UniIR
1.0.0
首頁| ?資料集(M-BEIR Benchmark) | ?檢查點( UniIR型號) | arXiv | GitHub
該儲存庫包含 ECCV-2024 論文「 UniIR :通用多模態資訊檢索器的訓練和基準測試」的程式碼庫
我們提出了UniIR (通用多模態資訊檢索)框架來學習單一檢索器來完成(可能)任何檢索任務。與傳統的 IR 系統不同, UniIR需要按照說明進行異質查詢,以從具有數百萬個不同模式的候選者的異質候選池中進行檢索。
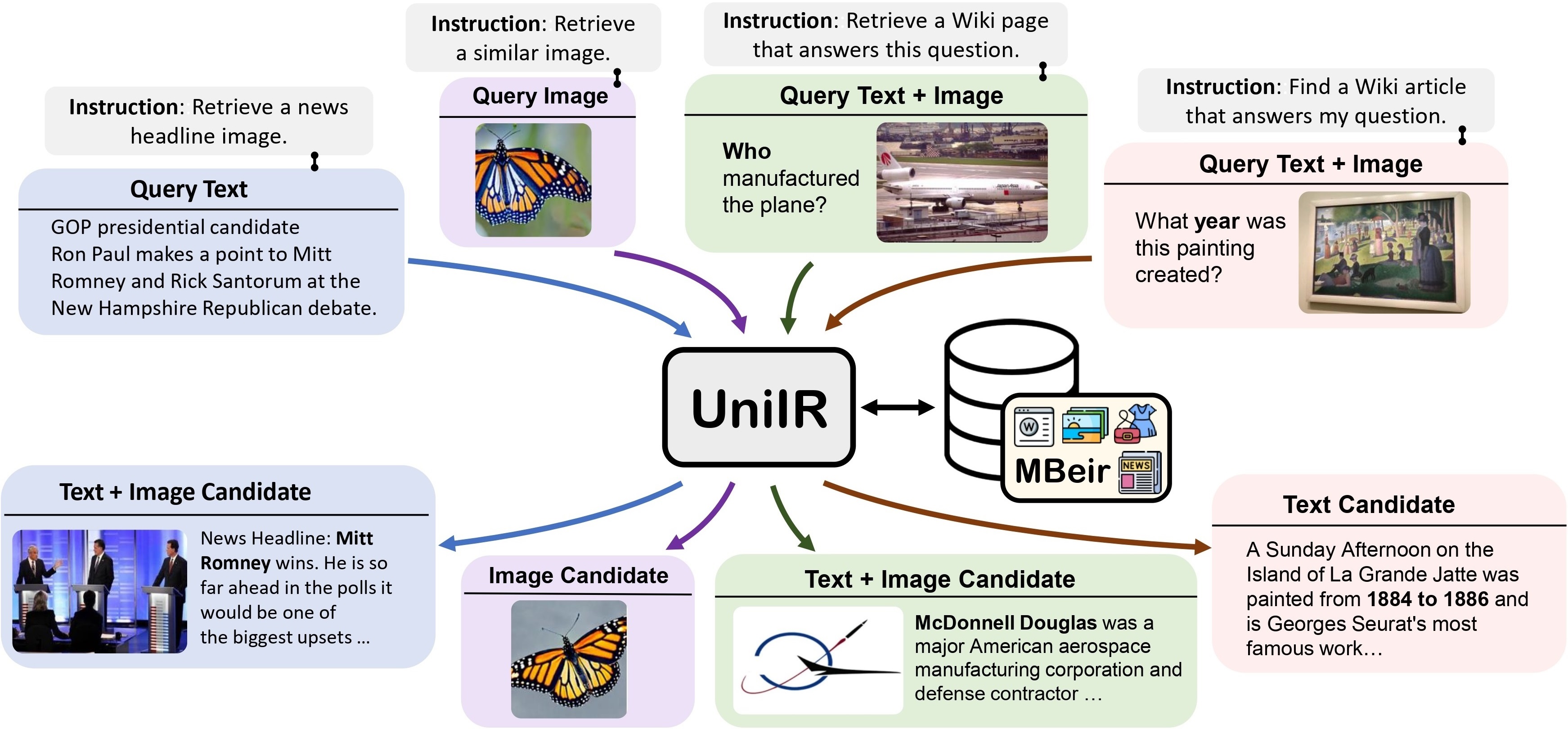 UniIR Teaser" style="width: 80%;最大寬度:100%;">
UniIR Teaser" style="width: 80%;最大寬度:100%;">
為了訓練和評估通用多模態檢索模型,我們建立了一個名為M-BEIR (指導檢索的多模態基準)的大規模檢索基準。
我們在?中提供 M-BEIR 資料集。數據集。請按照 HF 頁面上提供的說明下載資料集並準備用於訓練和評估的資料。您需要設定 GiT LFS 並直接複製儲存庫:
git clone https://huggingface.co/datasets/TIGER-Lab/M-BEIR
我們提供用於訓練和評估UniIR CLIP-ScoreFusion、CLIP-FeatureFusion、BLIP-ScoreFusion 和 BLIP-FeatureFusion 模型的程式碼庫。
使用以下命令準備UniIR專案和 Conda 環境的程式碼庫:
git clone https://github.com/TIGER-AI-Lab/UniIR
cd UniIR
cd src/models/
conda env create -f UniIR _env.yml若要從預先訓練的 CLIP 和 BLIP 檢查點訓練UniIR模型,請按照以下說明進行操作。腳本將自動下載預先訓練的 CLIP 和 BLIP 檢查點。
請依照M-BEIR部分的說明下載 M-BEIR 基準測試。
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/train/inbatch/修改inbatch.yaml以進行超參數調整,並run_inbatch.sh以適應您自己的環境和路徑。
run_inbatch.sh中的UniIR _DIR修改為要儲存檢查點的目錄。run_inbatch.sh中的MBEIR_DATA_DIR修改為M-BEIR基準測試的儲存目錄。run_inbatch.sh中的SRC_DIR修改為儲存UniIR專案程式碼庫的目錄(此儲存庫)。WANDB_API_KEY 、 WANDB_PROJECT和WANDB_ENTITY的.env環境。然後您可以執行以下命令來訓練UniIR CLIP_SF Large 模型。
bash run_inbatch.sh cd src/models/ UniIR _blip/blip_featurefusion/configs_scripts/large/train/inbatch/修改inbatch.yaml以進行超參數調整,並run_inbatch.sh以適應您自己的環境和路徑。
bash run_inbatch.sh我們在 M-BEIR 基準上提供UniIR模型的評估流程。
請為 FAISS 庫建立一個環境:
# From the root directory of the project
cd src/common/
conda env create -f faiss_env.yml請依照M-BEIR部分的說明下載 M-BEIR 基準測試。
您可以按照模型動物園部分中的說明從頭開始訓練UniIR模型或下載預先訓練的UniIR檢查點。
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/eval/inbatch/根據您自己的環境、路徑和評估設定修改embed.yaml 、 index.yaml 、 retrieval.yaml和run_eval_pipeline_inbatch.sh 。
run_eval_pipeline_inbatch.sh中的UniIR _DIR修改為您要儲存大型檔案(包括檢查點、嵌入、索引和檢索結果)的目錄。然後您可以將clip_sf_large.pth檔案放置在以下路徑中: $ UniIR _DIR /checkpoint/CLIP_SF/Large/Instruct/InBatch/clip_sf_large.pthembed.yaml檔案中model.ckpt_config指定的預設路徑。run_eval_pipeline_inbatch.sh中的MBEIR_DATA_DIR修改為M-BEIR基準測試的儲存目錄。run_eval_pipeline_inbatch.sh中的SRC_DIR修改為儲存UniIR專案程式碼庫的目錄(此儲存庫)。預設配置將在 M-BEIR(5.6M 異質候選池)和 M-BEIR_local(同質候選池)基準上評估UniIR CLIP_SF Large 模型。 yaml檔案中的UNION指的是M-BEIR(5.6M異構候選池)。您可以按照yaml檔案中的註解並修改配置以僅在M-BEIR_local基準測試上評估模型。
bash run_eval_pipeline_inbatch.sh embed 、 index 、 logger和retrieval_results將保存在$ UniIR _DIR目錄中。
cd src/models/unii_blip/blip_featurefusion/configs_scripts/large/eval/inbatch/同樣,如果您下載我們預先訓練的UniIR模型,則可以將blip_ff_large.pth檔案放置在以下路徑中:
$ UniIR _DIR /checkpoint/BLIP_FF/Large/Instruct/InBatch/blip_ff_large.pth預設配置將在 M-BEIR 和 M-BEIR_local 基準測試上評估UniIR BLIP_FF Large 模型。
bash run_eval_pipeline_inbatch.shUniRAG 評估與預設評估非常相似,但存在以下差異:
retrieval_results下。當檢索到的結果將用於 RAG 等下游應用時,這非常有用。retrieval.yaml中的retrieve_image_text_pairs設定為True時,將為每個僅text或僅image模式的候選者取得補集候選者。透過這種設置,候選詞及其補語將始終具有image, text形態。透過使用原始候選作為查詢來獲取補充候選(例如,查詢文字->候選圖像->補充候選文字)。InBatch和inbatch替換為UniRAG和unirag 。 我們在?中提供UniIR模型檢查點檢查站。您可以直接使用檢查點進行檢索任務,也可以針對自己的檢索任務微調模型。
| 型號名稱 | 版本 | 型號尺寸 | 型號連結 |
|---|---|---|---|
| UniIR (CLIP-SF) | 大的 | 5.13GB | 下載連結 |
| UniIR (BLIP-FF) | 大的 | 7.49 GB | 下載連結 |
您可以透過以下方式下載它們
git clone https://huggingface.co/TIGER-Lab/UniIR
參考書目:
@article { wei2023 UniIR ,
title = { UniIR : Training and benchmarking universal multimodal information retrievers } ,
author = { Wei, Cong and Chen, Yang and Chen, Haonan and Hu, Hexiang and Zhang, Ge and Fu, Jie and Ritter, Alan and Chen, Wenhu } ,
journal = { arXiv preprint arXiv:2311.17136 } ,
year = { 2023 }
}

