ustore
v0.13.12
![]()
![]()
![]()
![]()
![]()
![]()
YouTube 簡介 • Discord 聊天 • 完整文檔
安裝 UStore 非常簡單,使用起來就像 Python dict一樣簡單。
$ pip install ukv
$ python
from ukv import umem
db = umem . DataBase ()
db . main [ 42 ] = 'Hi'我們剛剛建立了一個記憶體嵌入式事務資料庫,並在其main集合中新增了一個條目。您更喜歡磁碟上的資料嗎?換一行。
from ukv import rocksdb
db = rocksdb . DataBase ( '/some-folder/' )您想要連接到遠端 UStore 伺服器嗎? UStore 隨附 Apache Arrow Flight RPC 介面!
from ukv import flight_client
db = flight_client . DataBase ( 'grpc://0.0.0.0:38709' )您是否儲存類似 NetworkX 的MultiDiGraph ?或類似 Pandas 的DataFrame ?
db = rocksdb . DataBase ()
users_table = db [ 'users' ]. table
users_table . merge ( pd . DataFrame ([
{ 'id' : 1 , 'name' : 'Lex' , 'lastname' : 'Fridman' },
{ 'id' : 2 , 'name' : 'Joe' , 'lastname' : 'Rogan' },
]))
friends_graph = db [ 'friends' ]. graph
friends_graph . add_edge ( 1 , 2 )
assert friends_graph . has_edge ( 1 , 2 ) and
friends_graph . has_node ( 1 ) and
friends_graph . number_of_edges ( 1 , 2 ) == 1函數呼叫可能看起來相同,但底層實作可以尋址遠端電腦上持久記憶體中某處的數百 TB 資料。
是否有其他人同時更新這些集合?捆綁您的操作以確保一致性!
db = rocksdb . DataBase ()
with db . transact () as txn :
txn [ 'users' ]. table . merge (...)
txn [ 'friends' ]. graph . add_edge ( 1 , 2 )到目前為止,我們只介紹了 UStore 的一小部分。您可以用它來...
但UStore 還可以。這是地圖:
## 基本用法
UStore 的目的不僅是作為資料庫,而是作為「建構資料庫」工具包和 NoSQL 潛在事務資料庫的開放標準,為「建立、讀取、更新、刪除」操作(簡稱 CRUD)定義零拷貝二進位介面。
一些簡單的 C99 標頭可以將幾乎任何底層儲存引擎連結到眾多高級語言驅動程序,將對二進位字串值的支援擴展到圖形、靈活模式文件和其他模式,旨在取代 MongoDB、Neo4J、Pinecone 和 ElasticSearch使用單一ACID 事務系統。
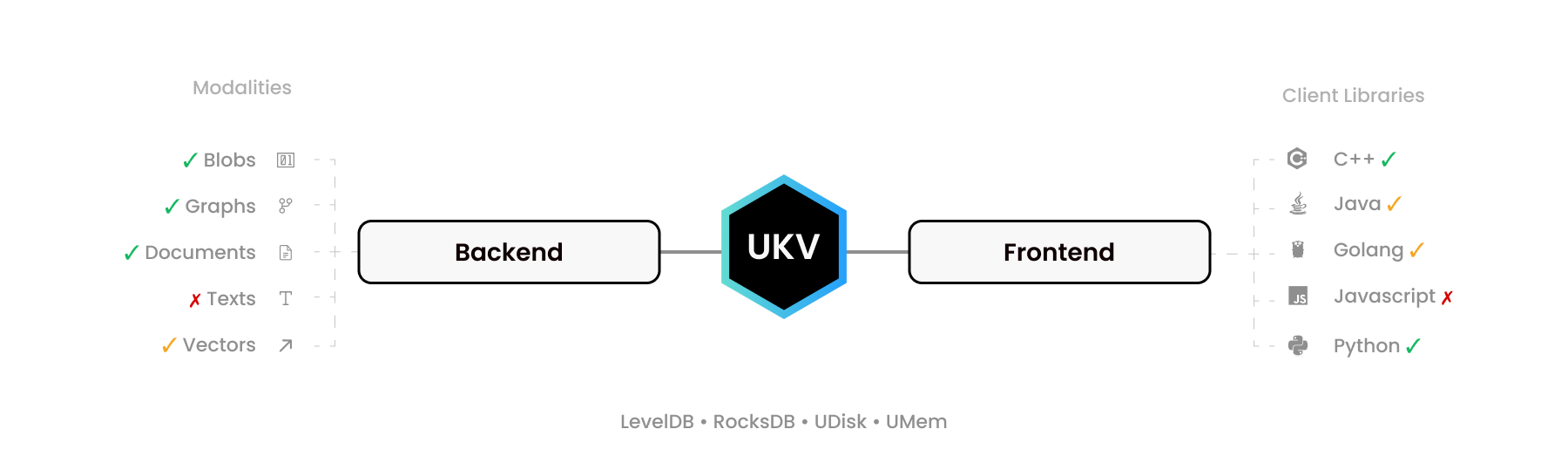
例如,Redis 提供了具有類似目標的 RediSearch、RedisJSON 和 RedisGraph。 UStore 做得更好,讓您可以添加您最喜歡的鍵值儲存 (KVS),嵌入式、獨立或分片,例如 FoundationDB,從而增強其功能。
二進位大物件可以放置在 UStore 中。根據所使用的底層技術,性能會有很大差異。記憶體中的 UCSet 速度最快,但最不適合較大的物件。持久化 UDisk 在正確配置後,可以完全繞過 Linux 內核,包括檔案系統層,直接尋址塊設備。
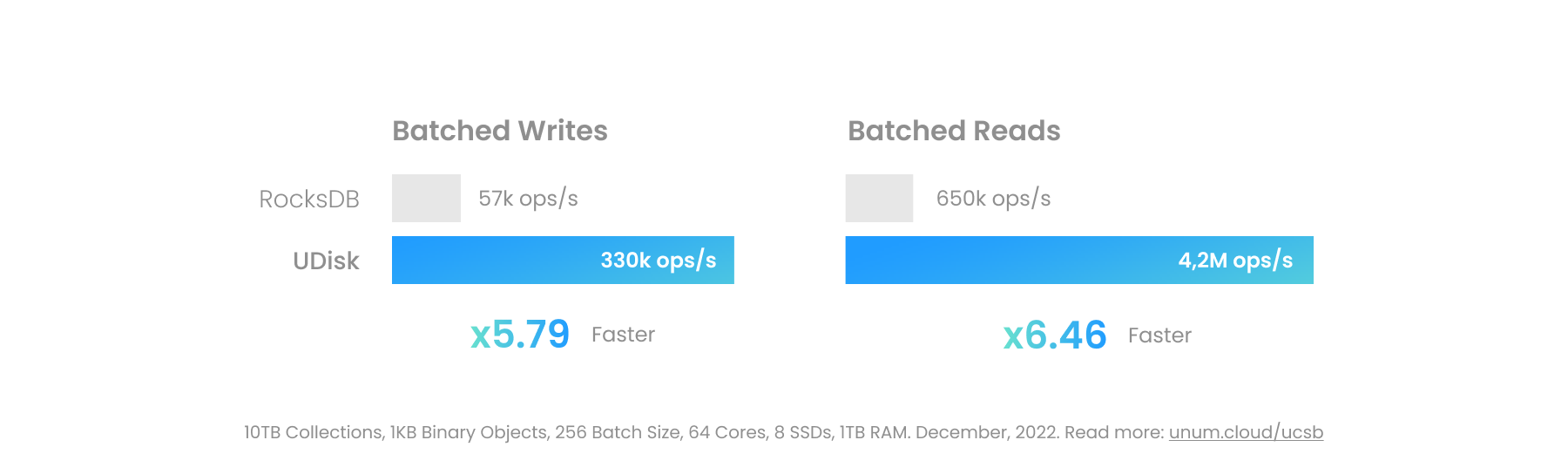
當基於 SPDK 等用戶空間驅動程式建置時,高階伺服器上的現代持久 IO 每個套接字可以超過 100 GB/s。這接近高階 RAM 的實際吞吐量,並解鎖了資料庫用例中不常見的新功能。現在,人們可以將千兆位元組大小的視訊檔案放在 ACID 事務資料庫中,緊鄰其元數據,而不是使用像 MinIO 這樣的單獨的物件儲存。
JSON 是當今最常用的文檔格式。 UStore 文件集合支援 JSON,以及 MongoDB 使用的 MessagePack 和 BSON。

UStore 還不能水平擴展,但可以提供更高的單節點效能,並且借助開源的simdjson和yyjson庫,在多核心系統上具有幾乎線性的垂直可擴展性。此外,要與資料交互,您不需要像 MQL 這樣的自訂查詢語言。相反,我們優先考慮開放 RFC 標準,以真正避免供應商鎖定:
現代圖形資料庫(例如 Neo4J)難以應對巨大的工作負載。它們需要太多的 RAM,而且它們的演算法一次只能觀察一個條目的資料。我們在兩個方面進行優化:
特徵儲存和向量資料庫(例如 Pinecone、Milvus 和 USearch)為向量搜尋提供獨立索引。 UStore 將其實現為單獨的模式,與文件和圖表相同。特徵:
用於 Python 的 UStore 和用於 C++ 的 UStore 看起來非常不同。我們的 Python SDK 模仿其他 Python 函式庫 - Pandas 和 NetworkX。同樣,C++ 函式庫提供了 C++ 開發人員所期望的介面。
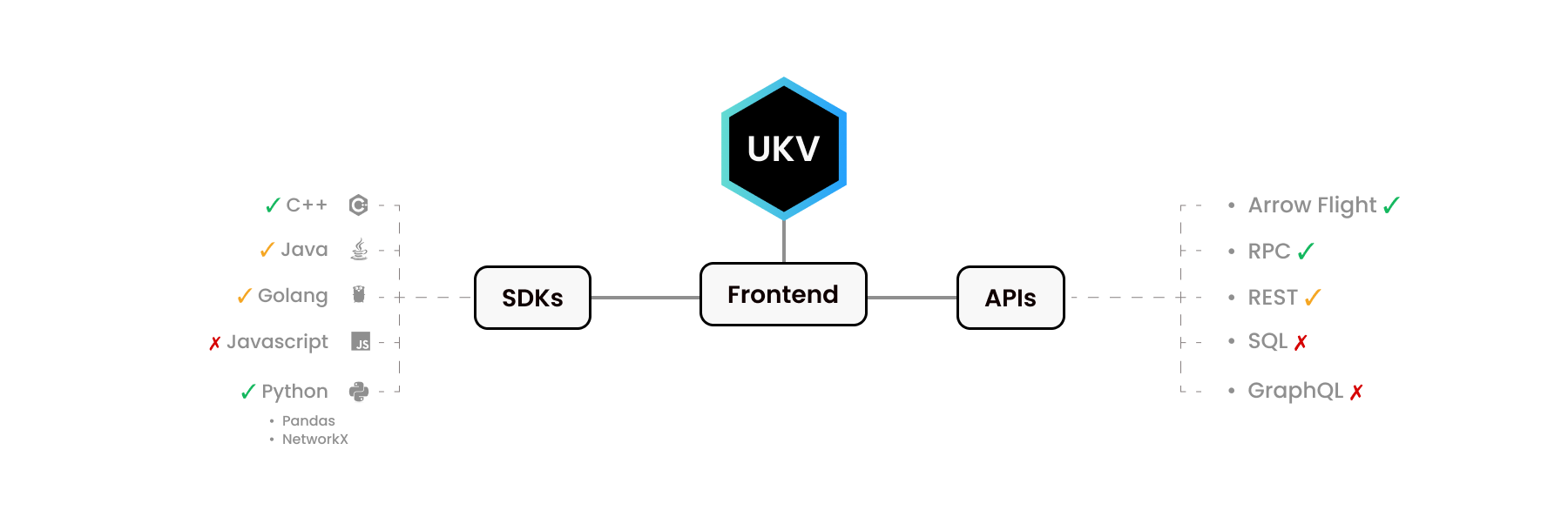
眾所周知,人們會出於不同的目的使用不同的語言。某些語言未實現某些 C 級功能。要嘛是因為沒有需求,要嘛是因為我們還沒做到這一點。
| 姓名 | 辦理 | 收藏 | 批次 | 文件 | 圖表 | 副本 |
|---|---|---|---|---|---|---|
| C99標準 | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| C++ SDK | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| Python SDK | ✓ | ✓ | ✓ | ✓ | ✓ | 0-1 |
| Go語言SDK | ✓ | ✓ | ✓ | ✗ | ✗ | 1 |
| Java SDK | ✓ | ✓ | ✗ | ✗ | ✗ | 1 |
| 箭飛行 API | ✓ | ✓ | ✓ | ✓ | ✓ | 0-2 |
這裡的一些前端周圍有整個生態系統!例如,Apache Arrow Flight API 擁有自己的 C、C++、C#、Go、Java、JavaScript、Julia、MATLAB、Python、R、Ruby 和 Rust 驅動程式。
以下引擎幾乎可以互換使用。從歷史上看,LevelDB 是第一個。 RocksDB 隨後改進了功能和效能。現在它成為一半 DBMS 新創公司的基礎。
| 水平資料庫 | Rocks資料庫 | 磁碟 | UC集 | |
|---|---|---|---|---|
| 速度 | 1x | 2x | 10倍 | 30倍 |
| 執著的 | ✓ | ✓ | ✓ | ✗ |
| 交易性 | ✗ | ✓ | ✓ | ✓ |
| 區塊設備支援 | ✗ | ✗ | ✓ | ✗ |
| 加密 | ✗ | ✗ | ✓ | ✗ |
| 手錶 | ✗ | ✓ | ✓ | ✓ |
| 快照 | ✓ | ✓ | ✓ | ✗ |
| 隨機抽樣 | ✗ | ✗ | ✓ | ✓ |
| 批次枚舉 | ✗ | ✗ | ✓ | ✓ |
| 命名集合 | ✗ | ✓ | ✓ | ✓ |
| 開源 | ✓ | ✓ | ✗ | ✓ |
| 相容性 | 任何 | 任何 | Linux | 任何 |
| 維護者 | 烏努姆 | 烏努姆 |
UCSet 和 UDisk 均由 Unum 設計和維護。兩者的功能都很齊全,但我們的替代方案提供的最關鍵的功能是效能。記憶力快很容易。 UCSet 的核心邏輯可以在模板化的僅標頭ucset庫中找到。
設計 UDisk 是一項更具挑戰性的工作,歷時 7 年。它包括發明新的樹狀結構、使用io_uring實現部分核心旁路、使用SPDK實現完全旁路、CUDA GPU 加速,甚至自訂內部檔案系統。 UDisk 是第一個從頭開始設計並考慮並行架構和核心旁路的引擎。
原子性始終得到保證。即使在非事務性寫入上 - 要么所有更新都通過,要么全部失敗。
一致性以盡可能嚴格的形式實現 - “嚴格可串行化”意味著:
但是,可以在特定操作層級調整預設行為。為此, ::ustore_option_transaction_dont_watch_k可以傳遞給ustore_transaction_init()或任何事務性讀取/寫入操作,以控制暫存期間的一致性檢查。
| 讀 | 寫 | |
|---|---|---|
| 頭 | 嚴格系列 | 嚴格系列 |
| 透過快照進行交易 | 序列 | 嚴格系列 |
| 沒有快照的交易 | 嚴格系列 | 嚴格系列 |
| 不含手錶的交易 | 嚴格系列 | 順序 |
如果您對這個主題不熟悉,請查看有關一致性的 Jepsen.io 部落格。
| 讀 | 寫 | |
|---|---|---|
| 透過快照進行交易 | ✓ | ✓ |
| 沒有快照的交易 | ✗ | ✓ |
根據定義,持久性不適用於記憶體系統。在混合或持久系統中,我們更喜歡預設禁用它。幾乎每個建置在 KVS 之上的 DBMS 都喜歡實作自己的持久性機制。在分散式資料庫中更是如此,其中可能存在三個單獨的預寫日誌:
如果您仍然需要持久性,請使用可選標誌刷新寫入提交。在 C 驅動程式中,您可以使用::ustore_option_write_flush_k標誌來呼叫ustore_transaction_commit() 。
整個 DBMS 適合小於 100 MB 的 Docker 映像。執行以下腳本來拉取並運行容器,在連接埠38709上公開 Apache Arrow Flight 伺服器。預設情況下,客戶端 SDK 也將透過相同連接埠進行通訊。
docker run -d --rm --name ustore-test -p 38709:38709 unum/ustore可以透過以下方式檢索預設設定檔:
cat /var/lib/ustore/config.json連接和測試的最簡單方法是使用以下命令:
python ...預先包裝的 UStore 鏡像可在多個平台上使用:
不要猶豫,將 UStore 商業化並重新分發。
調整資料庫既是一門藝術,也是一門科學。像 RocksDB 這樣的專案提供了數十個旋鈕來優化行為。我們允許將專門的設定檔轉送到底層引擎。
{
"version" : " 1.0 " ,
"directory" : " ./tmp/ "
}我們還有一個更簡單的程序,對於 80% 的用戶來說已經足夠了。可以擴展以利用多個設備或目錄,或轉發專門的引擎配置。
{
"version" : " 1.0 " ,
"directory" : " /var/lib/ustore " ,
"data_directories" : [
{
"path" : " /dev/nvme0p0/ " ,
"max_size" : " 100GB "
},
{
"path" : " /dev/nvme1p0/ " ,
"max_size" : " 100GB "
}
],
"engine" : {
"config_file_path" : " ./engine_rocksdb.ini " ,
}
}資料庫集合也可以使用 JSON 檔案進行設定。
從目前版本開始,使用 64 位元有符號整數。它允許[0, 2^63)範圍內的唯一鍵。帶有 UUID 的 128 位元版本即將推出,但強烈建議不要使用可變長度金鑰。為什麼會這樣呢?
使用可變長度金鑰對鍵值儲存的設計施加了許多限制。首先,它意味著緩慢的字元比較——現代超標量 CPU 的效能殺手。其次,它強制將鍵和值連接到磁碟上,以最大限度地減少導航所需的元資料。最後,它違反了我們將 KVS 作為「持久記憶體分配器」的簡單邏輯視圖,為它帶來了更多的責任。
處理字串鍵的推薦方法是:
這將導致從字串到整數表示的單一轉換點,並使大部分系統保持敏捷,並且 C 級介面比它們原本應有的更簡單。
目前我們只能處理 4 GB 或更小的值。為什麼?鍵值儲存通常用於高頻操作。通常(每秒數千次),在現代硬體上存取和修改 4 GB 及更大的檔案是不可能的。因此,我們堅持使用較小長度的類型,使使用 Apache Arrow 表示稍微容易一些,並允許 KVS 更好地壓縮索引。
我們的開發路線圖是公開的,並託管在 GitHub 儲存庫中。即將到來的任務包括:
請在此處閱讀我們文件中的完整路線圖。


