full stack on prem cv mlops
1.0.0
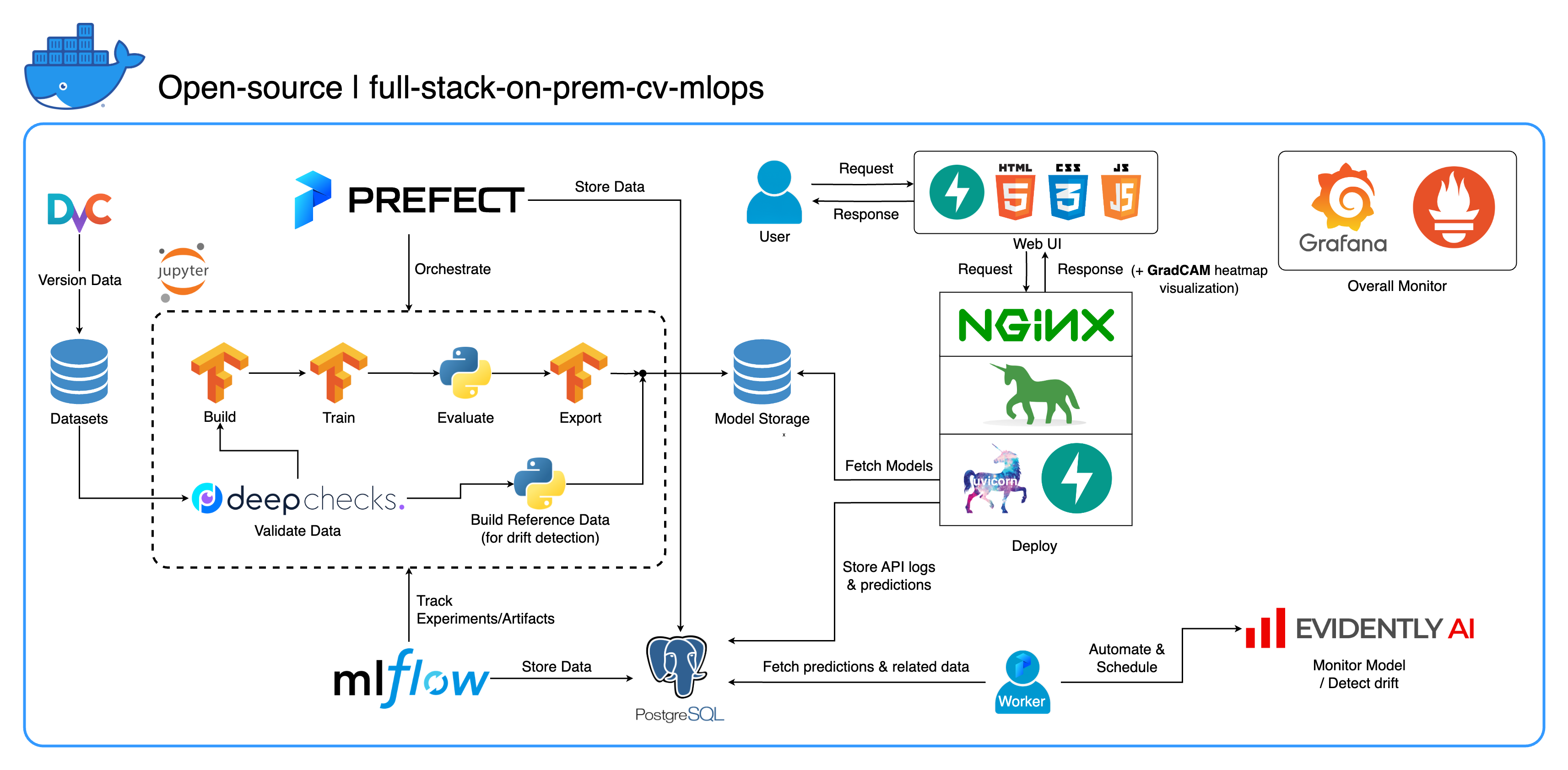
歡迎來到我們專為電腦視覺任務設計的全面的本地 MLOps 生態系統,主要關注圖像分類。此儲存庫為您提供了所需的一切,從 Jupyter Lab/Notebook 中的開發工作區到生產級服務。最好的部分?只需「1個配置和1個命令」即可運行整個系統從建置模型到部署!我們整合了許多最佳實踐,以確保可擴展性和可靠性,同時保持靈活性。雖然我們的主要用例圍繞著影像分類,但我們的專案結構可以輕鬆適應各種 ML/DL 開發,甚至從本地過渡到雲端!
另一個目標是展示如何整合所有這些工具並使它們在完整的系統中協同工作。如果您對特定組件或工具感興趣,請隨意挑選適合您專案需求的組件或工具。
整個系統被容器化到單一 Docker Compose 檔案。要設定它,您所要做的就是運行docker-compose up !這是一個完全本地部署的系統,這意味著不需要雲端帳戶,並且使用整個系統不會花費您一毛錢!
我們強烈建議您觀看演示視頻部分中的演示視頻,以獲得全面的概述並了解如何將此系統應用到您的專案中。這些影片包含的重要細節可能太長且不夠清晰,無法在此介紹。
示範:https://youtu.be/NKil4uzmmQc
深入的技術演練:https://youtu.be/l1S5tHuGBA8
影片中的資源:
要使用此儲存庫,您只需要 Docker。作為參考,我們在 Mac M1 上使用Docker 版本 24.0.6、建置 ed223bc和Docker Compose 版本 v2.21.0-desktop.1 。
我們在這個計畫中實施了一些最佳實踐:
tf.data for TensorFlow 實現高效能資料載入器/管道imgaug lib 進行影像增強,與 TensorFlow 的核心函數相比,增強選項具有更大的靈活性os.env進行重要或服務等級的配置logging模組而不是print進行日誌記錄.env動態配置docker-compose.yml中的變數default.conf.template優雅地在 Nginx 配置中應用環境變數(Nginx 1.19 中的新功能)大多數連接埠都可以在此儲存庫根目錄下的 .env 檔案中自訂。以下是預設值:
123456789 )[email protected] ,密碼: SuperSecurePwdHere )admin ,密碼: admin )如果您不使用基於 ARM 的電腦(我們使用 Mac M1 進行開發),則必須考慮在docker-compose.yml中註解這些platform: linux/arm64行。否則這個系統就無法運作。
--recurse-submodules標誌: git clone --recurse-submodules https://github.com/jomariya23156/full-stack-on-prem-cv-mlopsdocker-compose.yml中取消註解jupyter服務下的deploy部分,並將services/jupyter/Dockerfile中的基礎映像從ubuntu:18.04變更為nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 (文字位於檔案中,您只需註解和取消註解)以利用您的 GPU。您可能還需要在主機上安裝nvidia-container-toolkit才能使其正常運作。對於 Windows/WSL2 用戶,我們發現這篇文章非常有幫助。docker-compose up或docker-compose up -d以分離終端。datasets/animals10-dvc處的 DvC 子模組,然後依照如何使用部分中的步驟操作。 http://localhost:8888/labcd ~/workspace/docker-compose.yml中配置) conda activate computer-viz-dlpython run_flow.py --config configs/full_flow_config.yamltasks目錄中創建flows目錄中建立的流中調用run_flow.py進行呼叫。start(config)函數。函數接受 Python 字典形式的配置,然後基本上調用該檔案中的特定流程。datasets目錄內,並且它們都應具有與此儲存庫內的目錄結構相同的目錄結構。~/ariya/中的central_storage應包含至少 2 個名為models和ref_data的子目錄。這個central_storage服務於物件儲存目的,儲存所有要在開發和部署環境中使用的暫存檔案。 (如果您想部署在雲端並使其更具可擴展性,這是您可以考慮更改為雲端儲存服務的事情之一)重要如果您想更改約定,請務必格外小心(因為這些內容是綁定在系統的不同部分並使用的):
central_storage路徑 -> 裡面應該有models/ ref_data/子目錄<model_name>.yaml 、 <model_name>_uae 、 <model_name>_bbsd 、 <model_name>_ref_data.parquetcurrent_model_metadata_file和monitor_pool_namecomputer-viz-dl (預設值)的預先安裝Conda環境,以及該儲存庫所需的所有套件。所有 Python 命令/程式碼都應該在此 Jupyter 中運行。central_storage磁碟區可充當整個開發和部署過程中使用的中央文件儲存。它主要包含Parquet格式的模型檔案(包括漂移偵測器)和參考資料。在模型訓練步驟結束時,新模型將保存在此處,部署服務將從該位置提取模型。 (注意:這是替換雲端儲存服務以實現可擴展性的理想場所。)model部分建立分類器模型。該模型是使用TensorFlow建構的,其架構在tasks/model.py:build_model處進行硬編碼。dataset部分準備用於訓練的資料集。此步驟使用DvC來檢查磁碟中資料與config中指定版本的一致性。如果有更改,它會以程式設計方式將其轉換回指定版本。如果您想要保留更改,以防萬一您正在試驗資料集,您可以將配置中的dvc_checkout欄位設為false ,以便 DvC 不會執行其操作。train部分建立資料載入器並開始訓練過程。使用MLflow追蹤和記錄實驗資訊和工件。注意:DeepChecks 的結果報告( .html檔案)也上傳到 MLflow 上的訓練實驗以供約定。model部分建立模型元資料檔。central_storage (在本例中,它只是複製到central_storage位置。您可以變更此步驟以將檔案上傳到雲端儲存)model/drift_detection部分來建立漂移偵測器。central_storage 。central_storage 。central_storage獲取新訓練的模型。 (這是教學示範影片中討論的問題,請觀看以了解更多詳細資訊)current_model_metadata_file儲存以.yaml結尾的模型元資料檔名, monitor_pool_name儲存用於部署 Prefect 工作器和流程的工作池名稱。cd到deployments/prefect-deployments並使用配置中的deploy/prefect部分的輸入執行prefect --no-prompt deploy --name {deploy_name} 。由於此儲存庫中的所有內容都已經進行了 Docker 化和容器化,因此將服務從本機轉換為雲端非常簡單。當您完成服務 API 的開發和測試後,您可以透過從 Dockerfile 建置容器來分離services/dl_service ,並將其推送到雲端容器登錄服務(例如 AWS ECR)。就是這樣!
注意:如果您想在實際生產環境中使用服務代碼,則有一個潛在的問題。我已經在深度影片中解決了這個問題,我建議您花一些時間觀看整個影片。 
我們在 PostgreSQL 中擁有三個資料庫:一個用於 MLflow,一個用於 Prefect,另一個是我們為 ML 模型服務建立的。我們不會深入研究前兩個,因為它們是由這些工具自行管理的。我們的 ML 模型服務的資料庫是我們自己設計的。
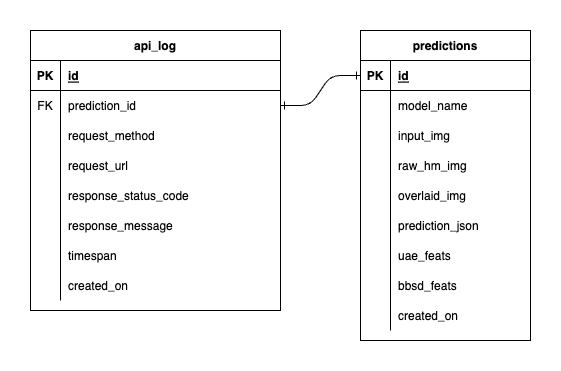
為了避免過於複雜,我們只使用兩個表來保持簡單。關係和屬性顯示在下面的 ERD 中。從本質上講,我們的目標是儲存有關傳入請求和我們的服務回應的基本詳細資訊。所有這些表都是自動建立和操作的,因此您無需擔心手動設定。
值得注意的是: input_img 、 raw_hm_img和overlaid_img是儲存為字串的 Base64 編碼影像。 uae_feats和bbsd_feats是我們的漂移偵測演算法的嵌入特徵陣列。
ImportError: /lib/aarch64-linux-gnu/libGLdispatch.so.0: cannot allocate memory in static TLS block錯誤,請嘗試export LD_PRELOAD=/lib/aarch64-linux-gnu/libGLdispatch.so.0然後重新運行您的腳本。

