wagtail_textract
1.0.0
該軟體包未維護,我們也沒有計劃維護它。
我們建議您使用它作為範例,也許將程式碼複製到您自己的專案中,但不要安裝該套件。
該套件用於將 Wagtail 的 Document 類別替換為允許使用 textract 在文件文件內容中搜尋的類別。
Textract 可以從(以及其他)PDF、Excel 和 Word 文件中提取文字。
該套件的靈感來自 Wagtail 中的「搜尋:從文件中提取文字」問題。
文件將像以前一樣工作,只是 Wagtail 管理介面中的文件搜尋也會在文件內容中尋找搜尋字詞。
一些螢幕截圖來說明。
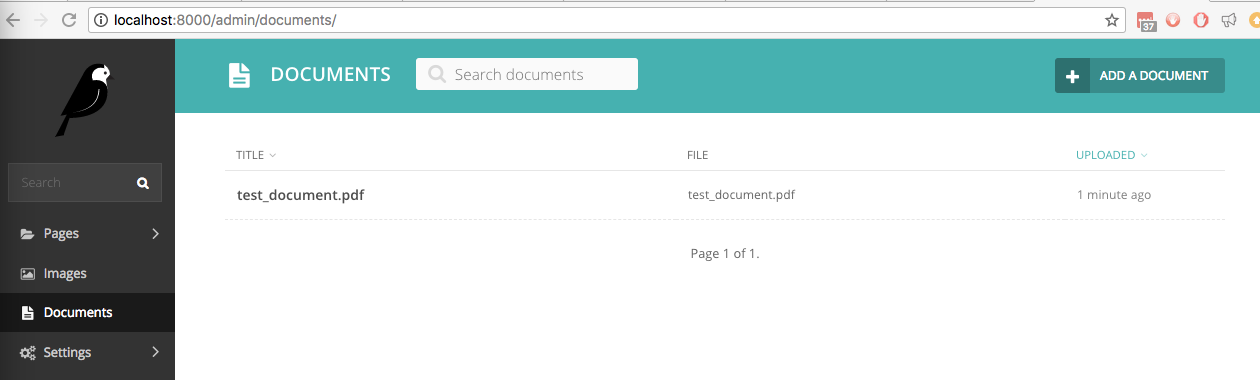
在安裝了wagtail_textract的新 Wagtail 網站中,我們上傳了一個名為test_document.pdf的文件,其中包含手寫文字。它列在管理介面的文檔下:
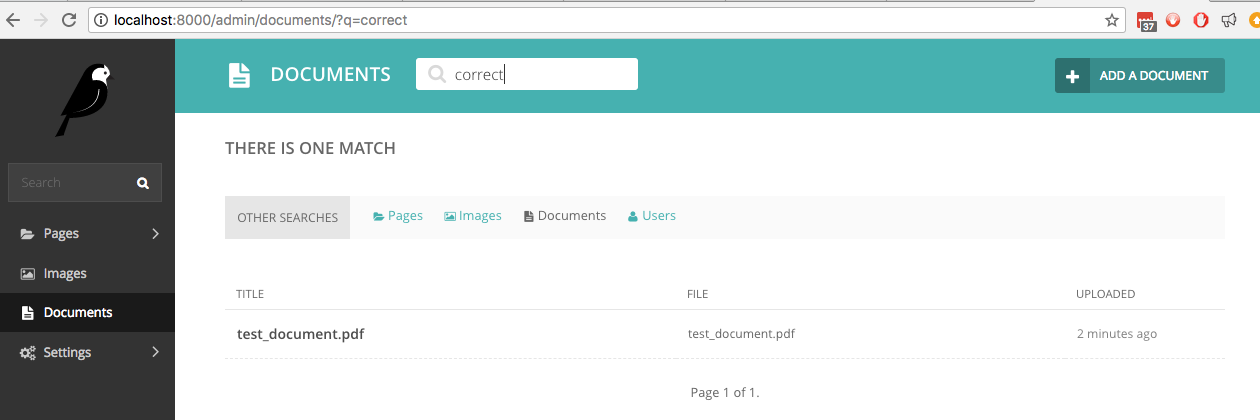
如果我們現在在文件中搜尋單字correct ,這是手寫單字之一,即時搜尋會找到它:
假設這個搜尋不僅應該在 Wagtail 的管理介面中可用,而且還應該在面向公眾的搜尋視圖中可用,我們為此提供了一個程式碼範例。
自 2018 年 8 月以來,我們一直在 https://nuffic.nl 上的生產中使用此套件。
wagtail_textract新增至您的要求和/或pip install wagtail_textractINSTALLED_APPS 。WAGTAILDOCS_DOCUMENT_MODEL = "wagtail_textract.document"加入 Django 設定中。注意:在安裝 wagtail_texttract 期間您會收到不相容警告(已安裝 Wagtail 2.0.1):
requests 2.18.4 has requirement chardet<3.1.0,>=3.0.2, but you'll have chardet 2.3.0 which is incompatible.
textract 1.6.1 has requirement beautifulsoup4==4.5.3, but you'll have beautifulsoup4 4.6.0 which is incompatible.
我們還沒有看到這會導致問題,但需要記住這一點。
為了使textract使用 Tesseract(如果常規textract找不到文本,就會發生這種情況),您需要添加 Tesseract 可以基於其單字匹配的資料檔案。
在你的專案目錄下建立tessdata目錄,然後下載你想要的語言。
文件保存後,轉錄在asyncio執行器中自動完成,以防止在處理過程中阻塞回應。
若要轉錄所有現有文檔,請執行管理命令:
./manage.py transcribe_documents
顯然,這可能需要很長時間。
以下是顯示頁面和文件結果的搜尋視圖(在 Wagtail 管理介面之外)的程式碼範例。
from itertools import chain
from wagtail . core . models import Page
from wagtail . documents . models import get_document_model
def search ( request ):
# Search
search_query = request . GET . get ( 'query' , None )
if search_query :
page_results = Page . objects . live (). search ( search_query )
document_results = Document . objects . search ( search_query )
search_results = list ( chain ( page_results , document_results ))
# Log the query so Wagtail can suggest promoted results
Query . get ( search_query ). add_hit ()
else :
search_results = Page . objects . none ()
# Render template
return render ( request , 'website/search_results.html' , {
'search_query' : search_query ,
'search_results' : search_results ,
})您的範本應該允許以不同於頁面的方式處理文檔,因為您無法在文檔上執行pageurl result :
{% if result . file %}
< a href = " {{ result.url }} " >{{ result }}</ a >
{% else %}
< a href = " {% pageurl result %} " >{{ result }}</ a >
{% endif %} 為了使用 wagtail_texttract,您的CustomizedDocument模型應該與 wagtail_textract 的 Document 執行相同的操作:
TranscriptionMixinsearch_fields from wagtail_textract . models import TranscriptionMixin
class CustomizedDocument ( TranscriptionMixin , ...):
"""Extra fields and methods for Document model."""
search_fields = ... + [
index . SearchField (
'transcription' ,
partial_match = False ,
),
]請注意,子類別的第一個類別應該是TranscriptionMixin ,因此它的save()優先於其他父類別的 save() 。
要運行測試,請查看此存儲庫並:
make test
覆蓋率報告將在./coverage_html_report/中產生。


