Grounding_LLMs_with_online_RL
1.0.0
儲存庫包含我們的論文《Grounding Large Language Models with Online Reinforcement Learning》所使用的程式碼。
您可以在我們的網站上找到更多資訊。
我們使用GLAM方法對 BabyAI-Text 中的法學碩士知識進行功能性基礎: 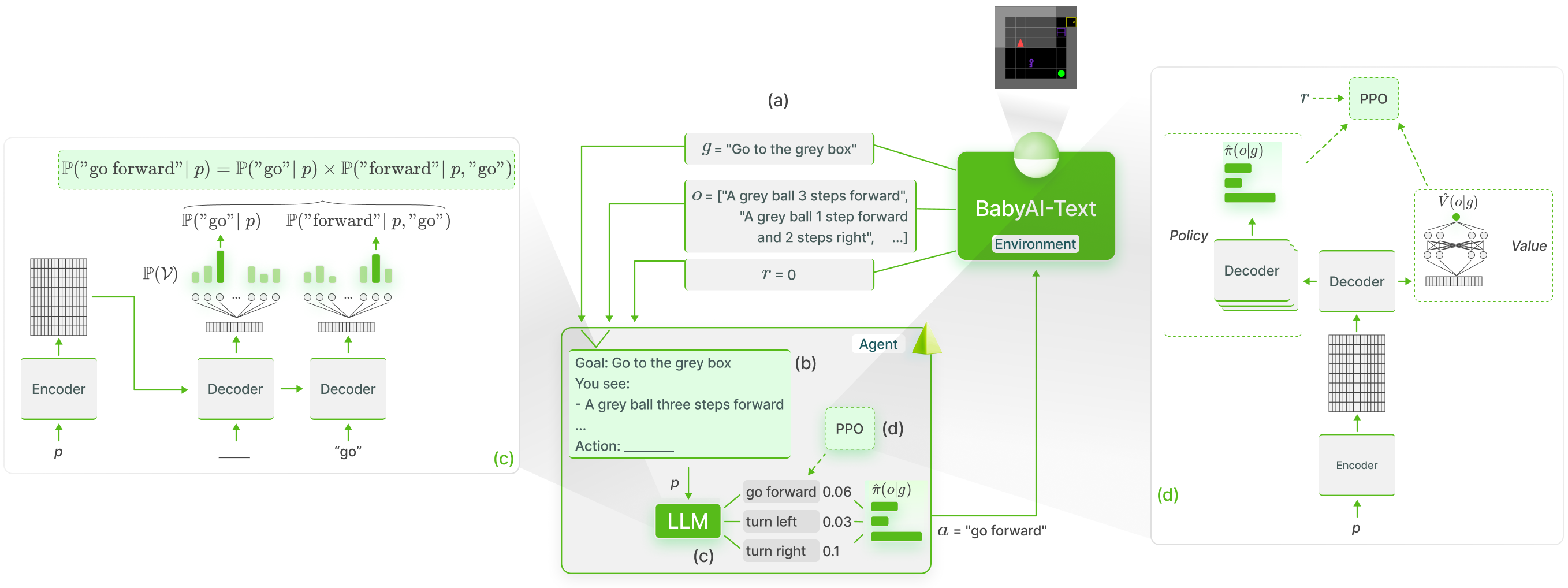
我們發布了 BabyAI-Text 環境以及執行實驗的程式碼(訓練代理並評估其效能)。我們依靠 Lamorel 圖書館來使用法學碩士。
我們的儲存庫的結構如下:
? Grounding_LLMs_with_online_RL
┣babyai babyai-text我們的BabyAI-Text環境
┣ experiments -我們的實驗代碼
┃ ┣ agents程式-執行我們所有的代理
┃ ┃ ┣ bot --利用 BabyAI 機器人的機器人代理
┃ ┃ ┣ random_agent --代理均勻隨機播放
┃ ┃ ┣ drrn -- DRRN 代理來自這裡
┃ ┃ ┣ ppo --使用 PPO 的代理
┃ ┃ ┃ ┣ symbolic_ppo_agent.py -- SymbolicPPO 改編自 BabyAI 的 PPO
┃ ┃ ┃ ┗ llm_ppo_agent.py --我們的 LLM 代理程式基於 PPO
┃ ┣ configs --我們實驗的 Lamorel 配置
┃ ┣ slurm ——在 SLURM 叢集上啟動實驗的 utils 腳本
┃ ┣ campaign -用於啟動我們實驗的 SLURM 腳本
┃ ┣ train_language_agent.py --使用 BabyAI-Text(LLM 和 DRRN)訓練代理 -> 包含我們對 LLM 的 PPO 損失的實現以及 LLM 之上的附加頭
┃ ┣ train_symbolic_ppo.py --在 BabyAI 上訓練 SymbolicPPO(使用 BabyAI-Text 的任務)
┃ ┣ post-training_tests.py --經過訓練的智能體的泛化測試
┃ ┣ test_results.py --格式化結果的實用程序
┃ ┗ clm_behavioral-cloning.py --使用軌跡對 LLM 執行行為複製的程式碼
conda create -n dlp python=3.10.8; conda activate dlp
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
安裝 BabyAI-Text :請參閱babyai-text包中的安裝詳細信息
安裝拉莫雷爾
git clone https://github.com/flowersteam/lamorel.git; cd lamorel/lamorel; pip install -e .; cd ../..
請與我們的配置一起使用 Lamorel。您可以在活動中找到我們的培訓腳本範例。
要在 BabyAI-Text 環境中訓練語言模型,必須使用train_language_agent.py檔案。該腳本(使用 Lamorel 啟動)使用以下設定條目:
rl_script_args :
seed : 1
number_envs : 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
num_steps : 1000 # Total number of training steps
max_episode_steps : 3 # Maximum number of steps in a single episode
frames_per_proc : 40 # The number of collected transitions to perform a PPO update will be frames_per_proc*number_envs
discount : 0.99 # Discount factor used in PPO
lr : 1e-6 # Learning rate used to finetune the LLM
beta1 : 0.9 # PPO's hyperparameter
beta2 : 0.999 # PPO's hyperparameter
gae_lambda : 0.99 # PPO's hyperparameter
entropy_coef : 0.01 # PPO's hyperparameter
value_loss_coef : 0.5 # PPO's hyperparameter
max_grad_norm : 0.5 # Maximum grad norm when updating the LLM's parameters
adam_eps : 1e-5 # Adam's hyperparameter
clip_eps : 0.2 # Epsilon used in PPO's losses clipping
epochs : 4 # Number of PPO epochs performed on each set of collected trajectories
batch_size : 16 # Minibatch size
action_space : ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs : ??? # Where to store logs
name_experiment : ' llm_mtrl ' # Useful for logging
name_model : ' T5small ' # Useful for logging
saving_path_model : ??? # Where to store the finetuned model
name_environment : ' BabyAI-MixedTestLocal-v0 ' # BabiAI-Text's environment
load_embedding : true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads : false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
template_test : 1 # Which prompt template to use to log evolution of action's probability (Section C of our paper). Choices or [1, 2].
nbr_obs : 3 # Number of past observation used in the prompt與語言模型本身相關的配置條目,請參閱Lamorel。
若要評估代理程式(例如經過訓練的 LLM、BabyAI 機器人...)在測試任務上的效能,請使用post-training_tests.py並設定以下設定條目:
rl_script_args :
seed : 1
number_envs : 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
max_episode_steps : 3 # Maximum number of steps in a single episode
action_space : ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs : ??? # Where to store logs
name_experiment : ' llm_mtrl ' # Useful for logging
name_model : ' T5small ' # Useful for logging
saving_path_model : ??? # Where to store the finetuned model
name_environment : ' BabyAI-MixedTestLocal-v0 ' # BabiAI-Text's environment
load_embedding : true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads : false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
nbr_obs : 3 # Number of past observation used in the prompt
number_episodes : 10 # Number of test episodes
language : ' english ' # Useful to perform the French experiment (Section H4)
zero_shot : true # Whether the zero-shot LLM (i.e. without finetuning should be used)
modified_action_space : false # Whether a modified action space (e.g. different from the one seen during training) should be used
new_action_space : # ["rotate_left","rotate_right","move_ahead","take","release","switch"] # Modified action space
im_learning : false # Whether a LLM produced with Behavioral Cloning should be used
im_path : " " # Path to the LLM learned with Behavioral Cloning
bot : false # Whether the BabyAI's bot agent should be used

