reflexion
1.0.0
此儲存庫包含用於reflexion的程式碼、演示和日誌檔案:Noah Shinn、Federico Cassano、Edward Berman、Ashwin Gopinath、Karthik Narasimhan、Shunyu Yao 的語言代理與言語強化學習。
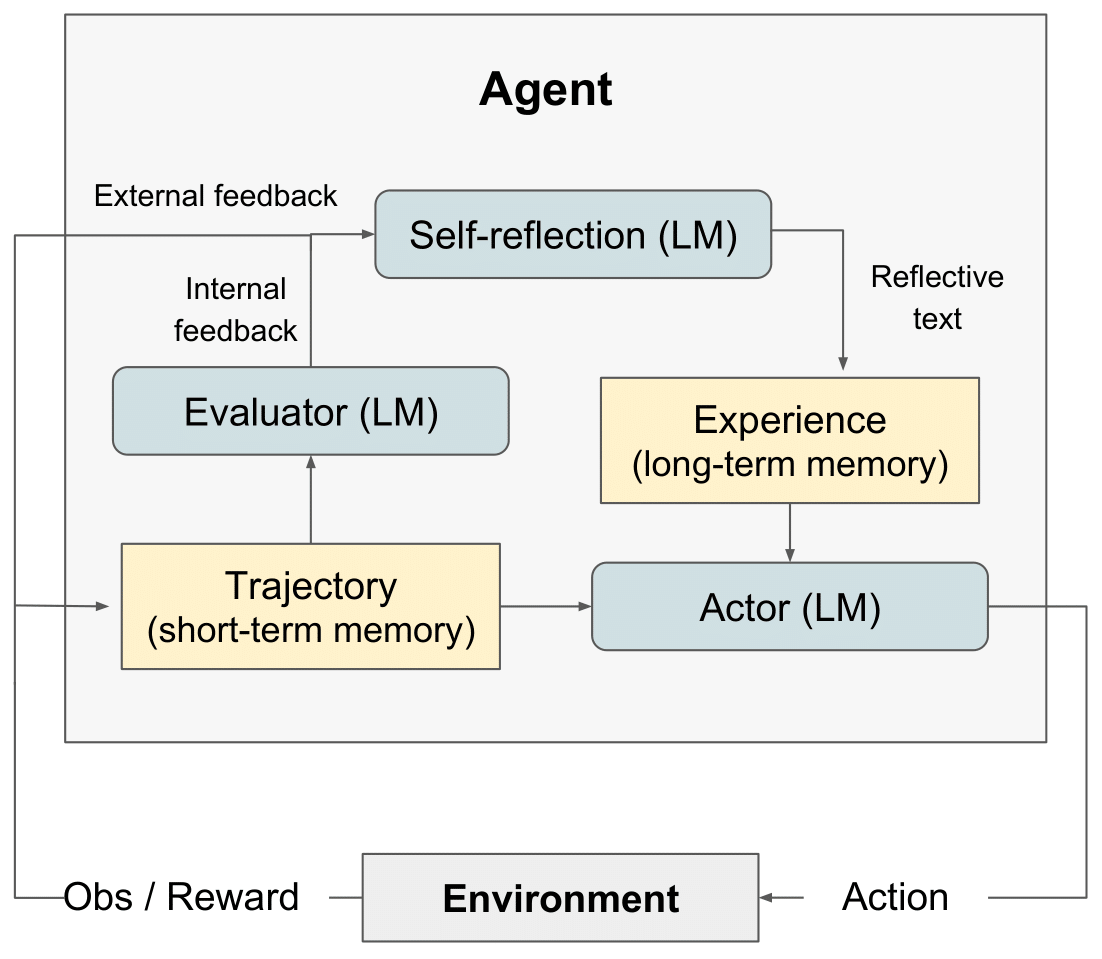 反射 RL 圖" style="max-width: 100%;">
反射 RL 圖" style="max-width: 100%;">
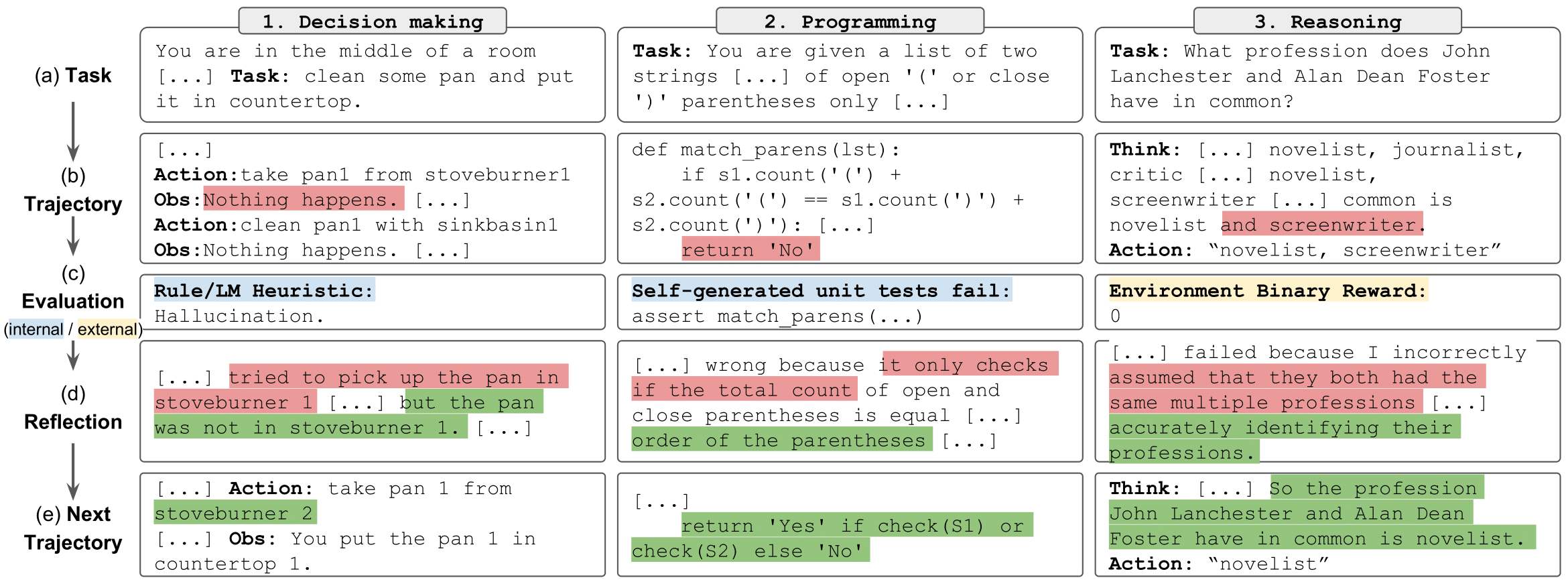 反射任務" style="max-width: 100%;">
反射任務" style="max-width: 100%;">
我們在這裡發布了LeetcodeHardGym
我們提供了一組筆記本,可以輕鬆運行、探索推理實驗結果並與之互動。每個實驗都包含來自 HotPotQA 幹擾資料集的 100 個問題的隨機樣本。範例中的每個問題均由具有特定類型和reflexion策略的代理程式嘗試。
開始使用:
git clone https://github.com/noahshinn/reflexion && cd ./hotpotqa_runspip install -r requirements.txtOPENAI_API_KEY環境變數設定為您的 OpenAI API 金鑰: export OPENAI_API_KEY= < your key > 代理類型由您選擇運行的筆記本決定。可用的代理類型包括:
ReAct - 反應代理
CoT_context - CoT 代理程式給出有關問題的支援上下文
CoT_no_context - CoT 代理程式沒有給出有關問題的支援上下文
每種代理類型的筆記本位於./hotpot_runs/notebooks目錄中。
每個筆記本都允許您指定代理要使用的reflexion策略。可用的reflexion策略在Enum中定義,包括:
reflexion Strategy.NONE - 代理程式不會獲得有關其上次嘗試的任何資訊。
reflexion Strategy.LAST_ATTEMPT - 代理人從其對問題的最後一次嘗試中獲得推理軌跡作為上下文。
reflexion Strategy. reflexion - 代理人對最後一次嘗試進行自我反思作為脈絡。
reflexion Strategy.LAST_ATTEMPT_AND_ reflexion - 代理人會獲得其推理軌跡和最後一次嘗試的自我反思作為上下文。
克隆此儲存庫並移至 AlfWorld 目錄
git clone https://github.com/noahshinn/reflexion && cd ./alfworld_runs在./run_ reflexion .sh中指定運行參數。 num_trials :迭代學習步驟數num_envs :每次試驗的任務環境對數run_name :本次運行的名稱use_memory :使用持久內存來存儲自我反思(關閉以運行基線運行) is_resume :使用日誌記錄目錄來恢復先前的運行resume_dir :從中還原先前運行的日誌記錄目錄start_trial_num :如果恢復運行,則要啟動的試驗編號
運行試驗
./run_ reflexion .sh日誌將發送到./root/<run_name> 。
由於這些實驗的性質,個人開發者重新運行結果可能不可行,因為 GPT-4 的存取權限有限且 API 費用很高。論文中的所有運行和其他結果都記錄在./alfworld_runs/root中用於決策, ./hotpotqa_runs/root中用於推理,以及./programming_runs/root中用於編程
在這裡查看原始程式碼的程式碼
在這裡閱讀部落格文章
在這裡查看一個有趣的類型預測實作:OpenTau
如有任何問題,請聯絡 [email protected]
@misc { shinn2023 reflexion ,
title = { reflexion : Language Agents with Verbal Reinforcement Learning } ,
author = { Noah Shinn and Federico Cassano and Edward Berman and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao } ,
year = { 2023 } ,
eprint = { 2303.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.AI }
}

