CTCWordBeamSearch
1.0.0
具有字典和語言模型 (LM) 的聯結時間分類 (CTC) 解碼器。
pip install .tests/並執行pytest檢查安裝是否有效以下玩具範例展示如何使用詞束搜尋。假設模型(例如文字辨識模型)能夠辨識 3 個不同的字元:「a」、「b」和「 」(空格)。此玩具範例中的單字可以包含字元“a”和“b”(但不能包含“”,它是單字分隔符號)。語言模型是根據僅包含兩個單字的文字語料庫進行訓練的:「a」和「ba」。
在此程式碼片段中,建立了詞束搜尋的實例,並解碼了 TxBx(C+1) 形狀的 numpy 陣列:
import numpy as np
from word_beam_search import WordBeamSearch
corpus = 'a ba' # two words "a" and "ba", separated by whitespace
chars = 'ab ' # the characters that can be recognized (in this order)
word_chars = 'ab' # characters that form words
# RNN output
# 3 time-steps and 4 characters per time time ("a", "b", " ", CTC-blank)
mat = np . array ([[[ 0.9 , 0.1 , 0.0 , 0.0 ]],
[[ 0.0 , 0.0 , 0.0 , 1.0 ]],
[[ 0.6 , 0.4 , 0.0 , 0.0 ]]])
# initialize word beam search (only do this once in your code)
wbs = WordBeamSearch ( 25 , 'Words' , 0.0 , corpus . encode ( 'utf8' ), chars . encode ( 'utf8' ), word_chars . encode ( 'utf8' ))
# compute label string
label_str = wbs . compute ( mat )解碼器傳回一個列表,其中包含每個批次元素的已解碼標籤字串。要最終獲取字串,請將每個標籤映射到其對應的字元:
char_str = [] # decoded texts for batch
for curr_label_str in label_str :
s = '' . join ([ chars [ label ] for label in curr_label_str ])
char_str . append ( s )範例:
tests/test_word_beam_search.py中找到WordBeamSearch類別的建構子的參數:
0<len(wordChars)<len(chars) 。如果只需要偵測單字,則不需要分隔符,因此兩個參數也可以相等: 0<len(wordChars)<=len(chars) WordBeamSearch.compute方法的輸入:
詞束搜尋是一種CTC解碼演算法。它用於序列識別任務,例如手寫文字識別或自動語音識別。
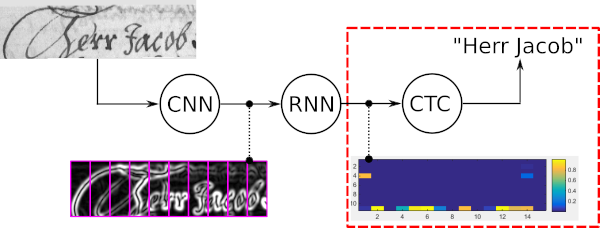
詞束搜尋的四個主要屬性是:
以下範例顯示了詞束搜尋的典型用例以及五個不同解碼器給出的結果。最佳路徑解碼和普通波束搜尋會出現錯誤,因為這些解碼器僅使用光學模型的雜訊輸出。透過字元級 LM 擴展普通波束搜索,僅允許可能的字元序列,從而改善結果。令牌傳遞使用字典和單字級 LM,因此可以正確取得所有單字。但是,它無法識別數字等任意字串。詞束搜尋能夠利用字典來辨識單字,但也能夠正確辨識非單字字元。

更多資訊:
extras/prototype/extras/tf/ 如果您在研究工作中使用詞束搜索,請引用以下論文。
@inproceedings{scheidl2018wordbeamsearch,
title = {Word Beam Search: A Connectionist Temporal Classification Decoding Algorithm},
author = {Scheidl, H. and Fiel, S. and Sablatnig, R.},
booktitle = {16th International Conference on Frontiers in Handwriting Recognition},
pages = {253--258},
year = {2018},
organization = {IEEE}
}


