genai_robotics
1.0.0
該存儲庫包含一個實驗性的、具有隱私意識的設置,用於在機器人控制中利用生成式人工智慧方法。透過這裡提出的解決方案,使用者可以透過語音自由定義動作,這些動作被轉換成機器人吸塵器可以在攝影機觀察到的開放世界環境中執行的計劃。
這裡介紹的方法的基本優點是:
該系統是在為期 3 天的黑客馬拉松中開發的,作為學習練習和概念證明,現代人工智慧工具可以顯著縮短機器人控制解決方案的開發時間。
要使用此儲存庫的所有功能,您應該擁有以下內容:
首先,請依照以下步驟操作:
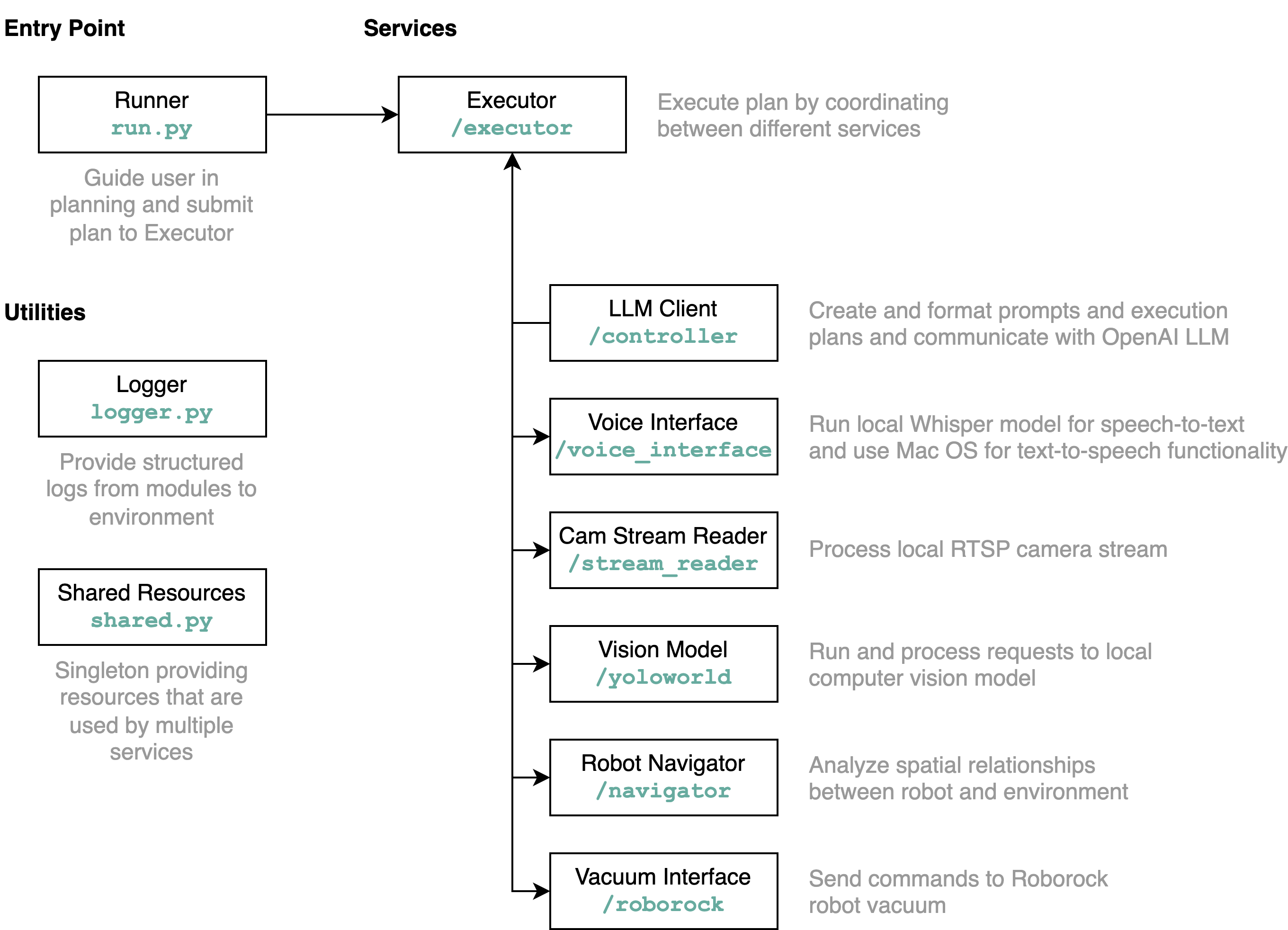
requirements.txt中的需求安裝到Python環境中(使用Python 3.11進行測試)src/config.template.toml重新命名為config.toml 。對於以下所有步驟,請將取得的憑證插入到config.toml中python-roborock庫的文檔中閱讀有關如何執行此操作的更多資訊。src/run.py來執行工作流程。 了解此存儲庫詳細功能以及元素如何交互的最佳方法是透過架構圖:
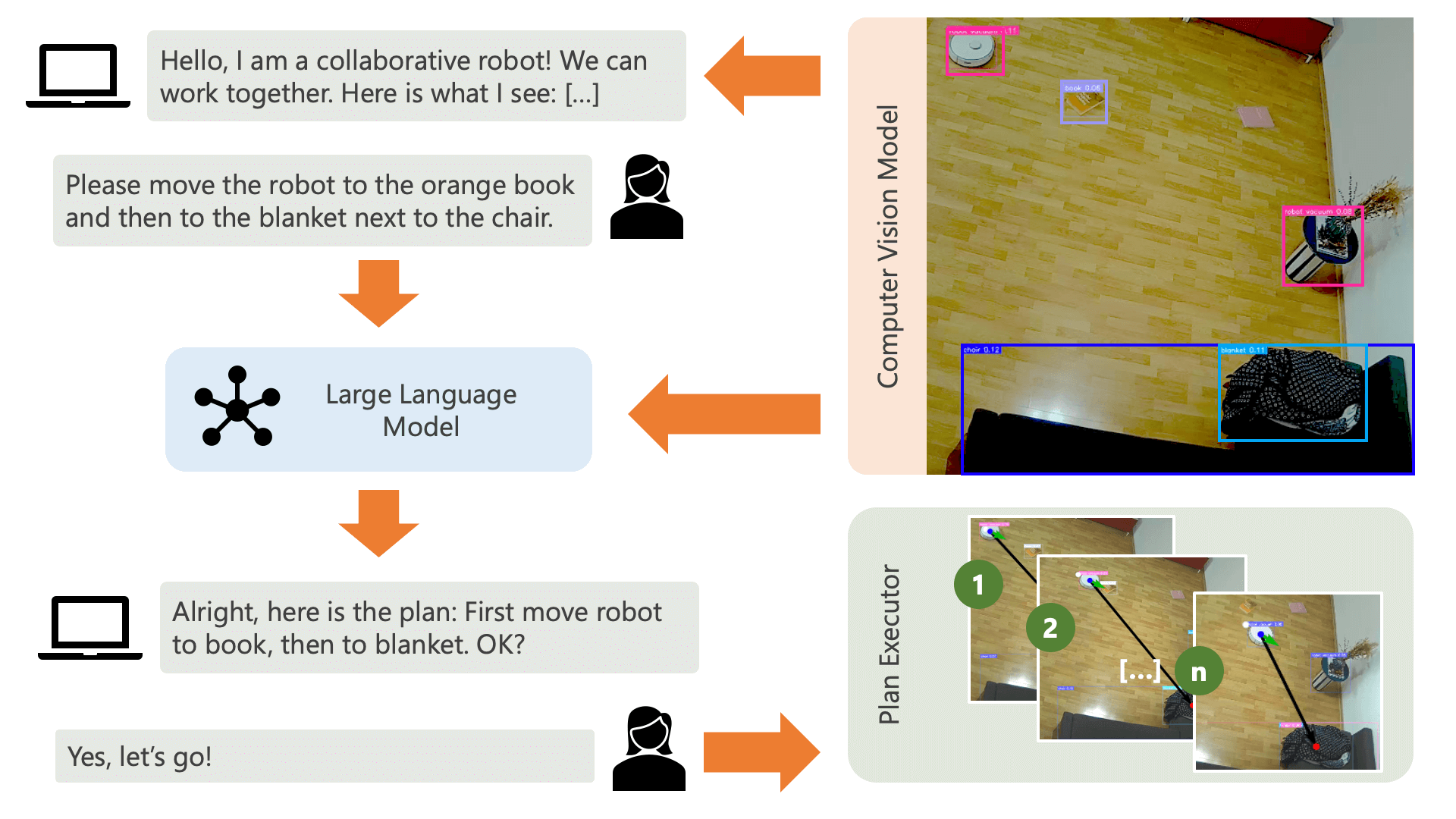
當您如上所述執行run.py檔案時,會發生以下情況及其工作原理:
系統透過音訊訊息向用戶致意,並希望他們告訴系統他們想要做什麼。例如,用戶可能希望機器人從坐在黃色椅子上的人那裡拿起咖啡,然後將其運送給坐在黑色沙發上的另一個人。然後系統將建立一個計劃來執行這些操作。
系統需要了解什麼才能實現使用者想要做的事情?系統需要了解其環境以及可以在該環境中執行的操作。在這裡,我們使用具有物件偵測功能的電腦視覺模型來向系統提供有關環境的資訊。吸塵器本身可以執行 3 個簡單的動作:向前移動、轉動和不執行任何操作。環境中的另一個操作是等待使用者執行某個操作。
為了避免使用者方面的困惑,使用者了解人工智慧如何感知其環境非常重要。例如,如果電腦視覺模型無法辨識某個物體,人工智慧將無法將其納入計畫中。同樣重要的是,使用者要意識到模型識別存在不確定性。使用 OpenAI 的 GPT-4o 大語言模型和描述提示,系統會對其環境進行解釋,並在詢問使用者希望系統做什麼之前將其讀給使用者。
給定環境資訊和使用者輸入的關於他們想要做什麼的信息,系統就可以製定一個計劃。在這裡,我們要求法學碩士根據使用者的輸入和環境的描述制定一個計劃。您可以在controller目錄中找到提示範本。這裡令人興奮的技巧是,法學碩士只能透過根據電腦視覺模型的輸出產生的兩個表格來了解其環境。這是一個例子:
Item locations:
| id | label | position | confidence | color_rgb |
|-----:|:-------------|:----------------|-------------:|:----------------|
| 0 | robot vacuum | (122.0, 140.0) | 0.23 | [205, 206, 210] |
| 1 | blanket | (1697.0, 923.0) | 0.59 | [60, 72, 90] |
| 2 | chair | (532.5, 210.0) | 0.39 | [177, 177, 171] |
| 3 | chair | (160.0, 521.5) | 0.24 | [99, 99, 98] |
| 4 | book | (1216.5, 601.0) | 0.2 | [137, 141, 155] |
Distances:
| id | 0 | 1 | 2 | 3 | 4 |
|-----:|-----:|-----:|-----:|-----:|-----:|
| 0 | 0 | 1758 | 416 | 383 | 1187 |
| 1 | 1758 | 0 | 1365 | 1588 | 578 |
| 2 | 416 | 1365 | 0 | 485 | 787 |
| 3 | 383 | 1588 | 485 | 0 | 1059 |
| 4 | 1187 | 578 | 787 | 1059 | 0 |
一旦法學碩士處理了計劃提示,它就會輸出兩件事:推理和計劃。在系統繼續執行計劃之前,它將使用解釋提示產生計劃的簡短摘要,以便使用者確認該計劃符合他們要求執行的操作。這本著「人在環」方法的精神,我們的運作立場是,在真實、開放的物理環境中,人們可能會受到人工智慧行為的傷害,因此要求人類參與是合理的。它自己提出的任何計劃之前提供反饋。
一旦使用者確認,系統就會繼續執行計劃。由法學碩士產生的這樣的計劃可能如下所示:
[
{ "action" : " MOVE " , "location" : [ 1216.5 , 601.0 ]},
{ "action" : " WAIT_UNTIL " , "task_fulfilled" : " Please place the book on the robot vacuum so that the robot can transport it to the chair. " },
{ "action" : " MOVE " , "location" : [ 532.5 , 210.0 ]},
{ "action" : " END " }
]使用executor ,系統逐步執行計劃。為了減少所需的設定時間,機器人控制遵循簡單、不準確但有效的演算法:
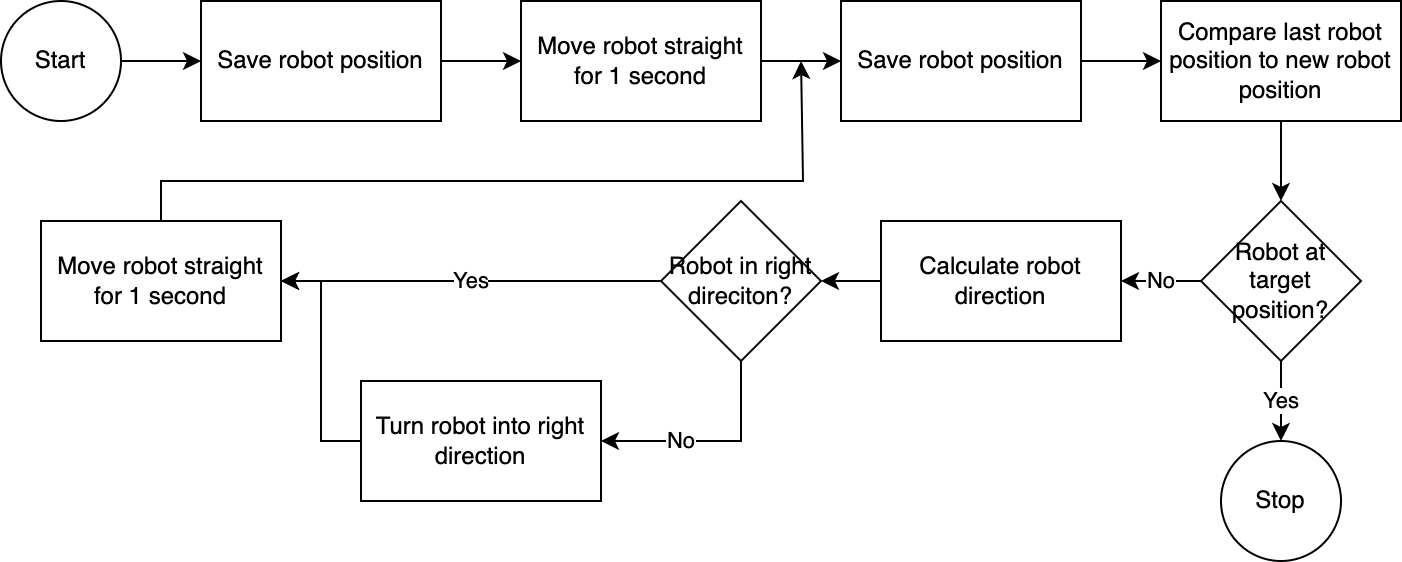
電腦視覺系統評估機器人的位置。透過navigator模組中的程式碼,分析和比較機器人相對於其目標位置和相對於其最後已知位置的位置。這種方法並不完美,因為沒有考慮相機的位置和鏡頭畸變。透過這種方法測量的角度不準確。然而,由於系統是迭代的,因此經常會補償錯誤。然而,值得注意的是,這是以速度為代價的。該系統速度很慢,因為需要時間來分析影像、計算路徑並通知機器人下一步要採取的步驟。
一旦機器人到達目標位置,執行器就會繼續執行計畫的下一步。對於涉及使用者輸入的操作,執行器將使用文字轉語音和語音轉文字功能與使用者互動。
在這個系統中,我們主要使用在本機電腦或網路上運行的服務。 GPT-4o 是個例外。我們透過網路將文字資料傳送到 OpenAI 的模型。文字資料包括轉錄的使用者輸入和識別的物件表。 The only reason we use GPT-4o here is because this is one of the best models available at the time of the hackathon – we could also run a local LLM and then fully work without connection to the internet, preserving privacy among the entire flow of營運.
這個儲存庫中包含的電腦視覺模型是由 YOLO-World 模型在 HuggingFace 空間中產生的,提示如下: chair, book, candle, blanket, vase, bulb, robot vacuum, mug, glass, human 。如果您想辨識其他物體,請調整提示並透過此空間下載 ONNX 模型。然後,您可以替換src/yoloworld/models/rev0目錄中的模型。
請注意,為了正確提取模型,您需要在匯出模型之前手動更改 HuggingFace 空間中的最大框數和得分閾值參數。
您可以在 YOLO-World 網站上了解有關令人興奮的 YOLO-World 模型的更多信息,該模型建立在視覺語言建模的最新進展之上。
該項目是在 MIT 許可證下發布的。
這個儲存庫沒有受到主動監控,也無意擴展它——它首先是一個學習練習。但是,如果您受到啟發,請隨時透過開啟 GitHub 問題或拉取請求為該專案做出貢獻。


