aug pe
1.0.0
?論文 • 資料 (Yelp/OpenReview/PubMed) • 專案頁面
此儲存庫實現了增強私有演化 (Aug-PE) 演算法,利用對大型語言模型 (LLM) 的推理 API 存取來產生差分私有 (DP) 合成文本,而無需模型訓練。我們比較 DP-SGD 微調和 Aug-PE:

在下面
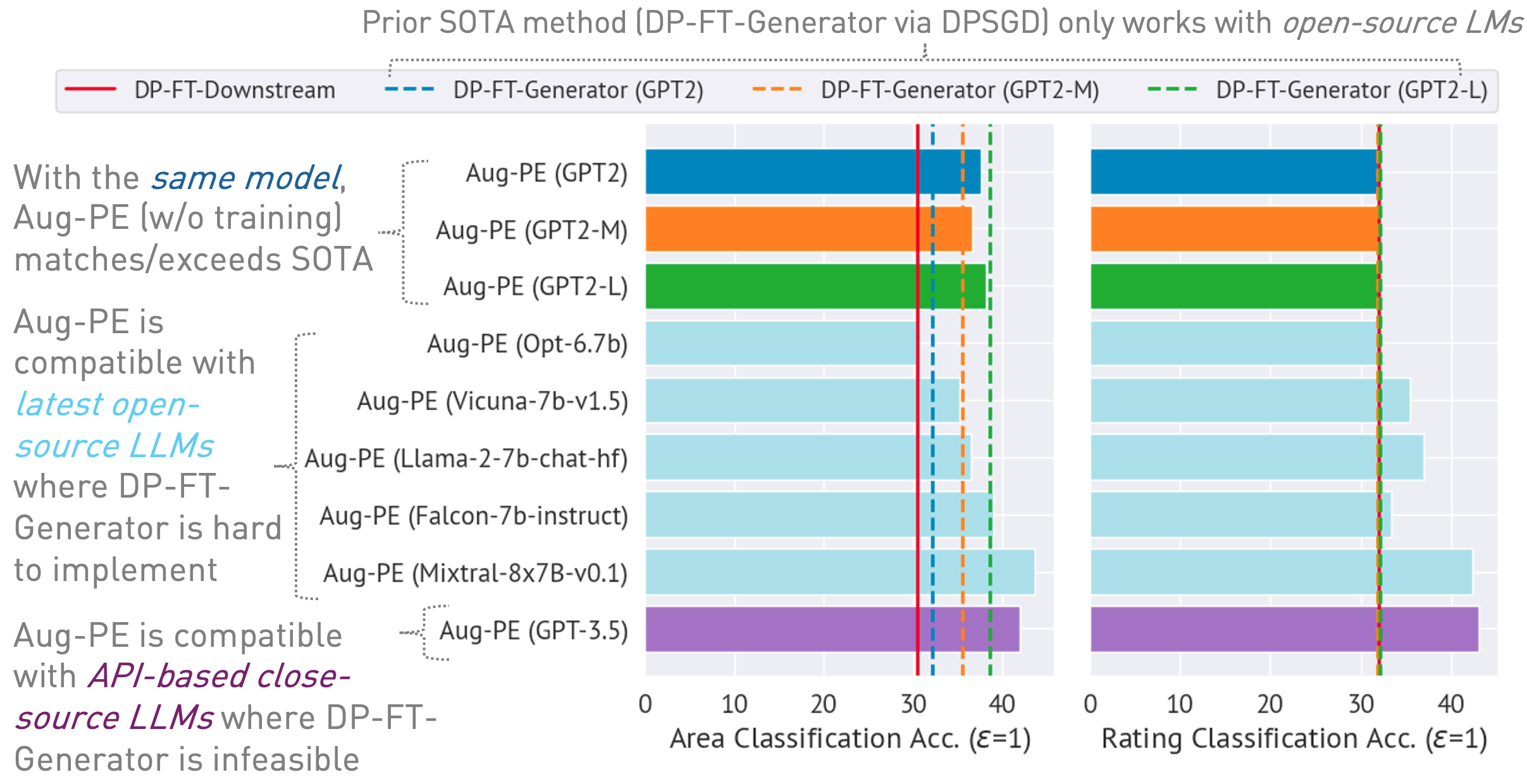
03/13/2024 :專案頁面可用,其中概述了演算法及其結果。03/11/2024 :代碼和 ArXiv 論文可用。 conda env create -f environment.yml
conda activate augpe
資料集位於data/{dataset}其中dataset是yelp 、 openreview和pubmed 。
從此連結下載 Yelp train.csv (1.21G) 和 PubMed train.csv (117MB) 或執行:
bash scripts/download_data.sh # download yelp train.csv and pubmed train.csv資料集描述:
預計算私有資料的嵌入(Aug-PE 演算法中的第 1 行):
bash scripts/embeddings.sh --openreview # Compute private embeddings
bash scripts/embeddings.sh --pubmed
bash scripts/embeddings.sh --yelp 注意:計算 OpenReview 和 PubMed 的嵌入相對較快。但是,由於 Yelp 的資料集規模較大(190 萬訓練樣本),因此過程可能需要約 40 分鐘。
在給定隱私預算的情況下,計算notebook/dp_budget.ipynb中資料集的 DP 雜訊級別
若要使用 Wandb 進行視覺化,請在dpsda/arg_utils.py中使用您的金鑰和專案名稱配置--wandb_key和--project 。
利用 Hugging Face 的開源法學碩士來產生合成資料:
export CUDA_VISIBLE_DEVICES=0
bash scripts/hf/{dataset}/generate.sh # Replace `{dataset}` with yelp, openreview, or pubmed一些關鍵的超參數:
noise :DP 噪音。epoch :我們使用 10 個 epoch 進行 DP 設定。對於非 DP 設置,我們對 Yelp 使用 20 個 epoch,對其他資料集使用 10 個 epoch。model_type :huggingface 上的模型,例如 ["gpt2", "gpt2-medium", "gpt2-large", "meta-llama/Llama-2-7b-chat-hf", "tiiuae/falcon-7b-instruct" 、「facebook/opt-6.7b」、「lmsys/vicuna-7b-v1.5」、「mistralai/Mixtral-8x7B-Instruct-v0.1」]。num_seed_samples :合成樣本的數量。lookahead_degree :合成樣本嵌入估計的變化數量(Aug-PE 演算法中的第 5 行)。預設值為 0(自嵌入)。L :與產生候選合成樣本的變體數量有關(Aug-PE 演算法中的第 18 行)feat_ext :在 Huggingface 句子轉換器上嵌入模型。select_syn_mode :根據直方圖投票或機率選擇合成樣本。預設為rank (Aug-PE 演算法中的第 19 行)temperature :LLM 產生的溫度。使用DP合成文字對下游模型進行微調,並在真實測試資料上評估模型的準確性:
bash scripts/hf/{dataset}/downstream.sh # Finetune downstream model and evaluate performance 測量嵌入分佈距離:
bash scripts/hf/{dataset}/metric.sh # Calculate distribution distance對於結合了所有生成和評估步驟的簡化流程:
bash scripts/hf/template/{dataset}.sh # Complete workflow for each dataset 我們透過 Azure OpenAI API 使用閉源模型。請在apis/azure_api.py中設定您的金鑰和端點
MODEL_CONFIG = {
'gpt-3.5-turbo' :{ "openai_api_key" : "YOUR_AZURE_OPENAI_API_KEY" ,
"openai_api_base" : "YOUR_AZURE_OPENAI_ENDPOINT" ,
"engine" : 'YOUR_DEPLOYMENT_NAME' ,
},
}這裡的engine可能是 Azure 中的gpt-35-turbo 。
執行以下腳本產生合成數據,在下游任務上進行評估,並計算真實數據和合成數據之間的嵌入分佈距離:
bash scripts/gpt-3.5-turbo/{dataset}.sh我們使用 GPT-3.5 的文字長度相關提示來控制生成文字的長度。我們在這裡引入幾個額外的超參數:
dynamic_len用於啟用動態長度機制。word_var_scale :用來決定targeted_word的高斯雜訊方差。max_token_word_scale :每個單字的最大標記數。我們根據targeted_word(提示中指定)和max_token_word_scale來設定LLM產生的max_token。使用筆記本計算真實資料和合成資料之間的文字長度分佈差異: notebook/text_lens_distribution.ipynb
如果您發現我們的工作有幫助,請考慮引用如下:
@inproceedings {
xie2024differentially,
title = { Differentially Private Synthetic Data via Foundation Model {API}s 2: Text } ,
author = { Chulin Xie and Zinan Lin and Arturs Backurs and Sivakanth Gopi and Da Yu and Huseyin A Inan and Harsha Nori and Haotian Jiang and Huishuai Zhang and Yin Tat Lee and Bo Li and Sergey Yekhanin } ,
booktitle = { Forty-first International Conference on Machine Learning } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=LWD7upg1ob }
}如果您對程式碼或論文有任何疑問,請隨時發送電子郵件至 Chulin ([email protected]) 或提出問題。


