pianola
1.0.0
 鋼琴演奏中" style="max-width: 100%;">
鋼琴演奏中" style="max-width: 100%;">
pianola是一款播放人工智慧生成的鋼琴音樂的應用程式。使用者透過在鍵盤上彈奏音符或從經典作品中選擇範例片段來播種(即「提示」)AI 模型。
在本自述文件中,我們解釋了人工智慧的工作原理並詳細介紹了模型的架構。
音樂可以用多種方式表示,從原始音訊波形到半結構化 MIDI 標準。在pianola中,我們將音樂節拍分解為規則的、均勻的音程(例如十六分音符/十六分音符)。在一個音程內演奏的音符被認為屬於同一個時間步,一系列時間步形成一個序列。使用基於網格的序列作為輸入,AI 模型預測下一個時間步中的音符,進而將其用作以自回歸方式預測後續時間步的輸入。
除了要演奏的音符之外,模型還預測每個音符的持續時間(按下音符的時間長度)和力度(敲擊琴鍵的力度)。
模型由三個模組組成:嵌入器、變壓器和解碼器。這些模組借鑒了 Inception 網路、LLaMA Transformer 和多標籤分類器鍊等著名架構,但適合處理音樂資料並以新穎的方法進行組合。
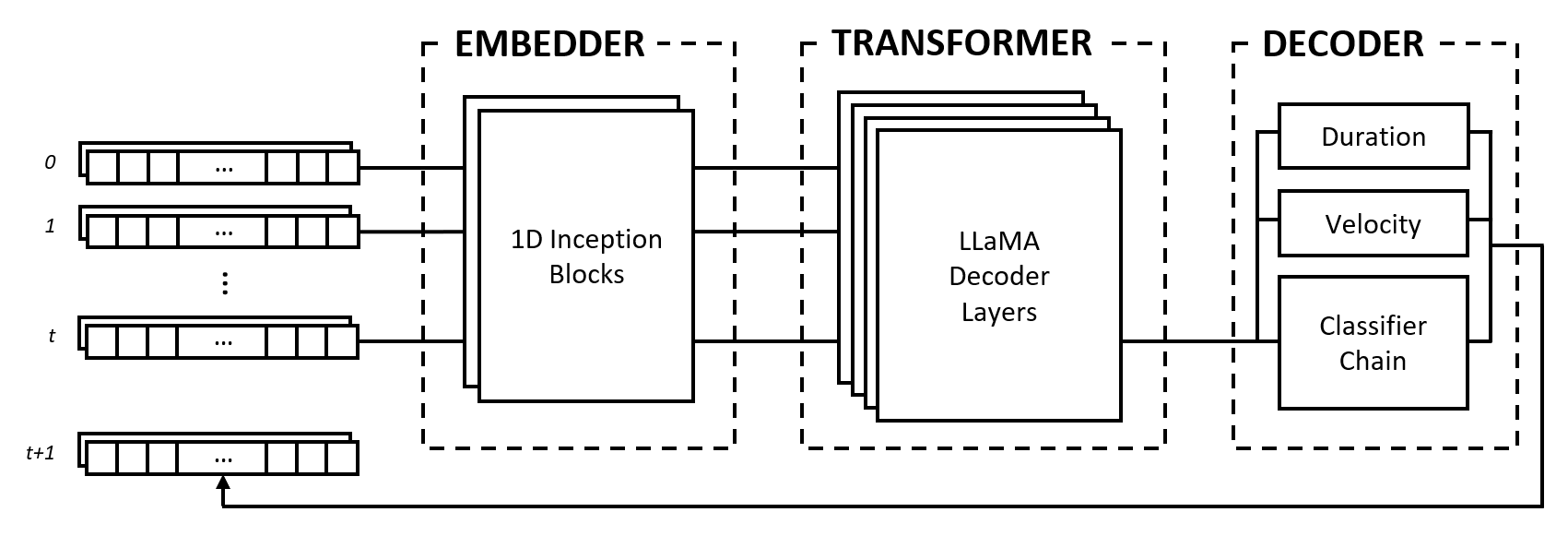
嵌入器將形狀(num_notes, num_features)的每個輸入時間步轉換為可以饋送到變壓器中的嵌入向量。然而,與將單熱向量映射到另一個維度空間的文字嵌入不同,我們透過在輸入上應用卷積層和池化層來提供歸納偏差。我們這樣做有很多原因:
2^num_notes ,其中num_notes對於普通鋼琴來說是 64 或 88 ),因此不可能將它們表示為 one-hot 向量。為了讓嵌入器了解哪些距離有用,我們從 Inception 網路和不同核心大小的堆疊卷積中獲得靈感。
Transformer 模組由 LLaMA Transformer 層組成,這些層將自註意力機制應用於輸入嵌入向量序列。
與許多生成式 AI 模型一樣,該模組僅使用 Vaswani 等人的原始 Transformers 模型的「解碼器」部分。 (2017)。我們在這裡使用標籤「transformer」來區分該模組與以下模組,後者對自註意力層產生的狀態進行實際解碼。
我們選擇 LLaMA 架構而不是其他類型的 Transformer,主要是因為它使用旋轉位置嵌入 (RoPE),該嵌入對隨著時間步長的距離衰減的相對位置進行編碼。鑑於我們將音樂數據表示為固定間隔,時間步之間的相對位置和距離是重要的訊息,變壓器可以明確地使用這些資訊來理解和產生具有一致節奏的音樂。
解碼器接收參與狀態並預測要一起演奏的音符及其持續時間和速度。該模組由幾個子組件組成,即用於音符預測的分類器鍊和用於特徵預測的多層感知器(MLP)。
分類器鏈由num_notes個二元分類器組成,即鋼琴上的每個琴鍵一個分類器,以建立多標籤分類器。為了利用音符之間的相關性,二元分類器被連結在一起,以便先前音符的結果影響後續音符的預測。例如,如果八度音符之間存在正相關性,則活躍的較低音符(例如C3 )導致較高音符(例如C4 )被預測的較高機率。這在負相關的情況下也是有益的,在這種情況下,人們可以在兩個相鄰音符之間進行選擇,從而產生大調或小調音階(例如CDE與CD-Eb ),但不能同時選擇兩者。
為了計算效率,我們將鏈的長度限制為 12 個鏈接,即 1 個八度。最後,使用取樣解碼策略來選擇與其預測機率相關的音符。
持續時間和速度特徵被視為迴歸問題,並使用普通 MLP 進行預測。雖然預測每個音符的特徵,但我們在訓練期間使用自訂損失函數,該函數僅聚合活動音符的特徵損失,類似於具有本地化任務的圖像分類中使用的損失函數。
我們選擇將音樂資料表示為網格有其優點和缺點。我們透過將其與 Oore 等人提出的基於事件的詞彙進行比較來討論這些觀點。 (2018),音樂生成領域被高度引用的貢獻。
我們的方法的主要優點之一是對音樂的微觀和宏觀理解的解耦,這導致嵌入器和變壓器之間的職責明確分離。前者的作用是在微觀層面上解釋音符的相互作用,例如音符之間的相對距離如何形成和弦等音樂關係,而後者的任務是在時間維度上綜合這些信息,以從宏觀上理解音樂風格等級。
相較之下,基於事件的表示將全部負擔放在序列模型上來解釋單熱標記,這些標記可以表示音調、時間或速度這三個不同的概念。黃等人。 (2018)發現有必要在他們的 Transformer 模型中添加相對注意機制才能產生連貫的延續,這表明該模型需要歸納偏差才能在這種表示上表現良好。
在網格表示中,間隔長度的選擇是資料保真度和稀疏性之間的權衡。較長的間隔會降低音符計時的粒度,降低音樂表現力,並可能壓縮顫音和重複音符等快速元素。另一方面,較短的間隔會引入大量空時間步,從而指數級增加稀疏性,這對於 Transformer 模型來說是一個重要問題,因為它們受到序列長度的限制。
此外,音樂資料可以透過時間的流逝( 1 timestep == X milliseconds )或按照樂譜寫入( 1 timestep == 1 sixteenth note/semiquaver )映射到網格,每個資料都有自己的權衡。基於事件的表示透過將時間的流逝指定為事件來完全避免這些問題。
儘管有缺點,網格表示法具有實際的優勢,因為它在pianola的開發中更容易使用。模型輸出是人類可讀的,時間步數對應於固定的時間量,使得新功能的發展速度更快。
此外,對擴展 Transformer 模型序列長度的研究以及對硬體的持續改進將逐步減少資料稀疏引起的問題,截至 2023 年末,我們將看到可以處理數萬個標記的大型語言模型。隨著技術的優化和強大的硬體變得更容易使用,我們相信保真度將繼續提高,就像圖像生成一樣,從而使人工智慧生成的音樂具有更大的表現力和細微差別。
為了學術研究和知識共享的目的,該計畫的原始碼是公開可見的。除非明確授予許可,否則所有權利均由創建者保留。
網站圖示修改自 Freepik - Flaticon。
透過 Outlook.com 聯繫,地址為bruce <dot> ckc 。


