lieu
vements
替代搜尋引擎
其創建是為了回應人們對超文本搜尋和發現的使用漠不關心的環境。在《Lieu》中,網路並不是可搜尋的,而是一個人自己的社群。換句話說,Lieu 是一個社區搜尋引擎,是個人網路圈增加偶然聯繫的一種方式。
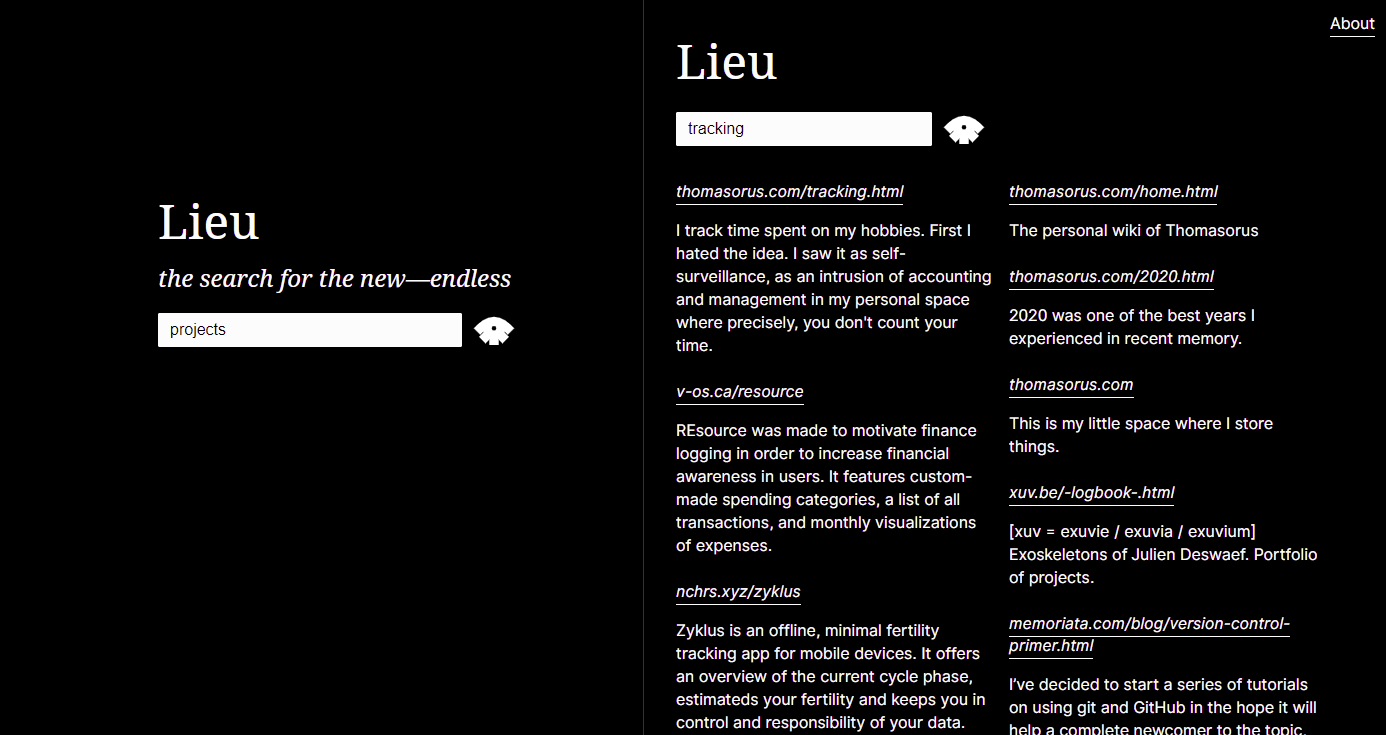
有關完整的搜尋語法(包括如何使用site:和-site: ),請參閱搜尋語法和 API 文件。如需更多提示,請閱讀附錄。
$ lieu help
Lieu: neighbourhood search engine
Commands
- precrawl (scrapes config's general.url for a list of links: <li> elements containing an anchor <a> tag)
- crawl (start crawler, crawls all urls in config's crawler.webring file)
- ingest (ingest crawled data, generates database)
- search (interactive cli for searching the database)
- host (hosts search engine over http)
Example:
lieu precrawl > data/webring.txt
lieu crawl > data/crawled.txt
lieu ingest
lieu host
Lieu 的爬行和預爬行命令輸出到標準輸出,以便於檢查資料。您通常希望將它們的輸出重定向到 Lieu 從中讀取的文件,如設定檔中所定義。請參閱下面的典型工作流程。
config.crawler.webring中新增要抓取的網域url欄位設定為該頁面precrawl進行抓取的網域清單: lieu precrawl > data/webring.txtlieu crawl > data/crawled.txtlieu ingestlieu host使用lieu ingest攝取資料後,您也可以使用lieu在終端機中透過lieu search來搜尋語料庫。
調整配置的theme值,如下圖所示。
設定檔是用 TOML 編寫的。
[ general ]
name = " Merveilles Webring "
# used by the precrawl command and linked to in /about route
url = " https://webring.xxiivv.com "
# used by the precrawl command to populate the Crawler.Webring file;
# takes simple html selectors. might be a bit wonky :)
webringSelector = " li > a[href]:first-of-type "
port = 10001
[ theme ]
# colors specified in hex (or valid css names) which determine the theme of the lieu instance
# NOTE: If (and only if) all three values are set lieu uses those to generate the file html/assets/theme.css at startup.
# You can also write directly to that file istead of adding this section to your configuration file
foreground = " #ffffff "
background = " #000000 "
links = " #ffffff "
[ data ]
# the source file should contain the crawl command's output
source = " data/crawled.txt "
# location & name of the sqlite database
database = " data/searchengine.db "
# contains words and phrases disqualifying scraped paragraphs from being presented in search results
heuristics = " data/heuristics.txt "
# aka stopwords, in the search engine biz: https://en.wikipedia.org/wiki/Stop_word
wordlist = " data/wordlist.txt "
[ crawler ]
# manually curated list of domains, or the output of the precrawl command
webring = " data/webring.txt "
# domains that are banned from being crawled but might originally be part of the webring
bannedDomains = " data/banned-domains.txt "
# file suffixes that are banned from being crawled
bannedSuffixes = " data/banned-suffixes.txt "
# phrases and words which won't be scraped (e.g. if a contained in a link)
boringWords = " data/boring-words.txt "
# domains that won't be output as outgoing links
boringDomains = " data/boring-domains.txt "
# queries to search for finding preview text
previewQueryList = " data/preview-query-list.txt "為了您自己的使用,應自訂以下配置欄位:
nameurlportsourcewebringbannedDomains除非您有特定要求,否則以下配置定義的檔案可以保持原樣:
databaseheuristicswordlistbannedSuffixespreviewQueryList有關文件及其各種作業的完整概要,請參閱文件描述。
建立一個二進位檔案:
# this project has an experimental fulltext-search feature, so we need to include sqlite's fts engine (fts5)
go build --tags fts5
# or using go run
go run --tags fts5 . 建立新的發布二進位檔案:
./release.sh原始碼AGPL-3.0-or-later ,Inter 可根據SIL OPEN FONT LICENSE Version 1.1取得,Noto Serif 取得Apache License, Version 2.0 。


