content dicovery platform gcp
1.0.0
此儲存庫包含建立由 VertexAI 基礎模型支援的簡單內容發現平台所需的程式碼和自動化。該平台應該能夠捕獲文件內容(最初是Google Docs),並利用該內容生成嵌入向量,並將其儲存在由VertexAI 匹配引擎支援的向量資料庫中,稍後可以利用該嵌入來將外部消費者的一般問題置於上下文中該上下文請求 VertexAI 基礎模型的答案以獲得答案。
此平台可分為 4 個主要元件:存取服務層、內容擷取管道、內容儲存和 LLM。服務層使外部消費者能夠發送文件攝取請求,並隨後發送有關先前攝取的文件中包含的內容的查詢。內容捕獲管道負責捕獲 NRT 中的文件內容、提取嵌入並將這些嵌入與真實內容進行映射,這些真實內容稍後可用於將外部用戶的問題與 LLM 聯繫起來。內容儲存分為 3 個不同的目的,LLM 微調、線上嵌入匹配和分塊內容,每個目的都由專門的儲存系統處理,一般目的是儲存平台元件實現攝取和查詢所需的資訊使用案例。最後但並非最不重要的一點是,該平台利用 2 個專門的法學碩士根據攝取的文檔內容創建即時嵌入,另一個負責生成平台用戶請求的答案。
前面描述的所有元件都是使用公開可用的 GCP 服務來實現的。列出:Cloud Build、Cloud Run、Cloud Dataflow、Cloud Pubsub、Cloud Storage、Cloud Bigtable、Vertex AI 匹配引擎、Vertex AI 基礎模型(嵌入和文字野牛),以及作為內容資訊的 Google Docs 和 Google Drive來源。
下圖顯示了架構和技術的不同組件如何相互互動。
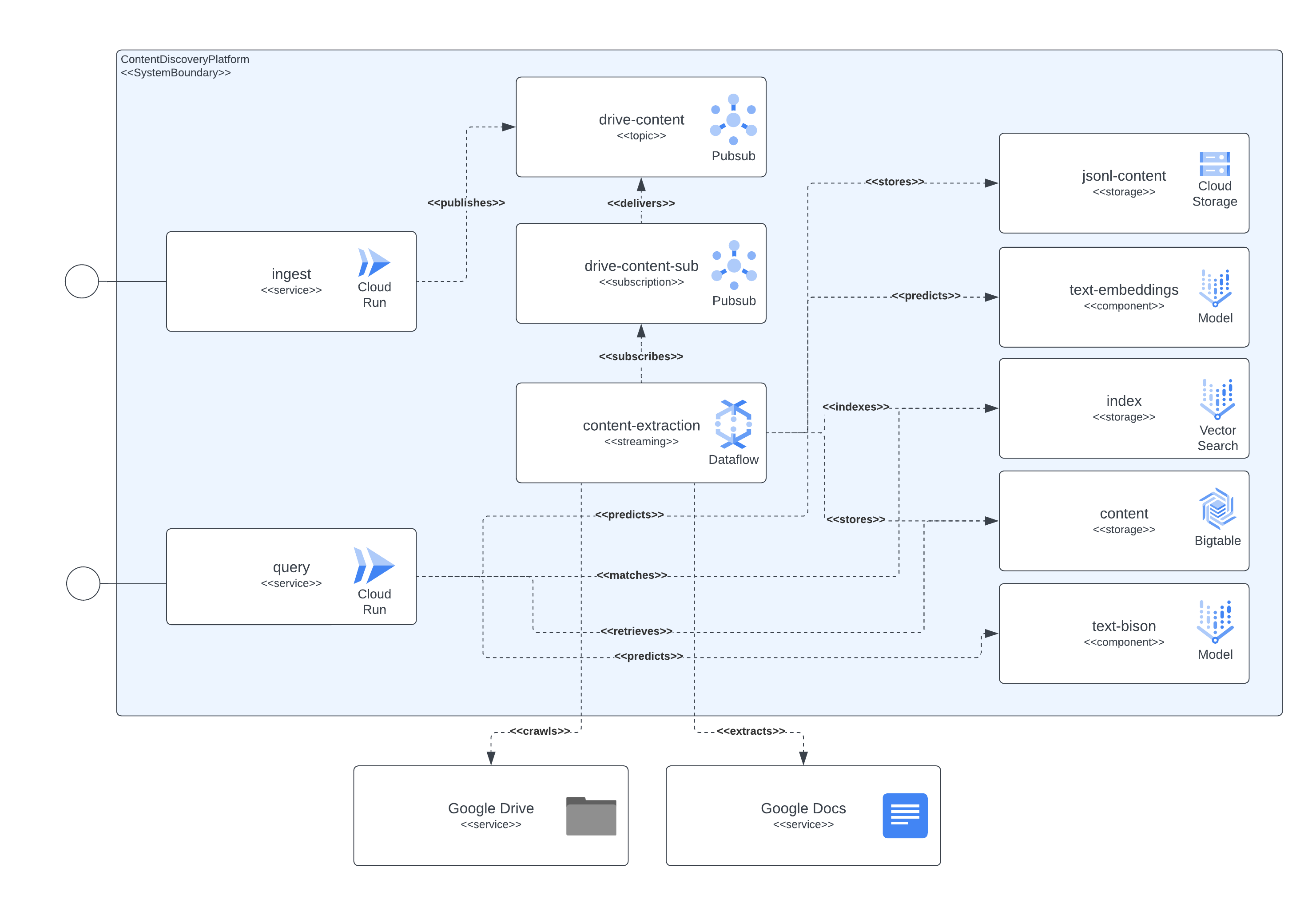
該平台使用 Terraform 來設定其所有組件。對於目前沒有本機支援的人,我們創建了 null_resource 包裝器,這是很好的解決方法,但它們往往具有非常粗糙的邊緣,因此請注意潛在的錯誤。
截至今天(2023 年 6 月)的完整部署可能需要長達 90 分鐘才能完成,最大的罪魁禍首是與匹配引擎相關的組件,這些組件需要花費大部分時間來創建和準備就緒。隨著時間的推移,這種延長的運行時間只會改善。
該設定應該可以從儲存庫中包含的腳本執行。
部署該平台需要滿足一些要求:
為了在 GCP 中部署所有元件,我們需要建置、建立基礎設施,然後部署服務和管道。
為了實現這一目標,我們包含了腳本start.sh ,它基本上協調了其他包含的腳本以完成完整的部署目標。
此外,我們還包含了一個cleanup.sh腳本,負責銷毀基礎設施並清理收集的資料。
通常情況下,Google Workspace 文件將在託管運行內容提取管道的項目的同一組織中創建,因此為了向這些文檔授予權限,請將運行管道的服務帳號添加到文檔或文檔文件夾中,應該足夠了。
如果需要存取專案組織外部存在的文件或資料夾,則應完成額外的步驟。設定基礎架構後,部署程序將列印出指令,向執行內容提取管道的服務帳號授予權限,以透過全域委派模擬 Google Workspace 文件存取權限。可以在此處查看完成這些步驟的資訊:https://developers.google.com/workspace/guides/create-credentials#optical_set_up_domain-wide_delegation_for_a_service_account
此解決方案透過 GCP CloudRun 和 API Gateway 公開了一些資源,可用於進行內容擷取和內容發現查詢的互動。在所有範例中,我們都使用符號<service-address>字串,在服務部署完成後,應將其替換為 CloudRun 提供的 URL(Terraform 輸出中的backend_service_url )或 API Gateway(Terraform 輸出中的sevice_url )。
當需要 CORS 互動時,可以使用 API 閘道端點來完成預檢協定。 CloudRun 目前不支援未經身份驗證的OPTIONS命令,但透過 API Gateway 公開的路徑確實支援它們。
該服務能夠從 Google Drive 中託管的文檔或自包含的多部分請求中獲取數據,其中包含文檔標識符和編碼為二進制的文檔內容。
Google Drive 攝取是透過傳送類似下一個範例的 HTTP 請求來完成的
$ > curl -X POST -H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /ingest/content/gdrive
-d $' {"url":"https://docs.google.com/document/d/somevalid-googledocid"} '此請求將指示平台從提供的url獲取文檔,如果運行攝取的服務帳戶具有文檔的存取權限,它將從中提取內容並儲存資訊以供索引、以後發現和檢索。
該請求可以包含 Google 文件或 Google Drive 資料夾的 URL,在後一種情況下,擷取將抓取要處理的文件的資料夾。此外,還可以使用urls屬性,該屬性需要string值的JSONArray ,其中每個值都是有效的 Google 文件 url。
如果想要包含可由攝取用戶端本機存取的文章、文件或頁面的內容,則使用多部分端點應該足以擷取文件。請參閱下一個curl命令作為範例,該服務期望設定documentId表單欄位來識別內容並對其進行唯一索引:
$ > curl -H " Authorization: Bearer $( gcloud auth print-identity-token ) "
-F documentId= < somedocid >
-F documentContent=@ < /some/local/directory/file/to/upload >
https:// < service-address > /ingest/content/multipart該服務向平台用戶公開查詢功能,透過向服務發送自然文字查詢,並考慮到平台中已經存在內容索引,該服務將傳回由 LLM 模型匯總的資訊。
與服務的交互可以透過 REST 交換來完成,類似於攝取部分的交互,如下一個範例所示。
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": ""} '
| jq .
# response from service
{
"content": "VertexAI foundational models are a set of pre-trained models that can be used to build and deploy machine learning applications. They are available in a variety of languages and frameworks, and can be used for a variety of tasks, including natural language processing, computer vision, and recommendation systems.nnVertexAI foundational models are a good choice for Generative AI applications because they provide a starting point for building these types of applications. They can be used to quickly and easily create models that can generate text, images, and other types of content.nnIn addition, VertexAI foundational models are scalable and can be used to process large amounts of data. They are also reliable and can be used to create applications that are available 24/7.nnOverall, VertexAI foundational models are a powerful tool for building Generative AI applications. They provide a starting point for building these types of applications, and they can be used to quickly and easily create models that can generate text, images, and other types of content.",
" sourceLinks " : [
]
}這裡有一個特殊情況,即尚未儲存特定主題的訊息,如果該主題屬於 GCP 領域,那麼模型將充當專家,因為我們設定了一個提示來指示模型請求。
如果想要與服務進行更多上下文感知類型的交換,則應為服務提供會話識別碼(JSON 請求中的sessionId屬性)以用作會話交換金鑰。此對話金鑰將用於為模型設定正確的上下文(透過總結先前的交換)並追蹤最近 5 次交換(至少)。另外值得注意的是,交換歷史記錄將保留 24 小時,這可以作為平台中 BigTable 儲存的 gc 策略的一部分進行更改。
接下來是上下文感知對話的範例:
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.nnUsing VertexAI Foundational Models can help you to:nn* Reduce the time and effort required to develop Generative AI applicationsn* Improve the accuracy and quality of your modelsn* Access the latest research and development in Generative AInnVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"describe the available LLM models?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models suite includes a variety of LLM models, including:nn* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.nnThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits). " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"care to share the price?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models). " ,
" sourceLinks " : [
]
}

