aiwhispr
version 0.941
AIWhispr 是一種無/低程式碼工具,用於自動化向量嵌入管道以進行語義搜尋。一個簡單的配置即可驅動讀取檔案、提取文字、建立向量嵌入並將其儲存在向量資料庫中的管道。
人工智慧耳語

AIWhispr 具有以下向量資料庫的連接器
1Qdrant
2 米爾烏斯
3 維阿特
4 類型感應
5、MongoDB
6 Postgres - PGVector
請確保您已安裝並啟動向量資料庫。
AIWISPR_HOME_DIR 環境變數應該是 aiwhispr 目錄的完整路徑。
AIWISPR_LOG_LEVEL環境變數可以設定為DEBUG / INFO / WARNING / ERROR
AIWHISPR_HOME=/<...>/aiwhispr
AIWHISPR_LOG_LEVEL=DEBUG
export AIWHISPR_HOME
export AIWHISPR_LOG_LEVEL
請記住在 shell 登入腳本中新增環境變量
運行以下命令
$AIWHISPR_HOME/shell/install_python_packages.sh
如果 uwsgi 安裝失敗,請確保安裝了 gcc、python-dev 、 python3-dev 。
sudo apt-get install gcc
sudo apt install python-dev
sudo apt install python3-dev
pip3 install uwsgi
AIWhispr 附帶了一個 Streamlit 應用程式來幫助您入門。
運行streamlit應用程式
cd $AIWHISPR_HOME/python/streamlit
streamlit run ./Configure_Content_Site.py &
這應該會在預設連接埠 8501 上啟動一個 Streamlit 應用程序,並在您的 Web 瀏覽器上啟動一個會話
配置管道以對內容進行索引以進行語義搜尋需要執行 3 個步驟。
1.配置從儲存位置讀取文件
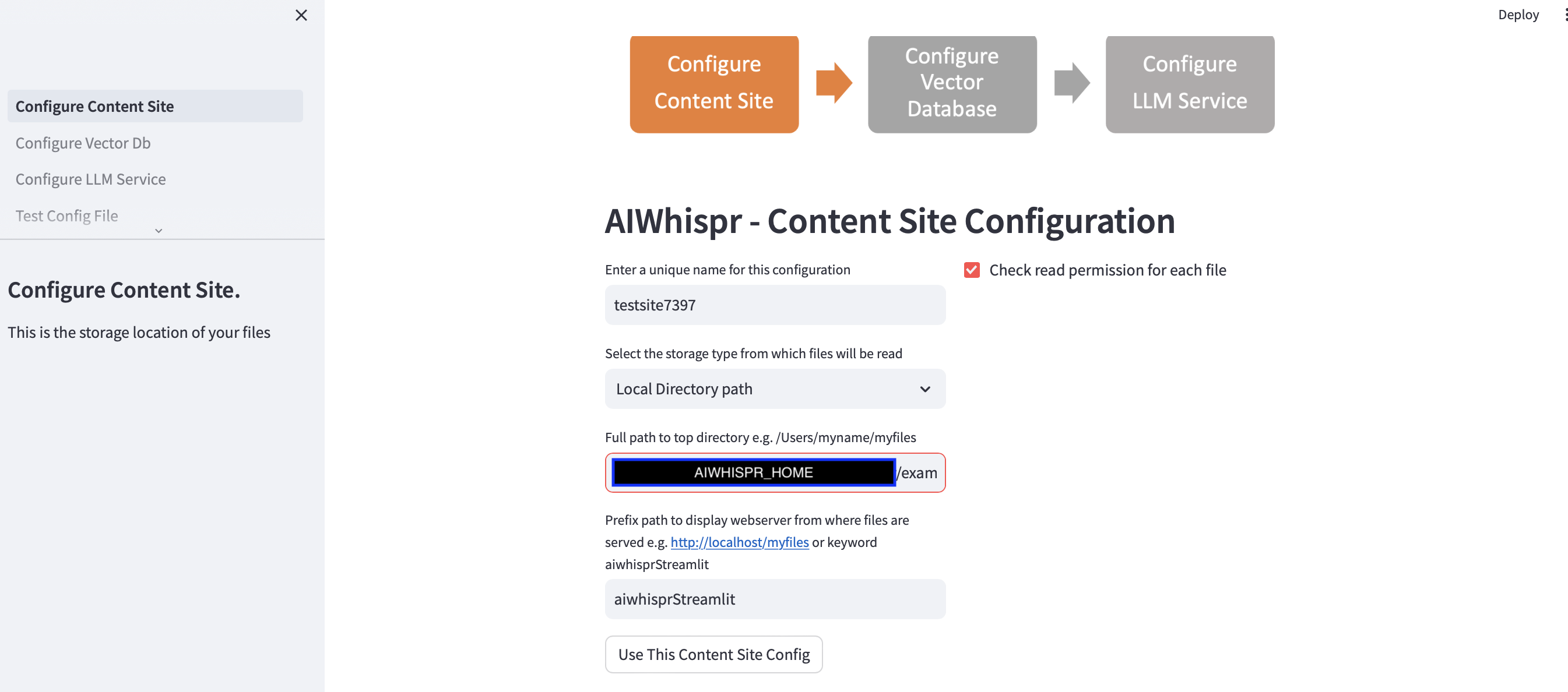
您可以透過點擊“使用此內容網站配置”按鈕繼續預設配置
並進入下一步配置向量資料庫連線。
預設範例將為 BBC 的新聞報導編制索引以進行語義搜尋。
Streamlit 應用程式假定您正在開始新配置,並將分配隨機配置名稱。您可以覆蓋它以給它一個更有意義的名稱。配置名稱應該是唯一的;它不能包含空格或特殊字元。
預設配置將從本機目錄路徑 $AIWISPR_HOME/examples/http/bbc 讀取內容
其中包含來自 BBC 的 2000 多個新聞報道,這些新聞報道已編入索引以進行語義搜尋。
您可以選擇讀取儲存在 AWS S3、Azure Blob、Google Cloud Storage 上的內容。
前綴路徑配置用於為搜尋結果建立 href Web 連結。您可以繼續使用預設關鍵字“aiwhisprStreamlit”
按一下「使用此內容網站配置」按鈕,然後按一下左側側邊欄中的「配置向量資料庫」進入下一步以配置向量資料庫連線。
2.配置向量資料庫
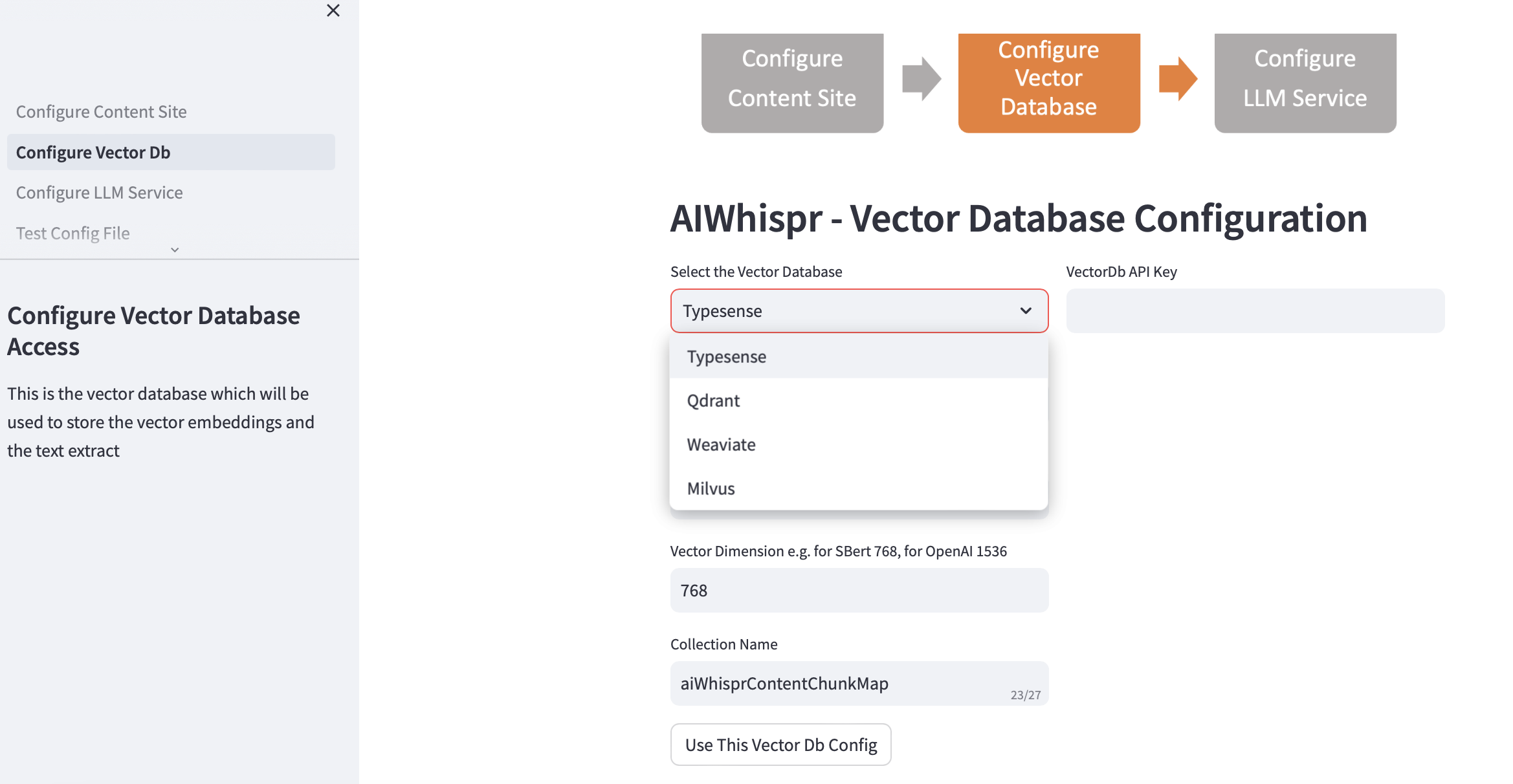
選擇您的向量資料庫並提供連接詳細資訊。
當您選擇向量資料庫時,Vector Db IP 位址和連接埠號碼將根據預設安裝進行填入。您可以根據您的設定更改此設定。
您的向量資料庫應該配置為進行身份驗證。對於 Qdrant、Weaviate、Typesense,需要 API 金鑰。對於 Milvus,應設定使用者 ID 和密碼組合。
應根據您計劃用於將文字編碼為向量嵌入的 LLM 來指定向量維度大小。範例:對於 Open AI“text-embedding-ada-002”,應配置為 1536,這是 OpenAI 嵌入服務傳回的向量的大小。
在向量資料庫中建立的預設集合名稱是 aiwhisprContentChunkMap。您可以指定自己的集合名稱。
按一下「使用此向量資料庫配置」按鈕,然後按一下左側側邊欄中的「配置 LLM 服務」進入下一步。
3.配置LLM服務
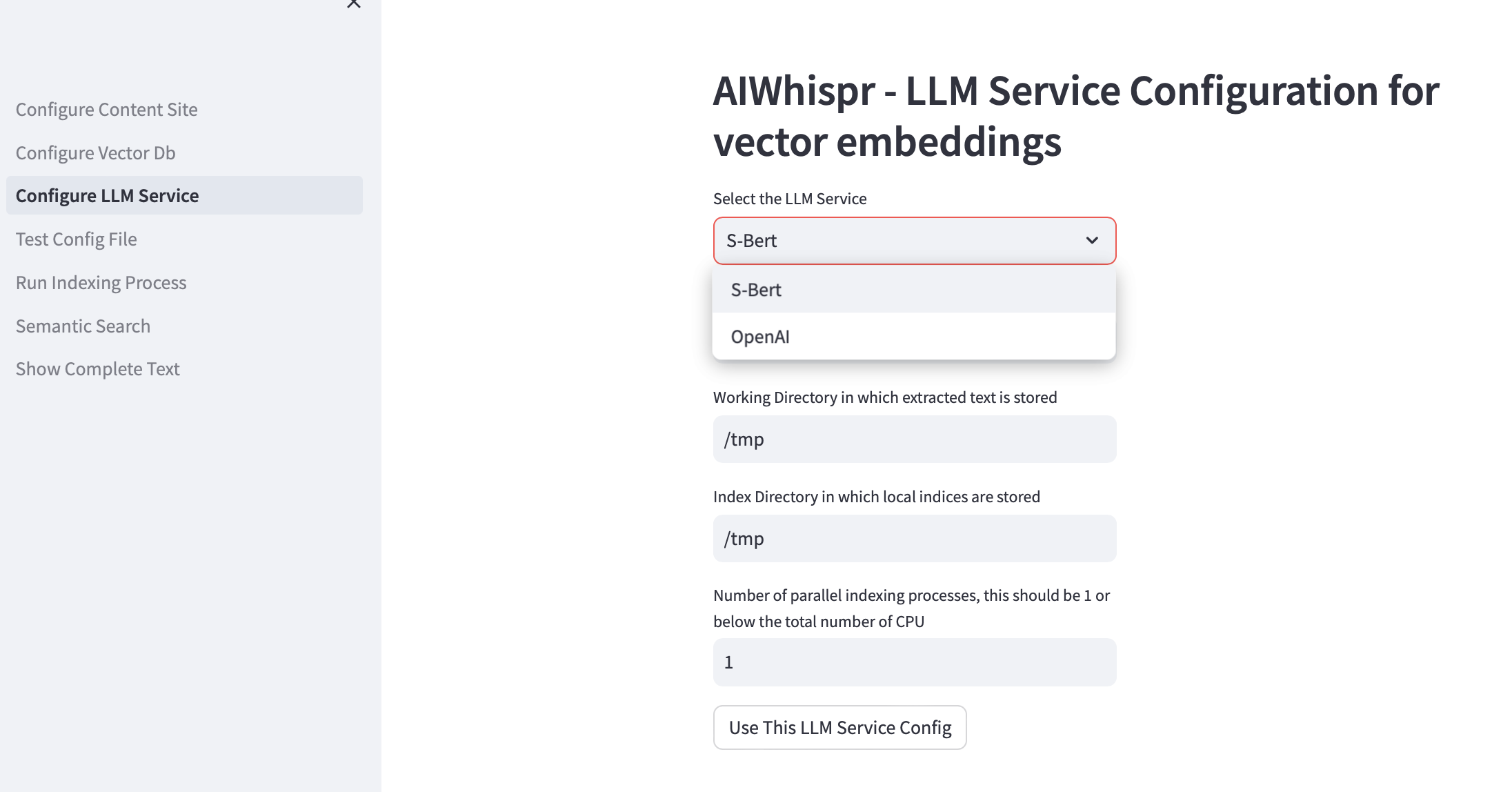
您可以選擇使用本地運行的 Sbert 預訓練模型或使用 OpenAI API 建立向量嵌入。
對於 SBert 模型系列,使用的預設模型是 all-mpnet-base-v2。您可以指定另一個 SBert 模型。
對於 OpenAI,預設嵌入模型是 text-embedding-ada-002
預設工作目錄是/tmp
工作目錄是本地電腦上的位置,它將用作處理從儲存位置讀取/下載的檔案的工作目錄。然後,從文件中提取的文字被分成較小的大小,通常為 700 個單詞,然後編碼為向量嵌入。工作目錄用於儲存文字區塊。
預設本地索引目錄是/tmp
您可以為工作目錄和索引目錄指定持久的本機目錄路徑。
index-dir 用於儲存必須讀取的內容檔案的索引清單。 AIWhispr 支援多個進程進行索引,每個進程將使用自己的索引列表,從而允許您利用電腦上的多個 CPU。
如果您想利用多個 CPU 進行索引(讀取內容、建立向量嵌入、儲存在向量資料庫中),請在測試框中指定並行進程數。我們的建議是該值應為 1 或最大值(CPU 數量/2)。例如,在 8 CPU 機器上,此值應設定為 4。
按一下「使用此 LLM 服務配置」以建立向量嵌入管道設定檔的最終版本。
將顯示設定檔的內容及其在電腦上的位置。
您可以透過點擊左側邊欄中的「測試設定檔」來測試此配置。
4. 測試配置
現在您應該看到一條訊息,顯示向量嵌入管道設定檔的位置和一個按鈕“測試設定檔”
單擊該按鈕將啟動該過程,該過程將測試管道配置
您應該在日誌末尾看到“NO ERRORS”訊息,通知您可以使用此管道配置。
點擊左側邊欄中的“運行索引程序”以啟動管道。
5. 運行索引過程
您應該會看到一個“開始索引”按鈕。
按一下此按鈕啟動管道。日誌每 15 秒更新一次。
預設範例索引 2000 多個 BBC 新聞報道,大約需要 20 分鐘。
當索引進程正在執行時,即當 Streamlit「正在執行」狀態顯示在右上角時,請勿離開此頁面。
您也可以在電腦上使用 grep 檢查索引進程是否正在執行。
ps -ef | grep python3 | grep index_content_site.py
6. 語義搜尋
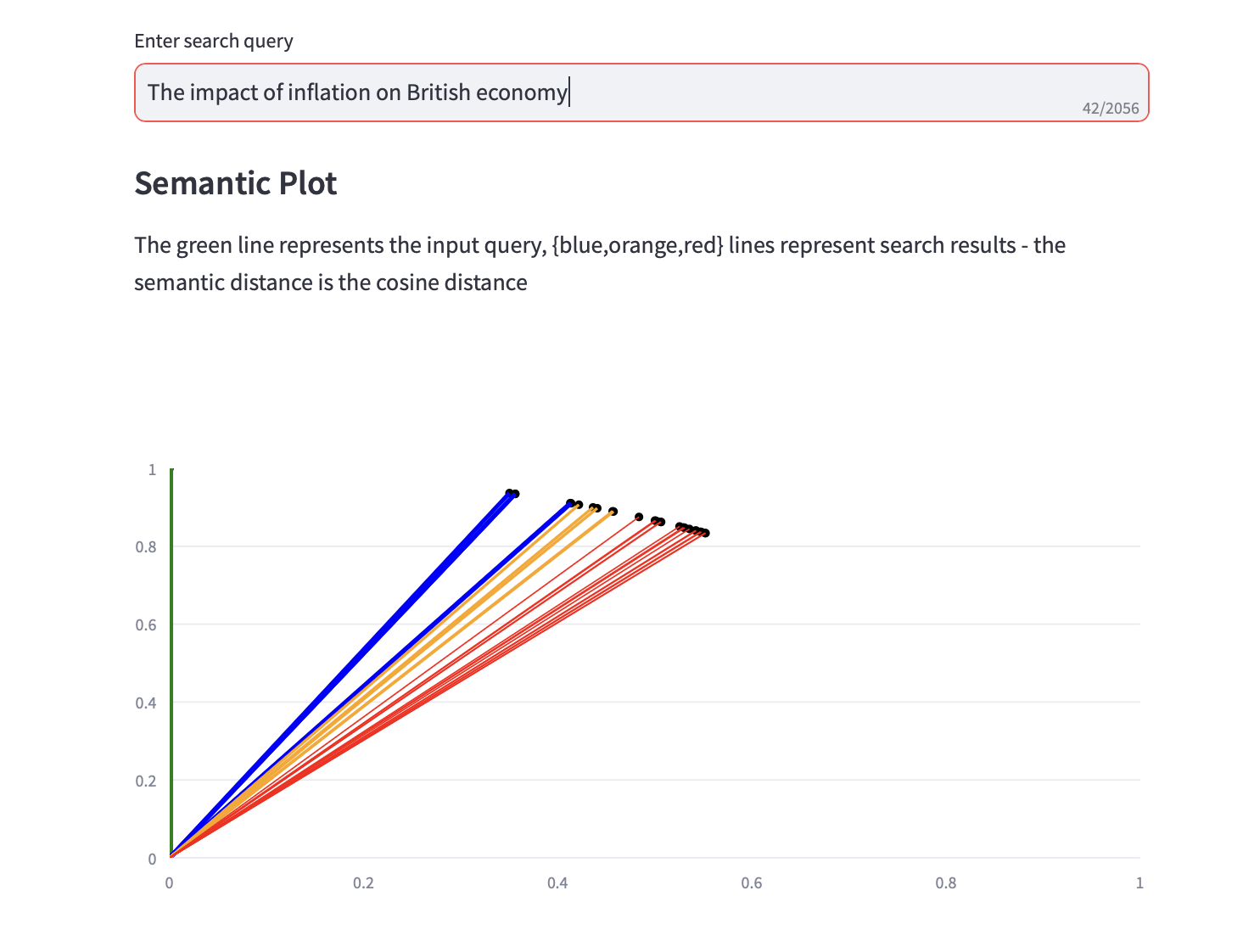
現在您可以執行語義搜尋查詢。
顯示餘弦距離的語義圖以及搜尋結果的前 3 個 PCA 分析也與文字搜尋結果一起顯示。