sandbox toy semantic search
1.0.0
################################################################################
# ____ _ ____ _ _ #
# / ___|___ | |__ ___ _ __ ___ / ___| __ _ _ __ __| | |__ _____ __ #
# | | / _ | '_ / _ '__/ _ ___ / _` | '_ / _` | '_ / _ / / #
# | |__| (_) | | | | __/ | | __/ ___) | (_| | | | | (_| | |_) | (_) > < #
# _______/|_| |_|___|_| ___| |____/ __,_|_| |_|__,_|_.__/ ___/_/_ #
# #
# This project is part of Cohere Sandbox, Cohere's Experimental Open Source #
# offering. This project provides a library, tooling, or demo making use of #
# the Cohere Platform. You should expect (self-)documented, high quality code #
# but be warned that this is EXPERIMENTAL. Therefore, also expect rough edges, #
# non-backwards compatible changes, or potential changes in functionality as #
# the library, tool, or demo evolves. Please consider referencing a specific #
# git commit or version if depending upon the project in any mission-critical #
# code as part of your own projects. #
# #
# Please don't hesitate to raise issues or submit pull requests, and thanks #
# for checking out this project! #
# #
################################################################################
維護者: jcudit 和 lsgos
計畫至少維持到(YYYY-MM-DD): 2023-03-14
這是如何使用 Cohere API 建立簡單語義搜尋引擎的範例。它並不是為了生產就緒或有效擴展(儘管可以適應這些目的),而是為了展示產生由 Cohere 大型語言模型 (LLM) 產生的表示形式支援的搜尋引擎的簡單性。
這裡使用的搜尋演算法相當簡單:它只是使用co.embed端點找到與問題的表示最匹配的段落。下面對此進行了更詳細的解釋,但這裡有一個簡單的圖表來說明正在發生的事情。首先,我們將輸入文字分解為一系列段落,將它們在輸入中的位址儲存到清單中,並使用co.embed為每個段落產生向量嵌入:
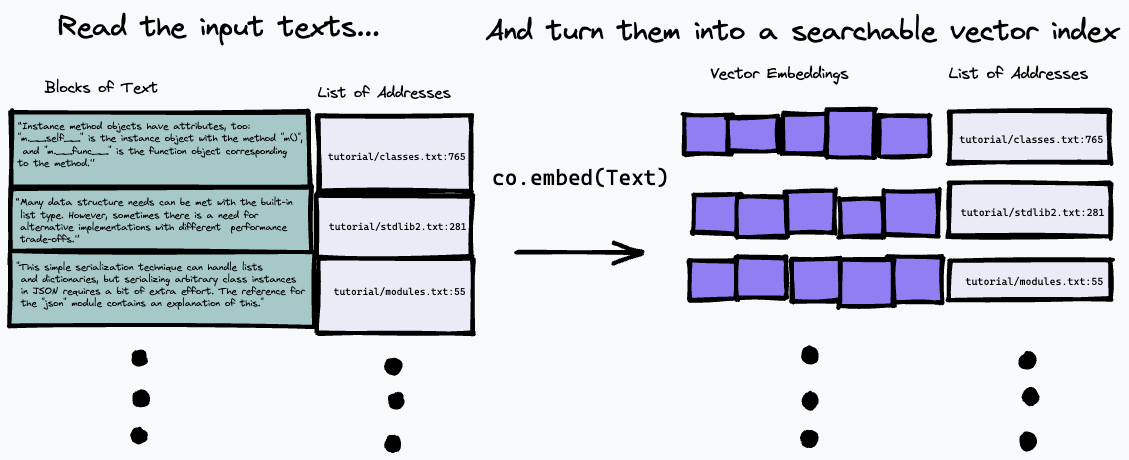
然後,我們可以透過嵌入文字查詢來查詢索引,並使用某種向量相似度量(我們使用餘弦相似度)來尋找來源文字中具有最接近匹配的段落: 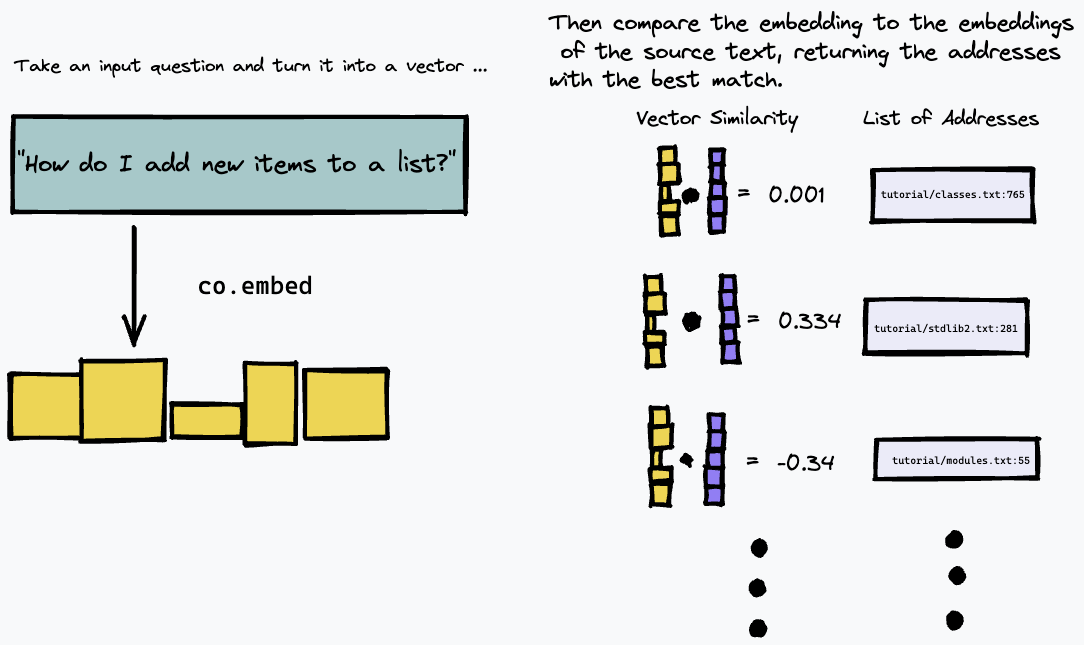
因此,它最適合文字來源,其中給定問題的答案可能由文本中的具體段落給出,例如技術文件或內部 wiki,它們被建構為具體說明或事實的清單。例如,它在回答有關小說等自由格式文本的問題時效果不佳,因為小說中的信息可能分散在幾個段落中;為此,您需要使用不同的方法來索引文字。
例如,該儲存庫在最新 python 文件的文字版本上建立了一個簡單的語義搜尋引擎。
要安裝 python 要求,請確保已安裝詩歌並運行:
# install python deps
poetry install您還應該安裝 docker。在 OS X 上,如果您使用自製程序,我們建議執行
brew install --cask docker在 OS X 上首次運行 docker(例如運行我們的伺服器)之前,請開啟 Docker 應用程式並授予其在系統上運行所需的權限。
您還需要在COHERE_TOKEN中有一個 Cohere API 金鑰。從 Cohere 平台取得一個(如果需要,建立帳戶),並將其寫入您的環境
export COHERE_TOKEN= < MY_API_KEY > (其中<MY_API_KEY>是您獲得的密鑰,不含<...>括號)。
或者,您可以將COHERE_TOKEN=<MY_API_KEY>作為附加參數傳遞給下面的任何make命令。
請依照以下步驟先建立文件集合的語意索引。這些步驟為官方 python 文件產生語義索引,但可以適用於任意資料收集。
首先,透過執行以下命令之一下載 python 文件。
如果你想快速開始,請運行
make download-python-docs-small將文件集限制為 python 教學。我們僅建議您進行快速測試,因為結果非常有限。
如果你想在整個 python 文件中測試搜尋引擎,請運行
make download-python-docs但請注意,生成嵌入將需要幾個小時(儘管這只需要完成一次)。
或者,如果您想嘗試自己的文本,只需將其作為.txt檔案下載到此儲存庫中名為txt/目錄中。
獲得一些文字後,我們需要將其處理為嵌入和地址的搜尋索引。
這可以透過使用命令來完成
make embeddings假設您的目標文字位於./txt/目錄下。
該命令將遞歸地搜尋./txt/目錄中具有.txt副檔名的文件,並建立一個包含每個段落的嵌入、文件名和行號的簡單資料庫。
警告:如果您有大量文字要搜索,這可能需要一些時間才能完成!
建置了embeddings.npz檔案後,您可以使用以下命令建立 docker 映像,該映像將提供一個簡單的 REST 應用程序,以允許您查詢您建立的資料庫:
make build然後您可以使用啟動伺服器
make run對於一個簡單的例子來說,這有點矯枉過正,但它的目的是反映建立大量文本的索引相對較慢的事實,並確保查詢引擎的速度很快。
如果您想將此項目用作實際應用程式的構建塊,您可能需要在伺服器體系結構中維護文字嵌入資料庫並使用輕量級用戶端對其進行查詢。將伺服器打包為 Docker 應用程式意味著透過將其部署到雲端服務來將其轉變為「真正的」應用程式非常簡單。
如果您為以下任何選項打開新的終端窗口,請記住運行
export COHERE_TOKEN= < MY_API_KEY > 到目前為止,最簡單的選擇是執行我們的幫助程式腳本:
scripts/ask.sh " My query here "來查詢資料庫。此腳本採用可選的第二個參數來指定所需結果的數量。
腳本彈出修改後的vim介面,指令如下:
q退出。頂部窗格將顯示文件中找到結果的位置。
伺服器運行後,您可以使用簡單的 REST API 對其進行查詢。您可以前往此處的/docs#/default/search_search_post直接探索 API。這是一個簡單的 JSON REST API;以下是如何使用curl查詢:
curl -X POST -H "Content-Type: application/json" -d '{"query": "How do I append to a list?", "num_results": 3}' http://localhost:8080/search
這將傳回長度為num_results的 JSON 列表,每個列表都包含與查詢最接近語義匹配的區塊的檔案名稱和行號( doc_url和block_url )。但您可能實際上只想閱讀文件中的部分內容,這是最好的答案。
當我們搜尋本機文字檔案時,使用命令列工具解析輸出實際上更容易一些;使用提供的 python 腳本utils/query_server.py在命令列上查詢它。 query_server.py以標準file_name:line_number:格式列印結果,因此我們可以利用vim的快速修復模式以一種很好的方式對實際結果進行分頁。
假設你的機器上有 vim,你可以簡單地
vim +cw -M -q <(python utils/query_server.py "my_query" --num_results 3)
讓 vim 在搜尋演算法傳回的位置開啟索引文字檔。 (使用:qall關閉視窗和快速修復導航器)。您可以使用:cn和:cp循環顯示傳回的結果。結果並不完美;這是語義搜索,因此您可能會期望匹配有點模糊。儘管如此,我經常發現你可以在前幾個結果中得到問題的答案,並且使用Cohere 的API 可以讓你用自然語言表達你的問題,並且讓你只需幾行程式碼就可以建立一個非常有效的搜尋引擎.
python 文件案例中的一些值得嘗試的查詢表明搜尋在通用自然語言問題上運作良好,包括:
How do I put new items in a list? (請注意,這個問題避免使用關鍵字“append”,並且與文件解釋append的方式不完全匹配(他們說它用於將新項目添加到列表的末尾)。但是語義搜尋正確地指出相關段落仍然是最佳匹配。How do I put things in a list?Are dictionary keys in insertion order?What is the difference between a tuple and a list? (注意這個問題,我的第一個結果是關於基本上這個確切主題的常見問題解答,但問題措辭不同。但是,由於它是語義搜索,我們的算法正確地挑選出與含義匹配的結果,而不僅僅是我們的查詢的措辭)How do I remove an item from a set?How do list comprehensions work?該存儲庫使用非常簡單的策略來索引文件並蒐索最佳匹配。首先,它將每個文件分成段落或「區塊」。然後,它在每個段落上呼叫co.embed ,以便使用 Cohere 的語言模型產生向量嵌入。然後,它將每個嵌入向量以及相應的文檔和段落的行號儲存在一個簡單的陣列中作為「資料庫」。
為了實際進行搜索,我們使用 FAISS 相似性搜尋庫。當我們收到查詢時,我們使用相同的 Cohere API 呼叫來嵌入查詢。然後我們使用 FAISS 來找到頂部
如果您有任何問題或意見,請提出問題或透過 Discord 與我們聯絡。
如果您想為此專案做出貢獻,請閱讀此儲存庫中的CONTRIBUTORS.md ,並在提交任何拉取請求之前簽署貢獻者許可協議。當您第一次向 Cohere 儲存庫發出拉取請求時,將會產生一個用於簽署 Cohere CLA 的連結。
Toy Semantic Search 具有 MIT 許可證,如 LICENSE 文件所示。


