LM SupCon
1.0.0
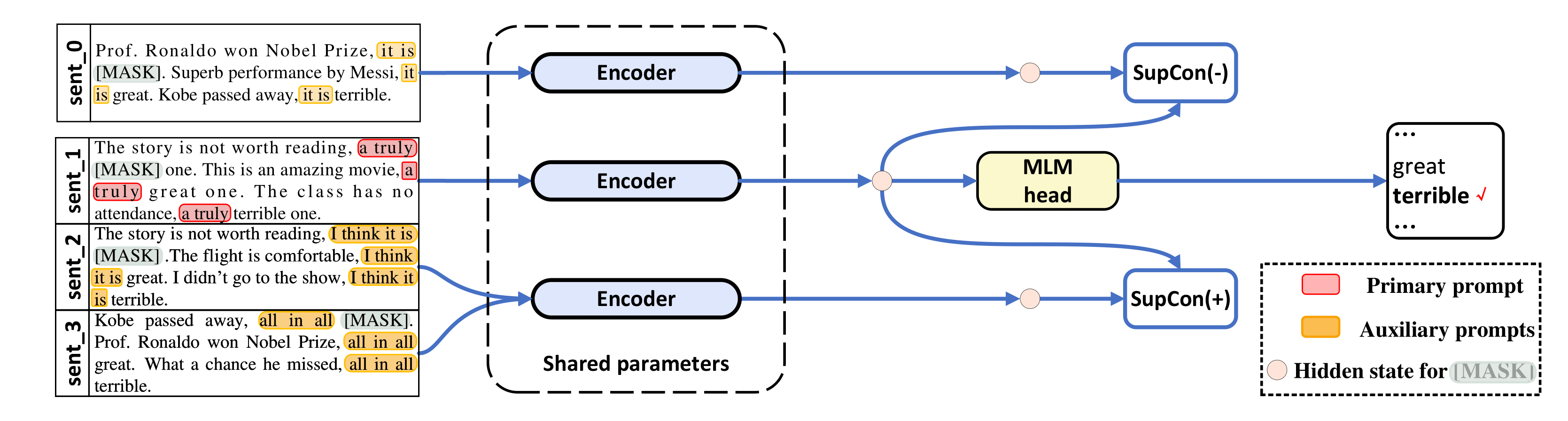
本資料庫涵蓋以下論文的實作: 《Contrastive Learning for Prompt-based Few-shot Language Learners》,作者:Yirenjian、Chongyang Gau 和 Soroush Vosoughi,已被 NAACL 2022 接收。
如果您發現此儲存庫對您的研究有用,請考慮引用論文。
@inproceedings { jian-etal-2022-contrastive ,
title = " Contrastive Learning for Prompt-based Few-shot Language Learners " ,
author = " Jian, Yiren and
Gao, Chongyang and
Vosoughi, Soroush " ,
booktitle = " Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies " ,
month = jul,
year = " 2022 " ,
address = " Seattle, United States " ,
publisher = " Association for Computational Linguistics " ,
url = " https://aclanthology.org/2022.naacl-main.408 " ,
pages = " 5577--5587 " ,
abstract = "The impressive performance of GPT-3 using natural language prompts and in-context learning has inspired work on better fine-tuning of moderately-sized models under this paradigm. Following this line of work, we present a contrastive learning framework that clusters inputs from the same class for better generality of models trained with only limited examples. Specifically, we propose a supervised contrastive framework that clusters inputs from the same class under different augmented {``}views{''} and repel the ones from different classes. We create different {``}views{''} of an example by appending it with different language prompts and contextual demonstrations. Combining a contrastive loss with the standard masked language modeling (MLM) loss in prompt-based few-shot learners, the experimental results show that our method can improve over the state-of-the-art methods in a diverse set of 15 language tasks. Our framework makes minimal assumptions on the task or the base model, and can be applied to many recent methods with little modification.",
}我們的程式碼大量借鏡自 LM-BFF 和 SupCon ( /src/losses.py )。
此儲存庫已使用 Ubuntu 18.04.5 LTS、Python 3.7、PyTorch 1.6.0 和 CUDA 10.1 進行測試。您將需要 48 GB GPU 來進行 RoBERTa-base 實驗,並需要 4 個 48 GB GPU 來進行 RoBERTa-large 實驗。我們在 Nvidia RTX-A6000 和 RTX-8000 上運行實驗,但 40 GB 的 Nvidia A100 也應該可以工作。
我們使用來自 LM-BFF 的預處理資料集(SST-2、SST-5、MR、CR、MPQA、Subj、TREC、CoLA、MNLI、SNLI、QNLI、RTE、MRPC、QQP)。 LM-BFF 提供了用於下載和準備資料集的有用腳本。只需運行以下命令即可。
cd data
bash download_dataset.sh然後使用以下命令產生我們在研究中使用的 16 個鏡頭資料集。
python tools/generate_k_shot_data.py用於任務的主要提示(範本)已在run_experiments.sh中預先定義。產生用於對比學習的輸入的多視圖時使用的輔助模板可以在/auto_template/$TASK中找到。
假設您的系統中有一個 GPU,我們將展示一個在 SST-5 上運行微調的範例(隨機模板和輸入「增強視圖」的隨機演示)。
for seed in 13 21 42 87 100 # ### random seeds for different train-test splits
do
for bs in 40 # ### batch size
do
for lr in 1e-5 # ### learning rate for MLM loss
do
for supcon_lr in 1e-5 # ### learning rate for SupCon loss
do
TAG=exp
TYPE=prompt-demo
TASK=sst-5
BS= $bs
LR= $lr
SupCon_LR= $supcon_lr
SEED= $seed
MODEL=roberta-base
bash run_experiment.sh
done
done
done
done
rm -rf result/我們的框架也適用於基於提示的方法,無需演示,即TYPE=prompt (在這種情況下,我們僅隨機採樣模板以產生「增強視圖」)。結果保存在log中。
使用 RoBERTa-large 作為基礎模型需要 4 個 GPU,每個 GPU 具有 48 GB 記憶體。您需要先將src/models.py中的第 20 行編輯為def __init__(self, hidden_size=1024) 。
for seed in 13 21 42 87 100 # ### random seeds for different train-test splits
do
for bs in 10 # ### batch size for each GPU, total batch size is then 40
do
for lr in 1e-5 # ### learning rate for MLM loss
do
for supcon_lr in 1e-5 # ### learning rate for SupCon loss
do
TAG=exp
TYPE=prompt-demo
TASK=sst-5
BS= $bs
LR= $lr
SupCon_LR= $supcon_lr
SEED= $seed
MODEL=roberta-large
bash run_experiment.sh
done
done
done
done
rm -rf result/ python tools/gather_result.py --condition "{'tag': 'exp', 'task_name': 'sst-5', 'few_shot_type': 'prompt-demo'}"
它將收集log結果並計算這 5 次訓練測試分割的平均值和標準差。
如有任何疑問,請聯絡作者。
感謝 LM-BFF 和 SupCon 的初步實施。


