DiSQ Score
1.0.0
我們論文的正式實施:話語蘇格拉底式提問:評估語言模型對話語關係理解的忠實性 (2024) Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, Min-Yen Kan. ACL 2024。
論文PDF:https://yisong.me/publications/acl24-DiSQ-CR.pdf
投影片:https://yisong.me/publications/acl24-DiSQ-Slides.pdf
海報:https://yisong.me/publications/acl24-DiSQ-Poster.pdf
git clone [email protected]:YisongMiao/DiSQ-Score.git
conda activate
cd DiSQ-Score
cd scripts
pip install -r requirements.txt
您想知道任何語言模型的DiSQ Score嗎?歡迎您使用這一行命令!

我們提供了一個簡化的命令來評估 HuggingFace 模型中心中託管的任何語言模型 (LM)。建議您將其用於任何新模型(尤其是我們論文中未研究的模型)。
bash scripts/one_model.sh <modelurl>
< modelurl > 變數指定 Huggingface Hub 中的縮短路徑,例如,
bash scripts/one_model.sh meta-llama/Meta-Llama-3-8B
在執行 bash 檔案之前,請編輯 bash 檔案以指定本機 HuggingFace 快取的路徑。
例如,在scripts/one_model.sh中:
#!/bin/bash
# Please define your own path here
huggingface_path=YOUR_PATH
您可以將YOUR_PATH變更為 Huggingface 快取的絕對目錄位置(例如/disk1/yisong/hf-cache )。
我們建議至少 200GB 可用空間。
輸出文字檔案將保存在data/results/verbalizations/Meta-Llama-3-8B.txt ,其中包含:
=== The results for model: Meta-Llama-3-8B ===
Dataset: pdtb
DiSQ Score : 0.206
Targeted Score: 0.345
Counterfactual Score: 0.722
Consistency: 0.827
DiSQ Score for Comparison.Concession: 0.188
DiSQ Score for Comparison.Contrast: 0.22
DiSQ Score for Contingency.Reason: 0.164
DiSQ Score for Contingency.Result: 0.177
DiSQ Score for Expansion.Conjunction: 0.261
DiSQ Score for Expansion.Equivalence: 0.221
DiSQ Score for Expansion.Instantiation: 0.191
DiSQ Score for Expansion.Level-of-detail: 0.195
DiSQ Score for Expansion.Substitution: 0.151
DiSQ Score for Temporal.Asynchronous: 0.312
DiSQ Score for Temporal.Synchronous: 0.084
=== End of the results for model: Meta-Llama-3-8B ===
=== The results for model: Meta-Llama-3-8B ===
Dataset: ted
DiSQ Score : 0.233
Targeted Score: 0.605
Counterfactual Score: 0.489
Consistency: 0.787
DiSQ Score for Comparison.Concession: 0.237
DiSQ Score for Comparison.Contrast: 0.268
DiSQ Score for Contingency.Reason: 0.136
DiSQ Score for Contingency.Result: 0.211
DiSQ Score for Expansion.Conjunction: 0.268
DiSQ Score for Expansion.Equivalence: 0.205
DiSQ Score for Expansion.Instantiation: 0.194
DiSQ Score for Expansion.Level-of-detail: 0.222
DiSQ Score for Expansion.Substitution: 0.176
DiSQ Score for Temporal.Asynchronous: 0.156
DiSQ Score for Temporal.Synchronous: 0.164
=== End of the results for model: Meta-Llama-3-8B ===
我們將資料集儲存在位於data/datasets/dataset_pdtb.json和data/datasets/dataset_ted.json的 JSON 檔案中。例如,讓我們從 PDTB 資料集中取得一個實例:
"2": {
"Didx": 2,
"arg1": "and special consultants are springing up to exploit the new tool",
"arg2": "Blair Entertainment, has just formed a subsidiary -- 900 Blair -- to apply the technology to television",
"DR": "Expansion.Instantiation.Arg2-as-instance",
"Conn": "for instance",
"events": [
[
"special consultants springing",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
],
[
"special consultants exploit the new tool",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
]
],
"context": "Other long-distance carriers have also begun marketing enhanced 900 service, and special consultants are springing up to exploit the new tool. Blair Entertainment, a New York firm that advises TV stations and sells ads for them, has just formed a subsidiary -- 900 Blair -- to apply the technology to television. "
},
以下是該字典條目中的欄位:
Didx :會話 ID。arg1和arg2 :兩個參數。DR :話語關係。Conn :話語連結詞。events :對的列表,儲存預測為顯著訊號的事件對。context :話語上下文。 cd DiSQ-Score
bash scripts/question_generation.sh
這個bash檔案將會呼叫question_generation.py來產生不同配置下的問題。
question_generation.py的參數如下:
--dataset :指定資料集,可以是pdtb或ted 。--modelname :模型的別名已建立。 13b指 LLaMA2-13B, 13bchat指 LLaMA2-13B-Chat, vicuna-13b指 Vicuna-13B。這些模型的具體 URL 可以在disq_config.py中找到。--version :指定要使用的提示範本版本,選項為v1 、 v2 、 v3和v4 。--paraphrase :用其釋義版本取代標準問題,並帶有選項p1和p2 。與呼叫qa_utils.py的標準函數不同,釋義函數分別呼叫qa_utils_p1.py和qa_utils_p2.py 。--feature :指定討論問題使用哪些語言功能。語言特徵包括conn (話語連接詞)和context (話語上下文)。歷史 QA 資料需要單獨的腳本。例如,輸出將儲存在配置dataset==pdtb和version==v1下的data/questions/dataset_pdtb_prompt_v1.json中。
我們要求使用者自己產生問題,因為這種方法是自動的,有助於節省 GitHub 儲存庫的空間(最多可達約 200 MB)。如果您無法運行 bash 文件,請聯絡我們以取得問題文件。
cd DiSQ-Score
bash scripts/question_answering.sh
此 bash 檔案將呼叫question_answering.py對任何給定模型執行話語蘇格拉底提問 (DiSQ)。 question_answering.py取得question_generation.py中的所有參數,以及以下新參數:
--modelurl :指定目前不在設定檔中的任何新模型的 URL。例如,「meta-llama/Meta-Llama-3-8B」指定 LLaMA3-8B 模型並將覆寫modelname參數。--hf-path :指定儲存大模型參數的路徑。建議至少有 200 GB 的可用磁碟空間。--device_number :指定要使用的 GPU 的 ID。輸出將儲存在例如data/results/13bchat_dataset_pdtb_prompt_v1/處。每個問題的預測是一個標記及其機率的列表,儲存在資料夾內的 pickle 檔案中。
警告:嚮導模型已被開發人員刪除。我們建議用戶不要嘗試這些型號。檢查討論主題:https://huggingface.co/posts/WizardLM/329547800484476。
cd DiSQ-Score
bash scripts/eval.sh
該 bash 檔案將調用eval.py來評估先前獲得的模型預測。
eval.py採用與question_answering.py相同的參數集。
如果指定的資料集是 PDTB,則評估結果將儲存在disq_score_pdtb.csv中。
CSV 檔案中有 20 列,分別是:
taskcode :指示正在測試的配置,例如dataset_pdtb_prompt_v1_13bchat 。modelname :指定正在測試的語言模型。version :指示提示的版本。paraphrase :釋義參數。feature :指定已使用哪個功能。Overall :總體DiSQ Score 。Targeted :目標分數, DiSQ Score的三個組成部分之一。Counterfactual :反事實分數, DiSQ Score的三個組成部分之一。Consistency :一致性得分, DiSQ Score的三個組成部分之一。Comparison.Concession :此特定話語關係的DiSQ Score 。請注意,我們選擇版本 v1 到 v4 中的最佳結果,以邊緣化提示範本的影響。
為此, eval.py自動提取最佳結果:
| 任務程式碼 | 型號名稱 | 版本 | 釋義 | 特徵 | 全面的 | 針對性 | 反事實 | 一致性 | 比較.讓步 | 比較.對比 | 偶然性.原因 | 意外事件.結果 | 擴充.連接 | 展開式等價 | 擴展.實例化 | 擴展.詳細程度 | 擴展.替代 | 時間異步 | 時間同步 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dataset_pdtb_prompt_v4_7b | 7b | v4 | 0.074 | 0.956 | 0.084 | 0.929 | 0.03 | 0.083 | 0.095 | 0.095 | 0.077 | 0.054 | 0.086 | 0.068 | 0.155 | 0.036 | 0.047 | ||
| dataset_pdtb_prompt_v1_7bchat | 7b聊天 | v1 | 0.174 | 0.794 | 0.271 | 0.811 | 0.231 | 0.435 | 0.132 | 0.173 | 0.214 | 0.105 | 0.121 | 0.15 | 0.199 | 0.107 | 0.04 | ||
| dataset_pdtb_prompt_v2_13b | 13b | v2 | 0.097 | 0.945 | 0.112 | 0.912 | 0.037 | 0.099 | 0.081 | 0.094 | 0.126 | 0.101 | 0.113 | 0.107 | 0.077 | 0.083 | 0.093 | ||
| dataset_pdtb_prompt_v1_13bchat | 13b聊天 | v1 | 0.253 | 0.592 | 0.545 | 0.785 | 0.195 | 0.485 | 0.129 | 0.173 | 0.289 | 0.155 | 0.326 | 0.373 | 0.285 | 0.194 | 0.028 | ||
| dataset_pdtb_prompt_v2_vicuna-13b | vicuna-13b | v2 | 0.325 | 0.512 | 0.766 | 0.829 | 0.087 | 0.515 | 0.201 | 0.352 | 0.369 | 0.0 | 0.334 | 0.46 | 0.199 | 0.511 | 0.074 |
例如,此表顯示了可用開源模型的 PDTB 資料集的最佳結果,它再現了我們論文中的雷達圖:
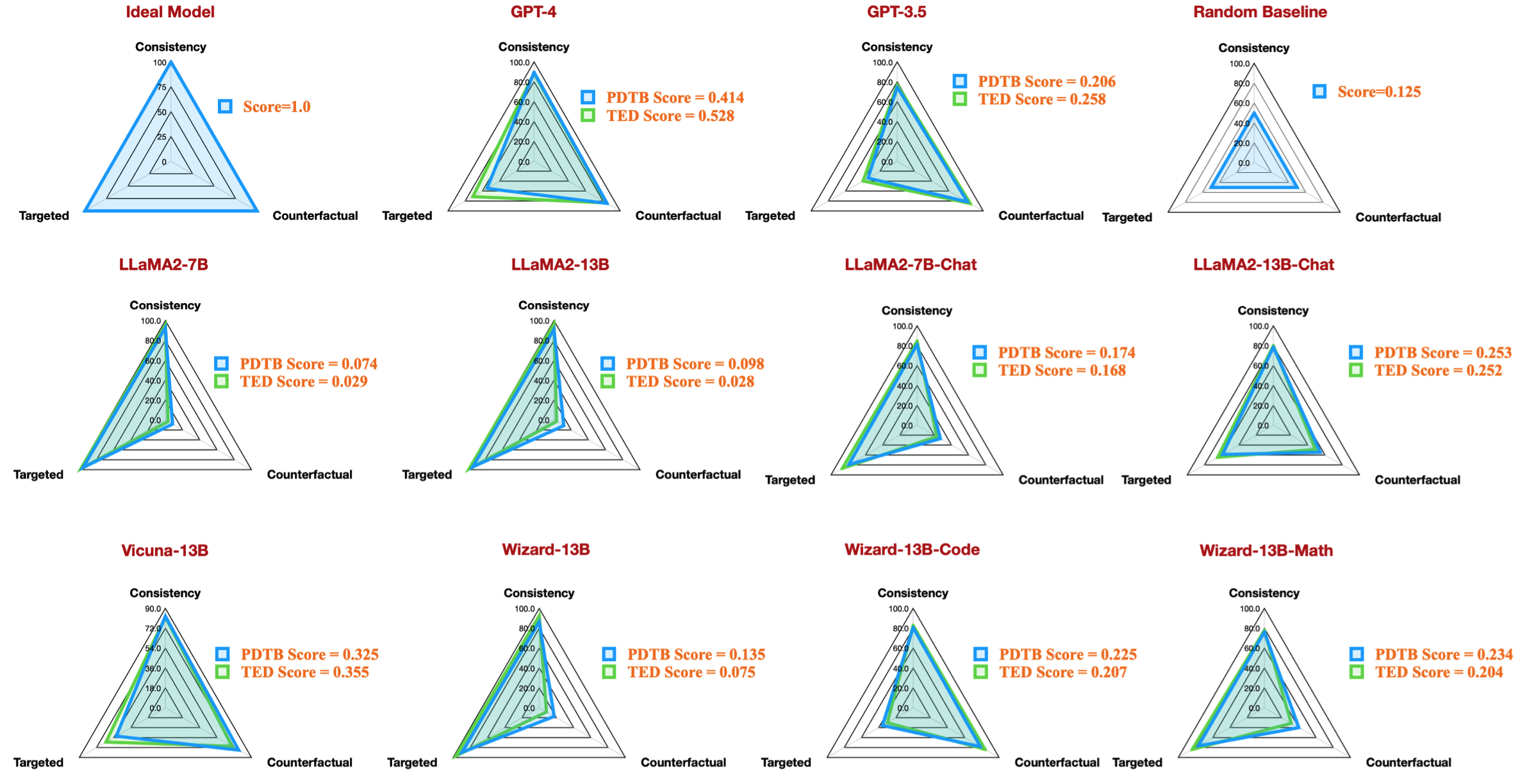
我們也提供了評估有關語言特徵的討論問題的說明:
question_generation.py中指定--feature作為conn和context (步驟 1)並重新執行所有實驗。question_generation_history.py 。該腳本將從儲存的 QA 結果中提取答案並產生新問題。對於大多數 NLPers 來說,您可能能夠在現有的虛擬 (conda) 環境中執行我們的程式碼。
當我們進行實驗時,軟體包版本如下:
torch==2.0.1
transformers==4.30.0
sentencepiece
protobuf
scikit-learn
pandas
但是,我們觀察到較新的型號需要升級的軟體包版本:
torch==2.4.0
transformers==4.43.3
sentencepiece
protobuf
scikit-learn
pandas
如果您發現我們的工作有趣,非常歡迎您嘗試我們的資料集/程式碼庫。
如果您使用過我們的資料集/程式碼庫,請引用我們的研究:
@inproceedings{acl24discursive,
title={Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' Understanding of Discourse Relations},
author={Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, and Min-Yen Kan},
booktitle={Proceedings of the Annual Meeting fof the Association of Computational Linguistics},
month={August},
year={2024},
organization={ACL},
address = "Bangkok, Thailand",
}
如果您有疑問或錯誤報告,請提出問題或直接透過電子郵件與我們聯繫:
電子郵件地址:?@?
其中 ?️= yisong , ?= comp.nus.edu.sg
CC 4.0


