SeekStorm
v0.11.0

SeekStorm是一個用Rust實現的開源、亞毫秒全文搜尋庫和多租戶伺服器。
開發於 2015 年開始,自 2020 年開始生產,Rust 端口於 2023 年,2024 年開源,工作正在進行中。
SeekStorm 是根據 Apache License 2.0 授權的開源軟體
部落格文章:SeekStorm 現已開源,SeekStorm 提供分面搜尋、地理位置鄰近搜尋、結果排序
查詢類型
結果類型
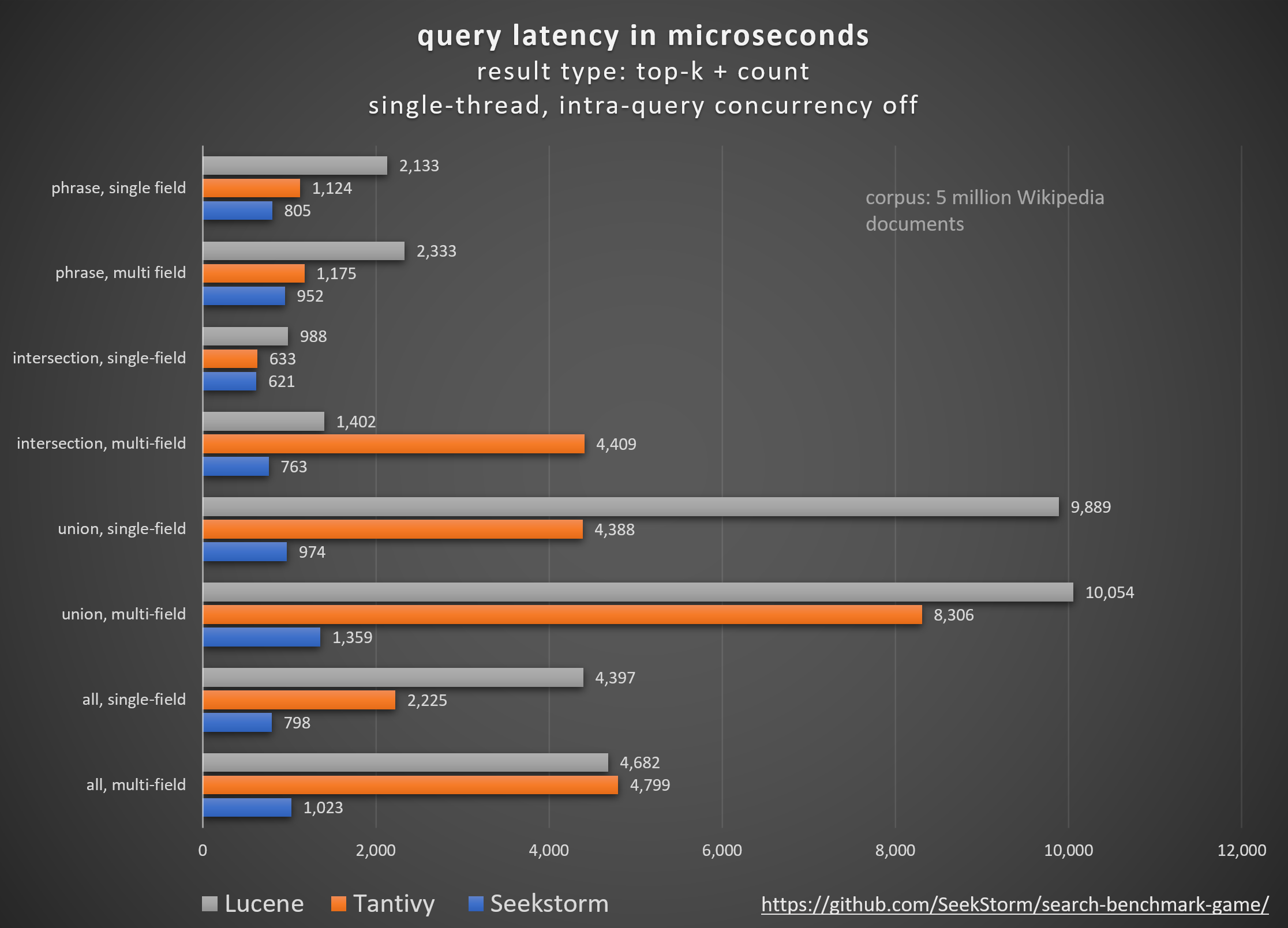
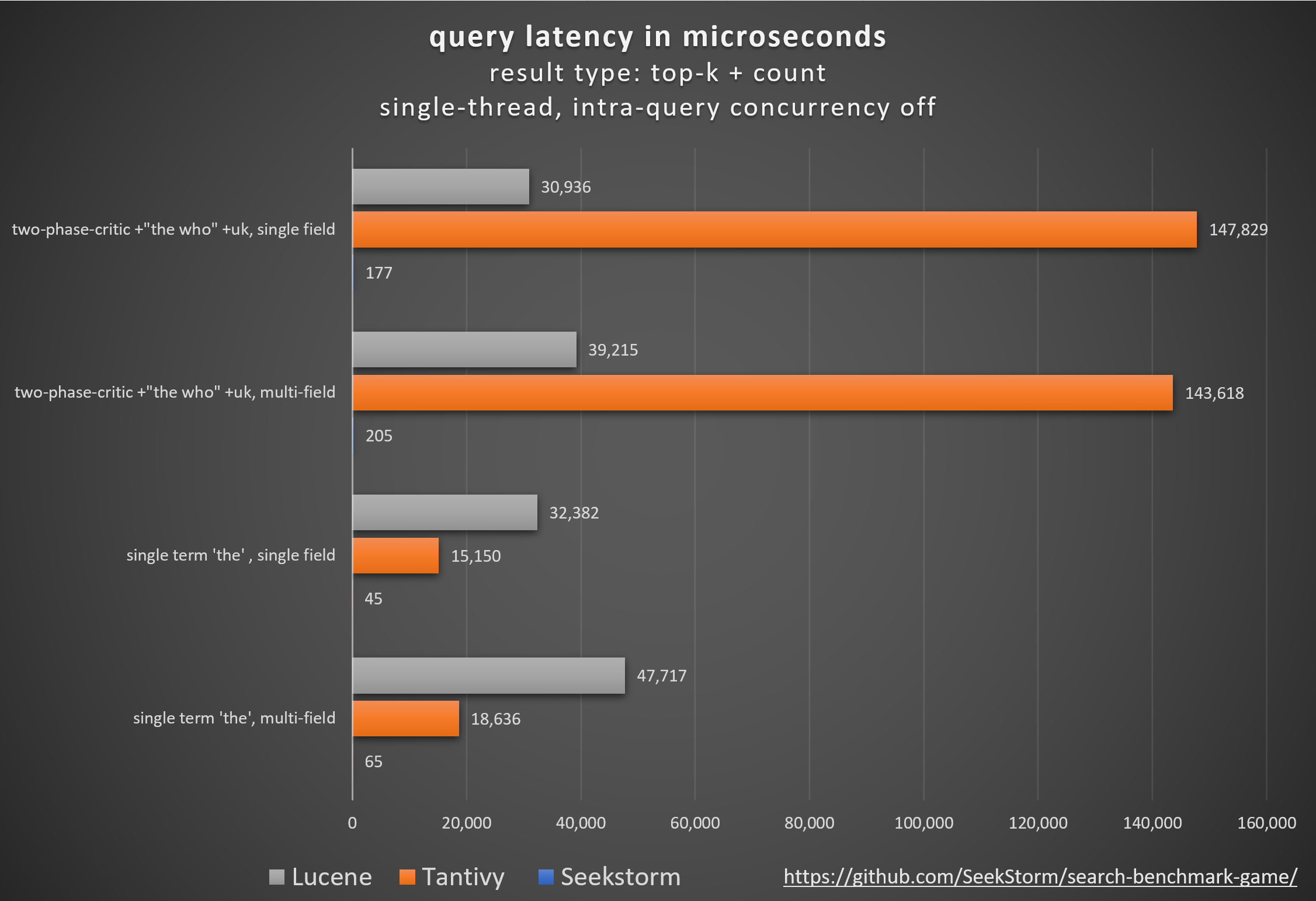
表現
更低的延遲、更高的吞吐量、更低的成本和能耗,尤其是。用於多字段和並發查詢。
低尾延遲可確保流暢的使用者體驗並防止客戶和收入的損失。
雖然有些依賴專有硬體加速器 (FPGA/ASIC) 或叢集來提高效能,
SeekStorm 在單一商品伺服器上透過演算法實現了類似的提升。
一致性
由於 SeekStorm 不需要資源密集型段合併,因此在大容量索引期間和之後不會出現不可預測的查詢延遲。
穩定的延遲 - 由於即時編譯而沒有冷啟動成本,沒有不可預測的垃圾收集延遲。
縮放
即使對於十億級索引,也能保持低延遲、高吞吐量和低 RAM 消耗。
無限的欄位數量、欄位長度和索引大小。
關聯
與 BM25 相比,術語鄰近度排名提供了更相關的結果。
即時的
真正的即時搜索,與 NRT 不同:每個索引文件都可以立即搜索,甚至在提交之前和期間也是如此。
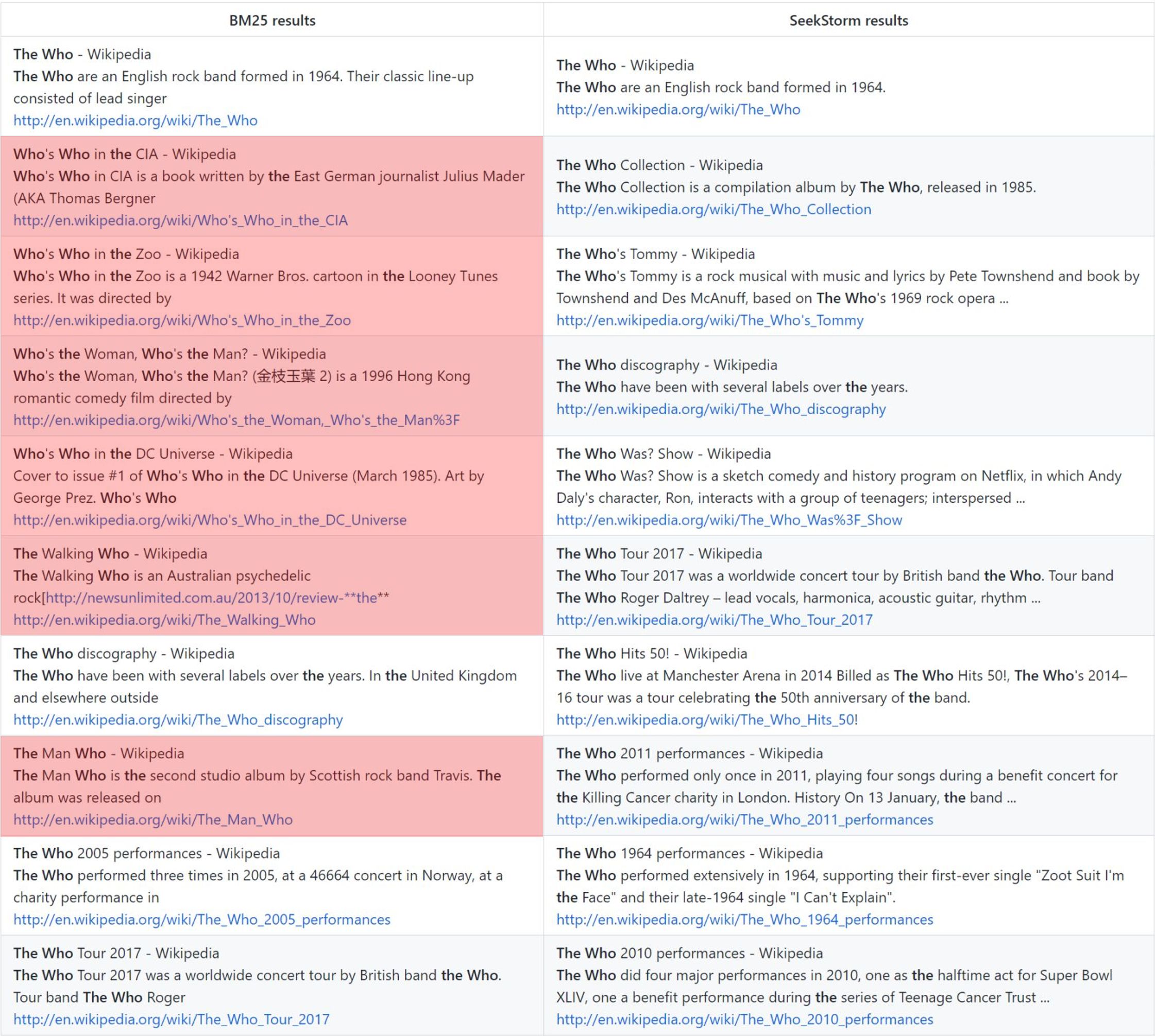
the who:香草 BM25 排名與 SeekStorm 鄰近排名
方法論
使用 Tantivy 和 Jason Wolfe 開發的開源search_benchmark_game比較不同的開源搜尋引擎庫(BM25 詞彙搜尋)。
好處
詳細的基準測試結果https://seekstorm.github.io/search-benchmark-game/
基準程式碼儲存庫https://github.com/SeekStorm/search-benchmark-game/
請參閱我們的部落格文章以獲取更多詳細資訊:SeekStorm 現已開源,SeekStorm 提供分面搜尋、地理位置鄰近搜尋、結果排序
不管炒作週期 https://www.bitecode.dev/p/hype-cycles 希望您相信什麼,關鍵字搜尋並沒有消亡,因為 NoSQL 並不是 SQL 的消亡。
您應該維護一個工具箱,並選擇最適合您手邊任務的工具。 https://seekstorm.com/blog/vector-search-vs-keyword-search1/
關鍵字搜尋只是一組文檔的過濾器,會傳回出現某些關鍵字的文檔,通常與 BM25 等排名指標結合。這是一個非常基本和核心的功能,以低延遲大規模實現非常具有挑戰性。由於功能非常基礎,因此應用領域的數量是無限的。它是一個組件,需要與其他組件一起使用。如今,有些用例可以透過向量搜尋和法學碩士來更好地解決,但對於更多的情況,關鍵字搜尋仍然是最佳解決方案。關鍵字搜尋精確、無損,速度非常快,具有更好的擴展性、更好的延遲、更低的成本和能耗。向量搜尋利用語意相似性,傳回具有給定鄰近度和機率的結果。
如果您搜尋確切的結果,例如專有名稱、數字、車牌、網域名稱和短語(例如抄襲檢測),那麼關鍵字搜尋就是您的朋友。另一方面,向量搜尋會將您正在尋找的確切結果隱藏在僅在語義上相關的無數結果中。同時,如果您不知道確切的術語,或者您對更廣泛的主題、含義或同義詞感興趣,那麼無論使用什麼確切的術語,關鍵字搜尋都會失敗。
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.如果您不知道確切的查詢術語,或者您對更廣泛的主題、含義或同義詞感興趣,無論使用什麼確切的查詢術語,向量搜尋都是完美的選擇。但如果您正在尋找確切的術語,例如專有名稱、數字、車牌、網域和短語(例如抄襲檢測),那麼您應該始終使用關鍵字搜尋。向量搜尋只會將您正在尋找的確切結果隱藏在無數僅以某種方式相關的結果中。它具有良好的召回率,但精確度較低,延遲較高。它很容易出現誤報,例如在抄襲檢測中,因為精確的單字和詞序會遺失。
向量搜尋不僅可以搜尋相似的文本,還可以搜尋所有可以轉換為向量的內容:文字、圖像(人臉辨識、指紋)、音頻,並且可以讓您做一些神奇的事情,例如女王- 女人+ 男人=國王。
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generation向量搜尋並不是關鍵字搜尋的替代品,而是一種補充——最好在結合了兩種方法優勢的混合解決方案中使用。關鍵字搜尋並沒有過時,而是經過時間考驗的。
我們已(部分)將 SeekStorm 程式碼庫從 C# 移植到 Rust
Rust 非常適合處理大數據和/或許多並髮用戶的效能關鍵型應用程式。快速演算法將在註重效能的程式語言的幫助下更加閃耀?
參見 ARCHITECTURE.md
cargo build --release
警告:確保將 MASTER_KEY_SECRET 環境變數設為機密,否則您產生的 API 金鑰將受到損害。
https://docs.rs/seekstorm
建構文檔
cargo doc --no-deps
本地存取文檔
SeekStormtargetdocseekstormindex.html
SeekStormtargetdocseekstorm_serverindex.html
將所需的 crate 加入您的專案中
cargo add seekstorm
cargo add tokio
cargo add serde_json use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;使用非同步 Rust 運行時
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {建立索引
let index_path= Path :: new ( "C:/index/" ) ;
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let _index_arc = Arc :: new ( RwLock :: new ( index ) ) ;開啟索引(或建立索引)
let index_path= Path :: new ( "C:/index/" ) ;
let mut index_arc= open_index ( index_path , false ) . await . unwrap ( ) ; 索引文件
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; 提交文件
index_arc . commit ( ) . await ;搜尋索引
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter ) . await ;顯示結果
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_string ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter= Some ( highlighter ( & index_arc , highlights , result_object . query_term_strings ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let mut index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}多執行緒搜尋
let query_vec= vec ! [ "house" .to_string ( ) , "car" .to_string ( ) , "bird" .to_string ( ) , "sky" .to_string ( ) ] ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Union ;
let result_type= ResultType :: TopkCount ;
let thread_number = 4 ;
let permits = Arc :: new ( Semaphore :: new ( thread_number ) ) ;
for query in query_vec {
let permit_thread = permits . clone ( ) . acquire_owned ( ) . await . unwrap ( ) ;
let query_clone = query . clone ( ) ;
let index_arc_clone = index_arc . clone ( ) ;
let query_type_clone = query_type . clone ( ) ;
let result_type_clone = result_type . clone ( ) ;
let offset_clone = offset ;
let length_clone = length ;
tokio :: spawn ( async move {
let rlo = index_arc_clone
. search (
query_clone ,
query_type_clone ,
offset_clone ,
length_clone ,
result_type_clone ,
false ,
Vec :: new ( ) ,
)
. await ;
println ! ( "result count {}" , rlo.result_count ) ;
drop ( permit_thread ) ;
} ) ;
}JSON、換行分隔 JSON 和連接 JSON 格式的索引 JSON 文件
let file_path= Path :: new ( "wiki_articles.json" ) ;
let _ =index_arc . ingest_json ( file_path ) . await ;索引目錄和子目錄中的所有 PDF 文件
ingest指令自動建立): [
{
"field" : " title " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text " ,
"boost" : 10
},
{
"field" : " body " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text "
},
{
"field" : " url " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Text "
},
{
"field" : " date " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Timestamp " ,
"facet" : true
}
] let file_path= Path :: new ( "C:/Users/johndoe/Downloads" ) ;
let _ =index_arc . ingest_pdf ( file_path ) . await ;索引 PDF 文件
let file_path= Path :: new ( "C:/test.pdf" ) ;
let file_date= Utc :: now ( ) . timestamp ( ) ;
let _ =index_arc . index_pdf_file ( file_path ) . await ;索引 PDF 檔案位元組數
let file_date= Utc :: now ( ) . timestamp ( ) ;
let document = fs :: read ( file_path ) . unwrap ( ) ;
let _ =index_arc . index_pdf_bytes ( file_path , file_date , & document ) . await ;取得PDF文件位元組數
let doc_id= 0 ;
let file=index . get_file ( doc_id ) . unwrap ( ) ;清晰的索引
index . clear_index ( ) ;刪除索引
index . delete_index ( ) ;收盤指數
index . close_index ( ) ;eekstorm庫版本字串
let version= version ( ) ;
println ! ( "version {}" ,version ) ;分面在 3 個不同的地方定義:
分面索引和搜尋的最小工作範例僅需要 60 行程式碼。但僅從文件中將所有內容拼湊起來可能會很乏味。這就是我們在這裡提供快速入門範例的原因:
將所需的 crate 加入您的專案中
cargo add seekstorm
cargo add tokio
cargo add serde_json新增使用聲明
use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;使用非同步 Rust 運行時
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {建立索引
let index_path= Path :: new ( "C:/index/" ) ; //x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let mut index_arc = Arc :: new ( RwLock :: new ( index ) ) ;索引文件
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; 提交文件
index_arc . commit ( ) . await ;搜尋索引
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let query_facets = vec ! [ QueryFacet :: String { field: "age" .to_string ( ) ,prefix: "" .to_string ( ) ,length: u16 :: MAX } ] ;
let facet_filter= Vec :: new ( ) ;
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter , query_facets , facet_filter ) . await ;顯示結果
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_owned ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter2= Some ( highlighter ( & index_arc , highlights , result_object . query_terms ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter2 , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}顯示面
println ! ( "{}" , serde_json::to_string_pretty ( &result_object.facets ) .unwrap ( ) ) ;主函數結束
Ok ( ( ) )
} 快速逐步教程,介紹如何使用 SeekStorm 伺服器透過 5 個簡單步驟從維基百科語料庫建立維基百科搜尋引擎。

下載SeekStorm
從 GitHub 儲存庫下載 SeekStorm
解壓縮到您選擇的目錄中,在 Visual Studio code 中開啟。
或替代地
git clone https://github.com/SeekStorm/SeekStorm.git
建置SeekStorm
安裝 Rust(如果尚未存在):https://www.rust-lang.org/tools/install
在 Visual Studio Code 的終端機中輸入:
cargo build --release
取得維基百科語料庫
預處理的英語維基百科語料庫(5,032,105 個文檔,解壓縮後 8,28 GB)。儘管 wiki-articles.json 具有 .JSON 副檔名,但它不是有效的 JSON 檔案。它是一個文字文件,其中每一行都包含一個帶有 url、title 和 body 屬性的 JSON 物件。該格式稱為 ndjson(“換行符號分隔 JSON”)。
下載維基百科語料庫
解壓縮維基百科語料庫。
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
將解壓縮後的wiki-articles.json移至release目錄
啟動SeekStorm伺服器
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
索引
在正在運行的 SeekStorm 伺服器的命令列中輸入「ingest」:
ingest
這將建立演示索引並索引本地維基百科檔案。
開始在嵌入式 WebUI 中搜尋
在瀏覽器中開啟嵌入式 Web UI:http://127.0.0.1
在搜尋框中輸入查詢
測試 REST API 端點
在 VSC 中開啟 src/seekstorm_server/test_api.rest 以及 VSC 擴充「Rest client」以執行 API 呼叫並檢查回應
互動式 API 端點範例
將 test_api.rest 中的「單獨 API 金鑰」設定為您在上面鍵入「index」時在伺服器控制台中顯示的 api 金鑰。
刪除演示索引
在正在運行的 SeekStorm 伺服器的命令列中輸入“delete”:
delete
關閉伺服器
在正在運行的 SeekStorm 伺服器的命令列中鍵入「quit」。
quit
客製化
您想在自己的專案中使用類似的東西嗎?查看攝取和 Web UI 文件。
有關如何使用 SeekStorm 伺服器從包含 PDF 檔案的目錄建立 PDF 搜尋引擎的快速逐步教學。
使您所有的科學論文、電子書、簡歷、報告、合約、文件、手冊、信件、銀行對帳單、發票、送貨單都可以在家中或您的組織中進行搜尋。
建置SeekStorm
安裝 Rust(如果尚未存在):https://www.rust-lang.org/tools/install
在 Visual Studio Code 的終端機中輸入:
cargo build --release
下載 PDFium
下載 Pdfium 庫並將其複製到與eekstorm_server.exe 相同的資料夾中:https://github.com/bblanchon/pdfium-binaries
啟動SeekStorm伺服器
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
索引
選擇包含您要索引和搜尋的 PDF 檔案的目錄,例如您的文件或下載目錄。
在正在運行的 SeekStorm 伺服器的命令列中輸入「ingest」:
ingest C:UsersJohnDoeDownloads
這將建立 pdf_index 並索引指定目錄(包括子目錄)中的所有 PDF 檔案。
開始在嵌入式 WebUI 中搜尋
在瀏覽器中開啟嵌入式 Web UI:http://127.0.0.1
在搜尋框中輸入查詢
刪除演示索引
在正在運行的 SeekStorm 伺服器的命令列中輸入“delete”:
delete
關閉伺服器
在正在運行的 SeekStorm 伺服器的命令列中鍵入「quit」。
quit
全文搜尋 30M 駭客新聞貼文和連結網頁
DeepHN.org
DeepHN 演示仍然基於 SeekStorm C# 程式碼庫。
我們目前正在移植所有必需的缺失功能。
請參閱下面的路線圖。
Rust 連接埠尚未完成功能。目前已移植以下功能。
移植
改進
新功能


