KoMiniLM
1.0.0
目前的語言模型通常由數億個參數組成,由於延遲和容量限制,這給實際應用中的微調和線上服務帶來了挑戰。在這個專案中,我們發布了一個輕量級的韓語語言模型,以解決現有語言模型的上述缺點。
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "BM-K/ KoMiniLM " ) # 23M model
model = AutoModel . from_pretrained ( "BM-K/ KoMiniLM " )
inputs = tokenizer ( "안녕 세상아!" , return_tensors = "pt" )
outputs = model ( ** inputs )** 2022年6月20日更新 **
** 2022年5月24日更新 **
Teacher Model :KLUE-BERT(base)
自註意力分佈和自註意力值關係 [Wang et al., 2020] 從教師模型的每個離散層提煉到學生模型。王等人。在變壓器的最後一層進行蒸餾,但本專案的情況並非如此。
| 數據 | 新聞評論 | 新聞文章 |
|---|---|---|
| 尺寸 | 10G | 10G |
筆記
- 透過在訓練中添加 wiki 資料可以進一步提高效能。
- 新聞文章的抓取和預處理程式碼在這裡。
{
"architectures" : [
" BertForPreTraining "
],
"attention_probs_dropout_prob" : 0.1 ,
"classifier_dropout" : null ,
"hidden_act" : " gelu " ,
"hidden_dropout_prob" : 0.1 ,
"hidden_size" : 384 ,
"initializer_range" : 0.02 ,
"intermediate_size" : 1536 ,
"layer_norm_eps" : 1e-12 ,
"max_position_embeddings" : 512 ,
"model_type" : " bert " ,
"num_attention_heads" : 12 ,
"num_hidden_layers" : 6 ,
"output_attentions" : true ,
"pad_token_id" : 0 ,
"position_embedding_type" : " absolute " ,
"return_dict" : false ,
"torch_dtype" : " float32 " ,
"transformers_version" : " 4.13.0 " ,
"type_vocab_size" : 2 ,
"use_cache" : true ,
"vocab_size" : 32000
}{
"architectures" : [
" BertForPreTraining "
],
"attention_probs_dropout_prob" : 0.1 ,
"classifier_dropout" : null ,
"hidden_act" : " gelu " ,
"hidden_dropout_prob" : 0.1 ,
"hidden_size" : 768 ,
"initializer_range" : 0.02 ,
"intermediate_size" : 3072 ,
"layer_norm_eps" : 1e-12 ,
"max_position_embeddings" : 512 ,
"model_type" : " bert " ,
"num_attention_heads" : 12 ,
"num_hidden_layers" : 6 ,
"output_attentions" : true ,
"pad_token_id" : 0 ,
"position_embedding_type" : " absolute " ,
"return_dict" : false ,
"torch_dtype" : " float32 " ,
"transformers_version" : " 4.13.0 " ,
"type_vocab_size" : 2 ,
"use_cache" : true ,
"vocab_size" : 32000
}
cd KoMiniLM -Finetune
bash scripts/run_all_ KoMiniLM .sh
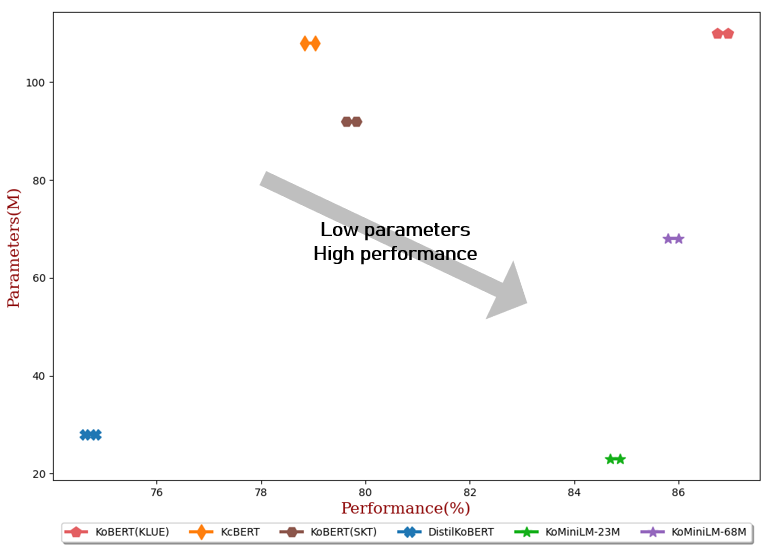
| #參數 | 平均的 | 國家醫學中心 (附註) | Naver NER (F1) | 爪子 (附註) | 韓國國家圖書館 (附註) | 科爾STS (斯皮爾曼) | 問題對 (附註) | 科爾誇德 (開發) (EM/F1) | |
|---|---|---|---|---|---|---|---|---|---|
| 科伯特(KLUE) | 110M | 86.84 | 90.20±0.07 | 87.11±0.05 | 81.36±0.21 | 81.06±0.33 | 82.47±0.14 | 95.03±0.44 | 84.43±0.18/ 93.05±0.04 |
| KcBERT | 108M | 78.94 | 89.60±0.10 | 84.34±0.13 | 67.02±0.42 | 74.17±0.52 | 76.57±0.51 | 93.97±0.27 | 60.87±0.27/ 85.01±0.14 |
| 科伯特(SKT) | 92M | 79.73 | 89.28±0.42 | 87.54±0.04 | 80.93±0.91 | 78.18±0.45 | 75.98±2.81 | 94.37±0.31 | 51.94±0.60/ 79.69±0.66 |
| 蒸餾科伯特 | 28M | 74.73 | 88.39±0.08 | 84.22±0.01 | 61.74±0.45 | 70.22±0.14 | 72.11±0.27 | 92.65±0.16 | 52.52±0.48/ 76.00±0.71 |
| KoMiniLM † | 68M | 85.90 | 89.84±0.02 | 85.98±0.09 | 80.78±0.30 | 79.28±0.17 | 81.00±0.07 | 94.89±0.37 | 83.27±0.08/ 92.08±0.06 |
| KoMiniLM † | 23M | 84.79 | 89.67±0.03 | 84.79±0.09 | 78.67±0.45 | 78.10±0.07 | 78.90±0.11 | 94.81±0.12 | 82.11±0.42/ 91.21±0.29 |
本作品根據 Creative Commons Attribution-ShareAlike 4.0 International License 授權。


