nnl
gpt2-xl assets
nnl是低記憶體 GPU 平台上大型模型的推理引擎。
大模型太大,無法裝入 GPU 記憶體。 nnl透過 PCIE 頻寬和記憶體之間的權衡解決了這個問題。
典型的推理流程如下:
透過 GPU 記憶體池和記憶體碎片整理,NNIL 使得在低階 GPU 平台上推理大型模型成為可能。
這只是幾週內寫的一個業餘愛好項目,目前僅支援 CUDA 後端。
make lib nnl _cuda.a && make lib nnl _cuda_kernels.a此指令將建置兩個靜態函式庫: lib/lib nnl _cuda.a和lib/lib nnl _cuda_kernels.a 。第一個是 C++ 的 CUDA 後端核心函式庫,第二個是 CUDA 核心。
這裡提供了GPT2-XL (1.6B)的示範程式。該程式可以透過以下命令編譯:
make gpt2_1558m從版本下載所有權重後,我們可以在低階 GPU 平台(例如 GTX 1050(2 GB 記憶體))上執行以下命令:
./bin/gpt2_1558m --max_len 20 " Hi. My name is Feng and I am a machine learning engineer "輸出是這樣的: 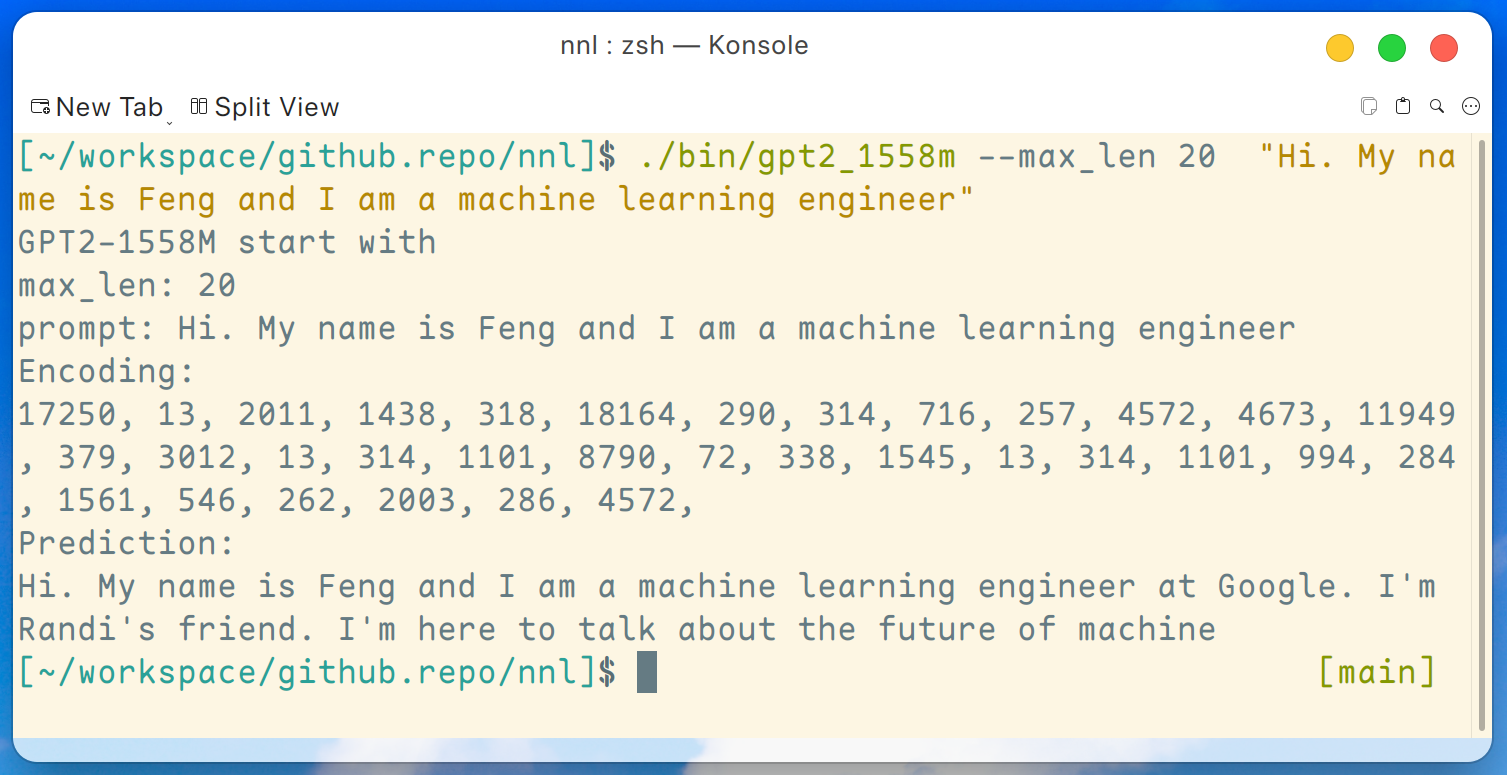
免責聲明:這只是 gpt2-xl 生成的範例,我不在 Google 工作,我不認識 Randi。
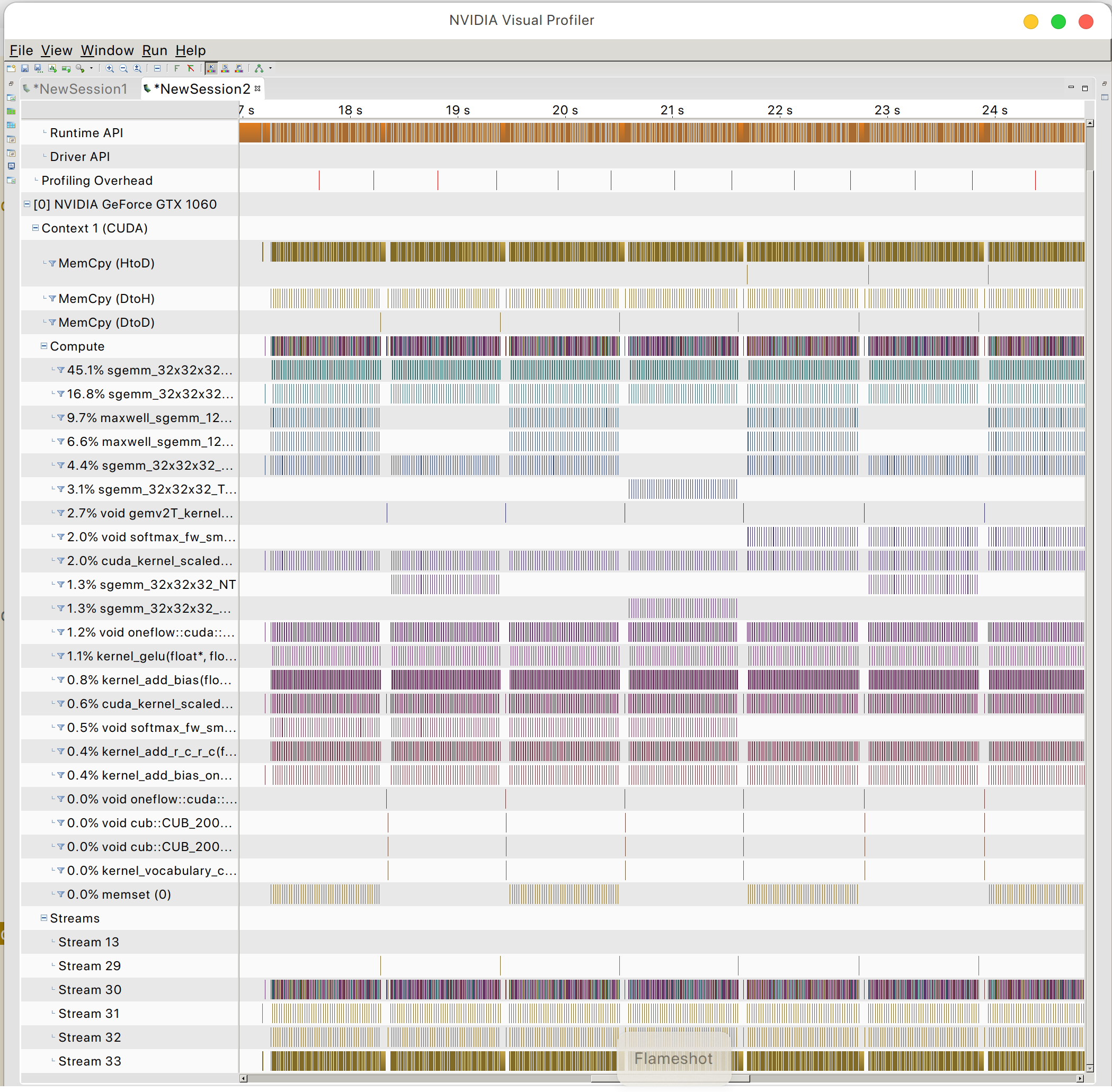
你可以找到GPU記憶體存取模式
和平OSL