DialogStudio
1.0.0

紙、Huggingface、模型、Twitter
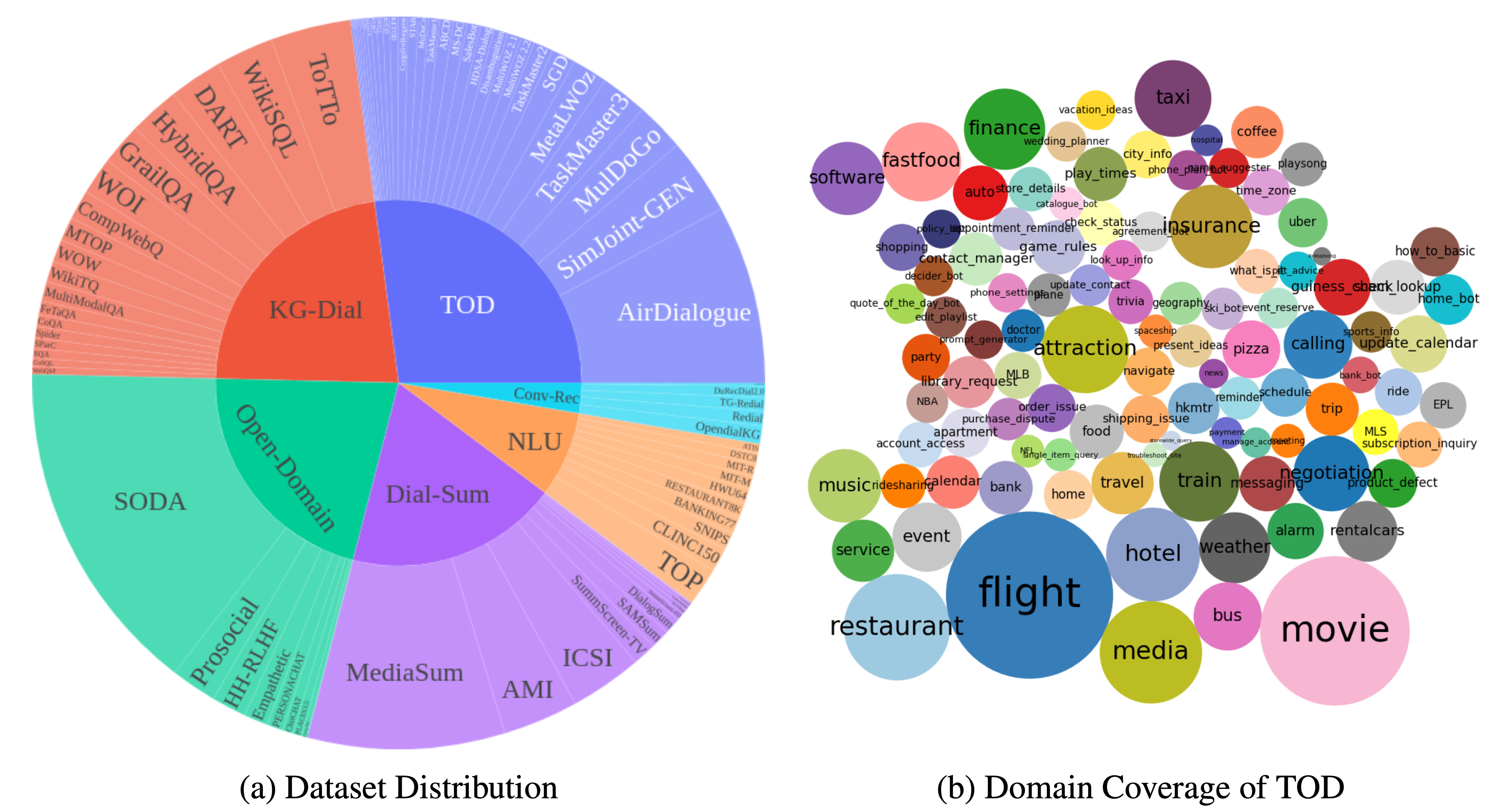
DialogStudio是一個大型集合和統一的對話框資料集。下圖提供了與DialogStudio相關的一般統計資訊的摘要。 DialogStudio統一了每個資料集,同時保留其原始訊息,這有助於支援單一資料集和大型語言模型 (LLM) 訓練的研究。所有可用資料集的完整清單位於此處。
數據可透過 Huggingface 下載,如載入資料中所述。我們還為此存儲庫中的每個資料集提供了範例。有關更細粒度和特定於類別的詳細信息,請參閱DialogStudio集合中與每個類別相對應的各個資料夾,例如面向任務的對話類別下的 MULTIWOZ2_2 資料集。
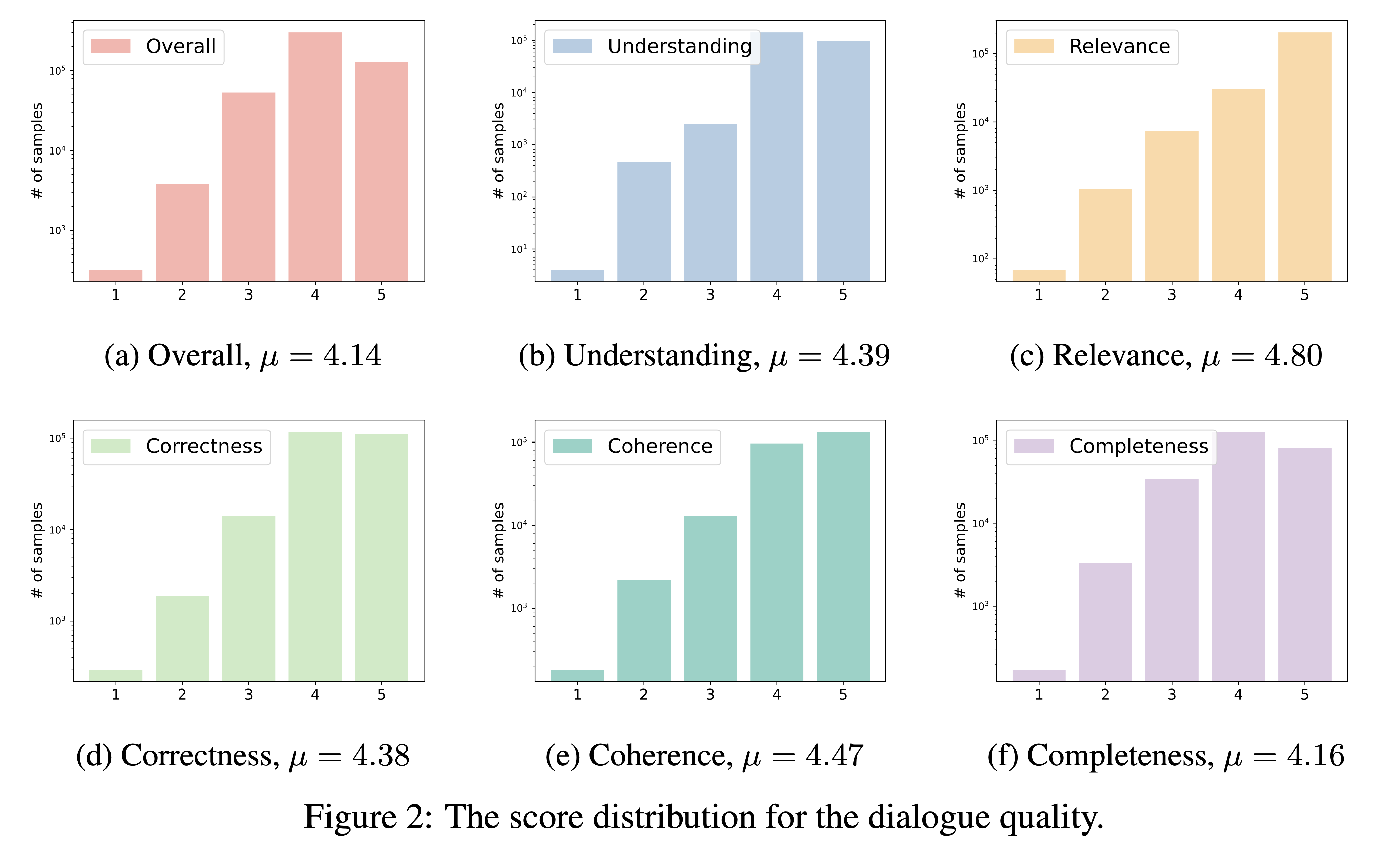
DialogStudio根據六個關鍵標準評估對話質量,即理解、相關性、正確性、連貫性、完整性和整體品質。每個標準的評分範圍為 1 到 5,最高分保留給特殊對話。
鑑於DialogStudio中包含大量資料集,我們使用「gpt-3.5-turbo」來評估 33 個不同的資料集。可以透過連結存取用於此評估的相應腳本。
我們的對話品質評估結果如下所示。我們打算在接下來的一段時間內發佈單獨選擇的對話的評估分數。
您可以透過聲明{dataset_name} (即資料集資料夾名稱)從 HuggingFace 中心載入DialogStudio中的任何資料集。所有可用的資料集都在資料集內容中進行了描述。
以下是在任務導向對話的類別下載入 MULTIWOZ2_2 資料集的範例:
載入資料集
from datasets import load_dataset
dataset = load_dataset ( 'Salesforce/ DialogStudio ' , 'MULTIWOZ2_2' )這是MultiWOZ 2.2的輸出結構
DatasetDict ({
train : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 8437
})
validation : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
test : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
})在此 GitHub 儲存庫和 HuggingFace 中心中,資料集分為幾個類別。您可以查看資料集表以獲取更多資訊。您可以單擊每個資料夾來檢查一些範例:
我們推出了在一些選定的DialogStudio資料集上進行訓練的模型 1.0 版( DialogStudio -t5-base-v1.0、 DialogStudio -t5-large-v1.0、 DialogStudio -t5-3b-v1.0)。檢查每個型號卡以了解更多詳細資訊。
下面是在 CPU 上運行模型的範例:
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
input_text = "Answer the following yes/no question by reasoning step-by-step. Can you write 200 words in a single tweet?"
input_ids = tokenizer ( input_text , return_tensors = "pt" ). input_ids
outputs = model . generate ( input_ids , max_new_tokens = 256 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))我們的專案在許可方面遵循以下結構:
有關詳細許可信息,請參閱原始資料集附帶的特定許可。熟悉這些條款非常重要,因為我們不承擔許可問題的責任。
我們衷心感謝所有為對話式人工智慧領域做出貢獻的資料集作者。儘管付出了精心的努力,我們的引文或參考文獻中仍可能出現不準確的情況。如果您發現任何錯誤或遺漏,請提出問題或提交拉取請求以協助我們改進。謝謝你!
該儲存庫中的資料和程式碼主要是為下面的論文開發或衍生自下面的論文。如果您使用DialogStudio的資料集,我們懇請您引用原始作品和我們自己的作品(已被 EACL 2024 年調查結果接受為長論文)。
@article{zhang2023 DialogStudio ,
title={ DialogStudio : Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI},
author={Zhang, Jianguo and Qian, Kun and Liu, Zhiwei and Heinecke, Shelby and Meng, Rui and Liu, Ye and Yu, Zhou and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint arXiv:2307.10172},
year={2023}
}
我們熱忱邀請社會各界踴躍投稿!加入我們共同的使命,推動對話式人工智慧領域向前發展!


