder 渲染)。深度、PNCC、PAF 和位姿估計均預設為 true。請執行python3 main.py -h或查看程式碼以了解更多詳細資訊。
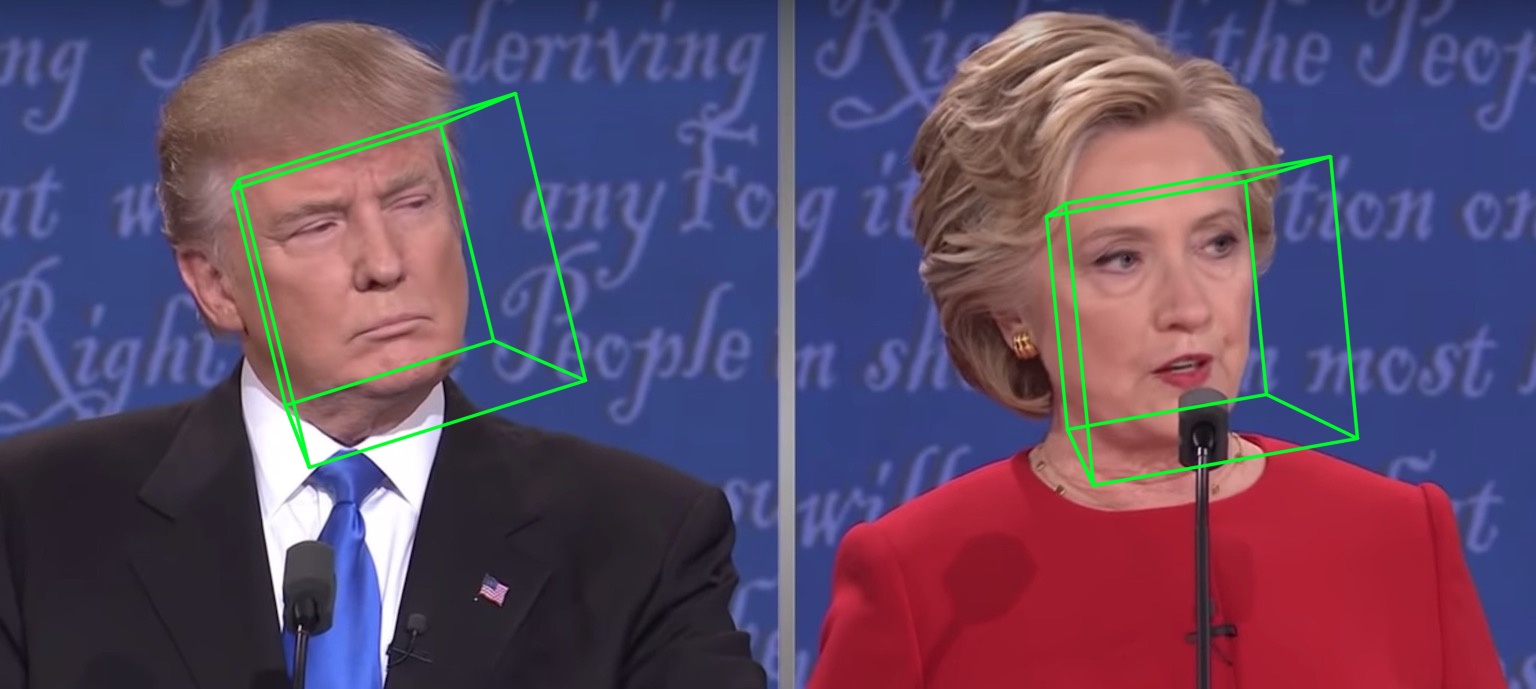
68個地標視覺化結果samples/test1_3DDFA.jpg和姿態估計結果samples/test1_pose.jpg如下圖所示:

附加範例
python3 ./main.py -f samples/emma_input.jpg --bbox_init=two --dlib_bbox=false
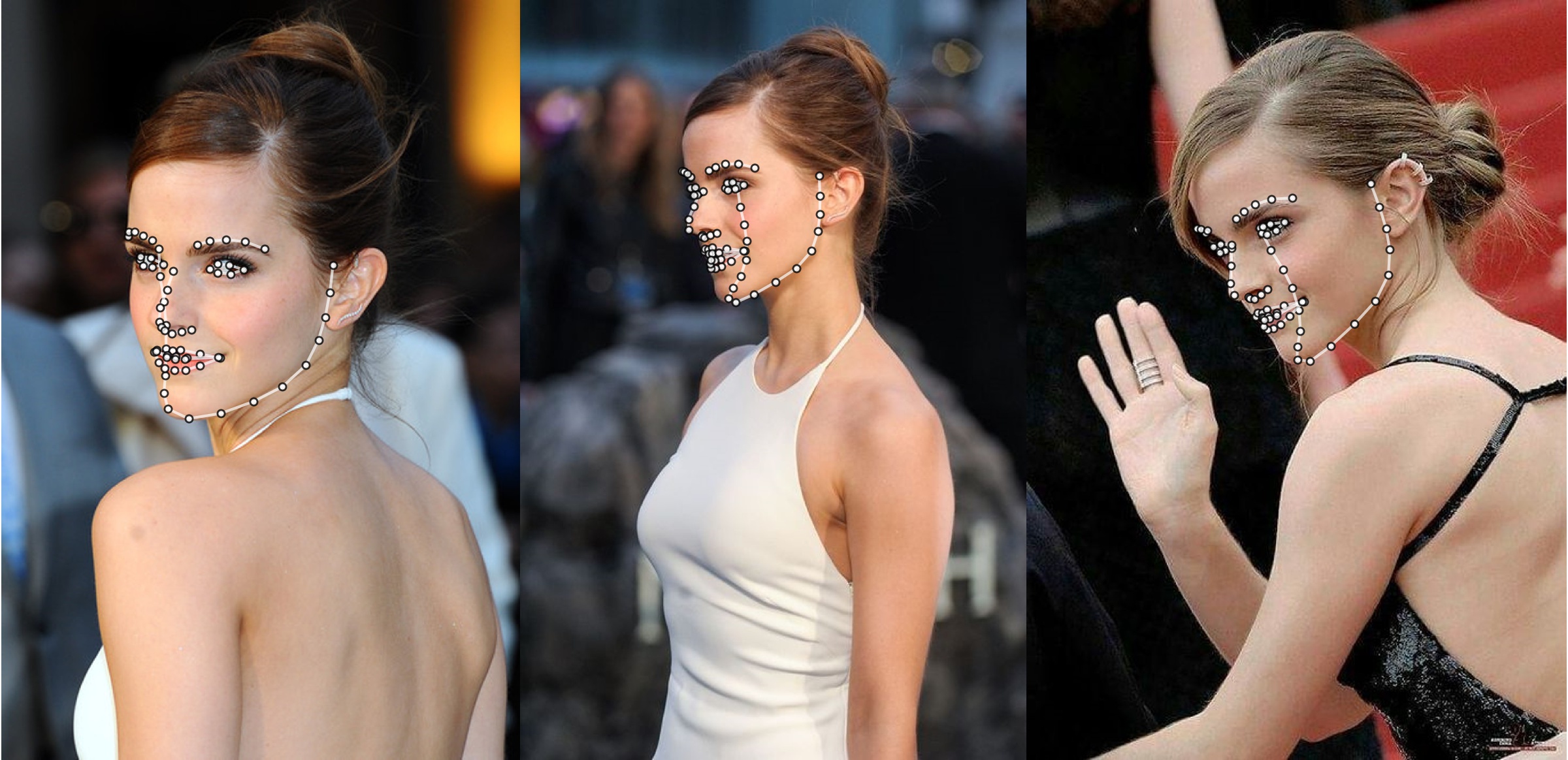
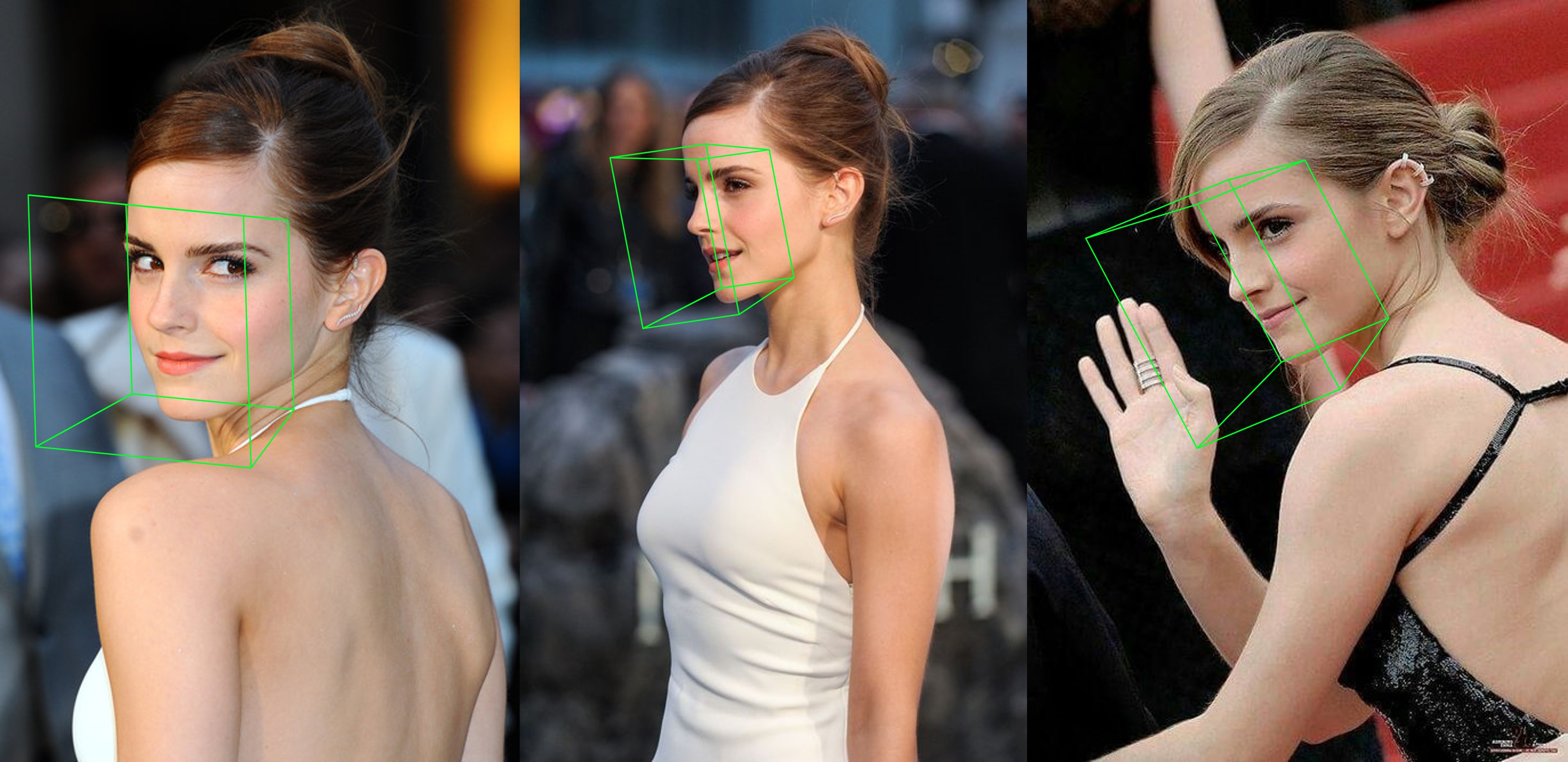
就跑
python3 speed_cpu.py
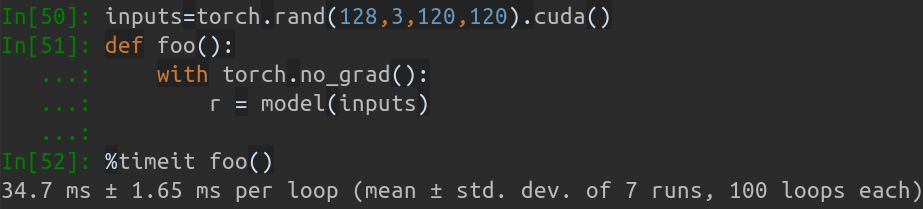
在我的 MBP(13 吋 MacBook Pro 上的 i5-8259U CPU @ 2.30GHz)上,基於PyTorch v1.1.0 ,具有單一輸入,運行輸出為:
Inference speed: 14.50±0.11 ms
當輸入批次大小為128時,MobileNet-V1的總推理時間約為34.7ms。平均速率約0.27ms/pic 。
訓練腳本位於training目錄中。相關資源如下表。
| 數據 | 下載連結 | 描述 |
|---|---|---|
| 火車配置 | 百度雲或Google Drive, 217M | 包含 3DMM 參數和訓練資料集檔案清單的目錄 |
| train_aug_120x120.zip | 百度雲或Google Drive,2.15G | 增強訓練資料集的裁切影像 |
| 測試數據.zip | 百度雲或Google Drive,151M | AFLW 和 ALFW-2000-3D 測試集的裁切影像 |
準備好訓練資料集和設定檔後,進入training目錄並執行 bash 腳本進行訓練。 train_wpdc.sh 、 train_vdc.sh和train_pdc.sh是訓練腳本的範例。配置好訓練集和測試集後,只需執行它們進行訓練即可。以train_wpdc.sh為例,如下:
#!/usr/bin/env bash
LOG_ALIAS=$1
LOG_DIR="logs"
mkdir -p ${LOG_DIR}
LOG_FILE="${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log"
#echo $LOG_FILE
./train.py --arch="mobilenet_1"
--start-epoch=1
--loss=wpdc
--snapshot="snapshot/phase1_wpdc"
--param-fp-train='../train.configs/param_all_norm.pkl'
--param-fp-val='../train.configs/param_all_norm_val.pkl'
--warmup=5
--opt-style=resample
--resample-num=132
--batch-size=512
--base-lr=0.02
--epochs=50
--milestones=30,40
--print-freq=50
--devices-id=0,1
--workers=8
--filelists-train="../train.configs/train_aug_120x120.list.train"
--filelists-val="../train.configs/train_aug_120x120.list.val"
--root="/path/to//train_aug_120x120"
--log-file="${LOG_FILE}"
具體的訓練參數都在bash腳本中呈現,包括學習率、小批量大小、epochs等。
首先,您應該在 test.data.zip 中下載裁切後的測試集 ALFW 和 ALFW-2000-3D,然後解壓縮並將其放在根目錄中。接下來,透過提供經過訓練的模型路徑來運行基準程式碼。我已經在models目錄中提供了五個預訓練模型(如下表所示)。這些模型在第一階段使用不同的損失進行訓練。由於MobileNet-V1結構的高效率,模型大小約為13M。
python3 ./benchmark.py -c models/phase1_wpdc_vdc.pth.tar
預訓練模型的表現如下所示。在第一階段,不同損耗的有效性順序為:WPDC > VDC > PDC。而使用VDC來微調WPDC的策略取得了最好的結果。
| 模型 | AFLW (21 分) | AFLW 2000-3D(68 分) | 下載連結 |
|---|---|---|---|
| Phase1_pdc.pth.tar | 6.956±0.981 | 5.644±1.323 | 百度雲或Google Drive |
| Phase1_vdc.pth.tar | 6.717±0.924 | 5.030±1.044 | 百度雲或Google Drive |
| Phase1_wpdc.pth.tar | 6.348±0.929 | 4.759±0.996 | 百度雲或Google Drive |
| Phase1_wpdc_vdc.pth.tar | 5.401±0.754 | 4.252±0.976 | 在這個倉庫中。 |
相信我,這個 repo 的框架可以在不增加任何計算預算的情況下實現比 PRNet 更好的效能。相關工作正在審核中,程式碼將在接受後發布。
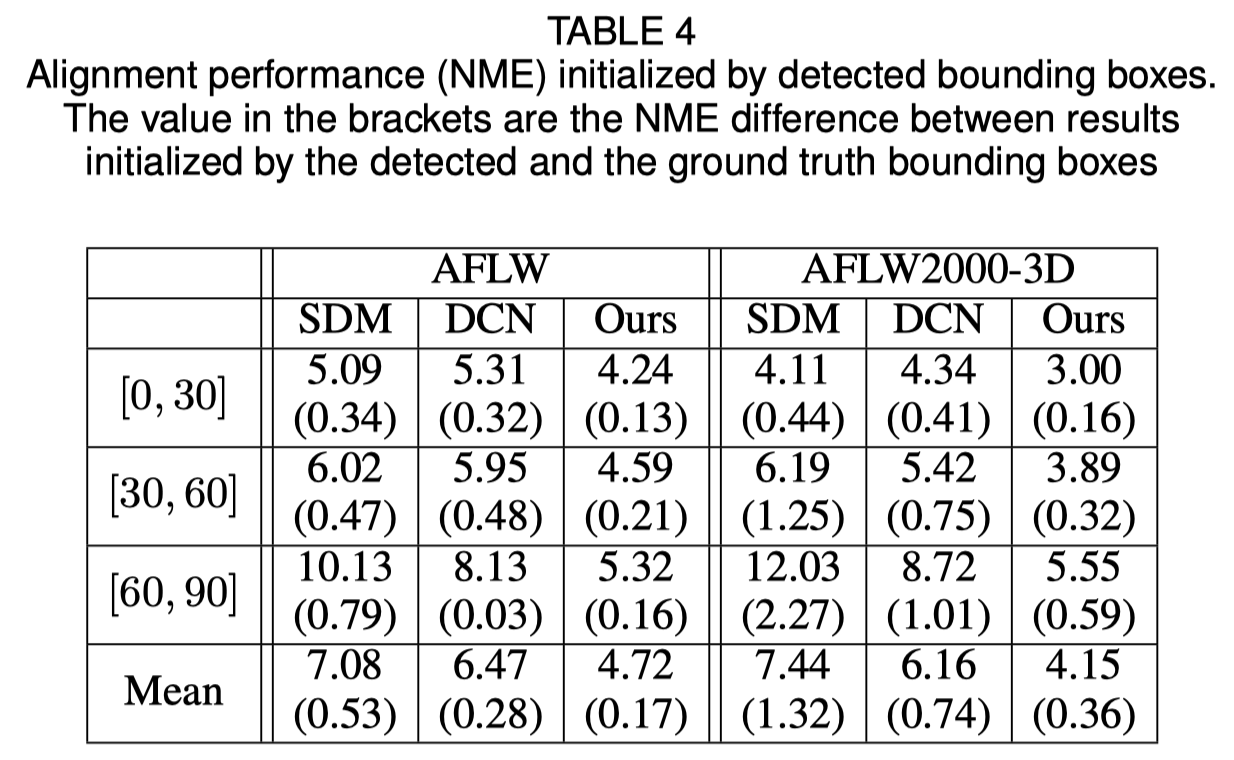
人臉邊界框初始化
原始論文表明,使用檢測到的邊界框而不是地面實況框會導致一點性能下降。因此,目前的臉部裁剪方法是最穩健的。定量結果如下表所示。
人臉重建
不可見區域的紋理由於自遮擋而扭曲,因此不可見臉部區域可能會顯得奇怪(有點可怕)。
關於形狀和表達式參數裁剪
參數裁剪加速了訓練和重建,但降低了準確性,尤其是閉眼等細節。下面是一張影像,參數尺寸為 40+10、60+29 和 199+29(原始影像)。與形狀相比,當涉及情緒時,表情剪切對重建精確度的影響更大。因此,您可以在速度/參數大小和精度之間進行權衡。剪裁權衡的建議是 60+29。

感謝您對此存儲庫的興趣。如果您的工作或研究受益於此儲存庫,請為其加註星標?
歡迎追蹤我的3D人臉相關作品:MeGlass和Face Anti-Spoofing。
如果您的工作受益於此儲存庫,請引用下面的三個圍脖。
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
@inproceedings{guo2020towards,
title= {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author= {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle= {Proceedings of the European Conference on Computer Vision (ECCV)},
year= {2020}
}
@article{zhu2017face,
title= {Face alignment in full pose range: A 3d total solution},
author= {Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z},
journal= {IEEE transactions on pattern analysis and machine intelligence},
year= {2017},
publisher= {IEEE}
}
郭建珠[首頁,Google Scholar]: [email protected]或[email protected] 。


