machine learning experiments
1.0.0
??烏克蘭正在遭到俄羅斯軍隊的攻擊。平民正在被殺害。住宅區遭到轟炸。
- 透過以下方式幫助烏克蘭:
- 謝爾希·普里圖拉慈善基金會
- 活著回來慈善基金會
- 烏克蘭國家銀行
- 更多資訊請上 war.ukraine.ua 和烏克蘭外交部
這是互動式機器學習實驗的集合。每個實驗都包含 ?️ Jupyter/Colab筆記本(看看模型是如何訓練的)和 ?演示頁面(在瀏覽器中查看正在運行的模型)。
您可能也對自製 GPT • JS 感興趣
️ 此儲存庫包含機器學習實驗,而不是生產就緒、可重複使用、最佳化和微調的程式碼和模型。這更像是一個沙箱或一個用於學習和嘗試不同機器學習方法、演算法和資料集的遊樂場。模型可能表現不佳,並且存在過度擬合/欠擬合的情況。
這些實驗中的大多數模型都是使用 Keras 支援的 TensorFlow 2 進行訓練的。
監督學習是指當您有輸入變數X和輸出變數Y時,您使用演算法來學習從輸入到輸出的映射函數: Y = f(X) 。目標是很好地近似映射函數,以便當您有新的輸入資料X時,您可以預測該資料的輸出變數Y之所以稱為監督式學習,是因為演算法從訓練資料集中學習的過程可以被視為監督學習過程的老師。
多層感知器 (MLP) 是一類前饋人工神經網路 (ANN)。多層感知器有時被稱為「普通」神經網路(由多層感知器組成),特別是當它們具有單一隱藏層時。它可以區分不可線性分離的資料。
| 實驗 | 模型演示和培訓 | 標籤 | 數據集 | |
|---|---|---|---|---|
 | 手寫數字辨識 (MLP) | MLP | MNIST | |
 | 手寫草圖辨識 (MLP) | MLP | 快速繪圖 |
卷積神經網路(CNN 或 ConvNet)是一類深度神經網絡,最常用於分析視覺影像(照片、影片)。它們用於檢測和分類照片和影片上的物件、風格遷移、人臉辨識、姿勢估計等。
| 實驗 | 模型演示和培訓 | 標籤 | 數據集 | |
|---|---|---|---|---|
 | 手寫數字辨識 (CNN) | CNN | MNIST | |
 | 手寫草圖辨識 (CNN) | CNN | 快速繪圖 | |
 | 剪刀石頭布 (CNN) | CNN | RPS | |
 | 剪刀石頭布(MobilenetV2) | MobileNetV2 , Transfer learning , CNN | 影像網路 | |
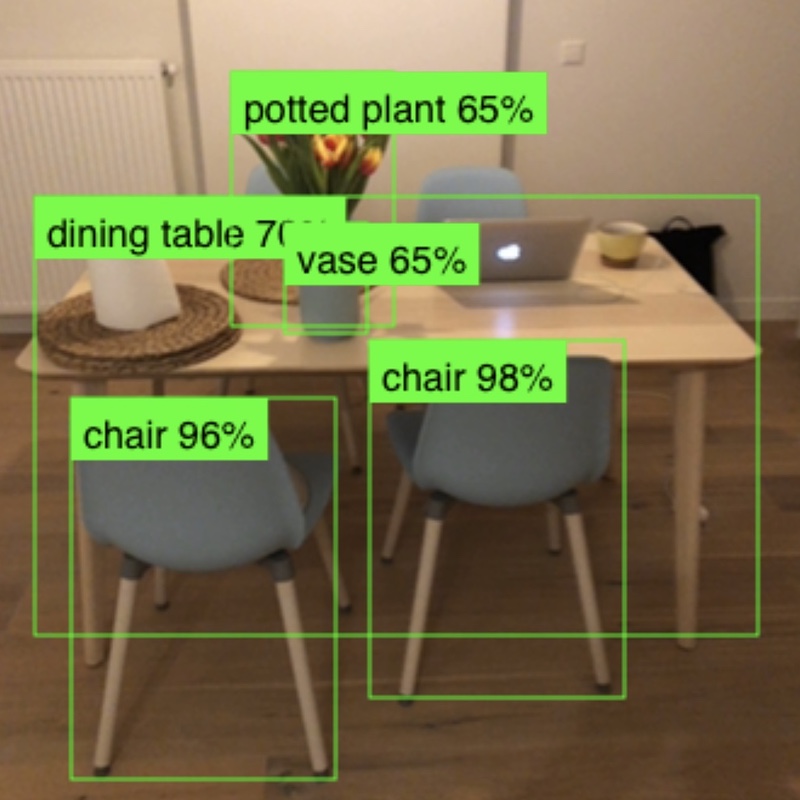 | 物體偵測 (MobileNetV2) | MobileNetV2 、 SSDLite 、 CNN | 可可 | |
 | 影像分類(MobileNetV2) | MobileNetV2 CNN | 影像網 |
循環神經網路 (RNN) 是一類深度神經網絡,最常應用於基於序列的數據,如語音、語音、文字或音樂。它們用於機器翻譯、語音辨識、語音合成等。
| 實驗 | 模型演示和培訓 | 標籤 | 數據集 | |
|---|---|---|---|---|
 | 數字求和 (RNN) | LSTM , Sequence-to-sequence | 自動生成 | |
 | 莎士比亞文本生成 (RNN) | LSTM , Character-based RNN | 莎士比亞 | |
 | 維基百科文本生成(RNN) | LSTM , Character-based RNN | 維基百科 | |
 | 配方生成(RNN) | LSTM , Character-based RNN | 食譜盒 |
無監督學習是指只有輸入資料X而沒有對應的輸出變數。無監督學習的目標是對資料的底層結構或分佈進行建模,以便更了解資料。這些被稱為無監督學習,因為與上面的監督學習不同,沒有正確答案,也沒有老師。演算法自行發現並呈現資料中有趣的結構。
生成對抗網路(GAN)是一類機器學習框架,其中兩個神經網路在遊戲中相互競爭。兩個模型透過對抗過程同時訓練。例如,生成器(“藝術家”)學習創建看起來真實的圖像,而鑑別器(“藝術評論家”)學習區分真實圖像和贗品。
| 實驗 | 模型演示和培訓 | 標籤 | 數據集 | |
|---|---|---|---|---|
 | 衣服世代(DCGAN) | DCGAN | 時尚 MNIST |
# Create "experiments" environment (from the project root folder).
python3 -m venv .virtualenvs/experiments
# Activate environment.
source .virtualenvs/experiments/bin/activate
# or if you use Fish...
source .virtualenvs/experiments/bin/activate.fish若要退出環境,請執行deactivate 。
# Upgrade pip and setuptools to the latest versions.
pip install --upgrade pip setuptools
# Install packages
pip install -r requirements.txt若要安裝新軟體包,請執行pip install package-name 。若要將新套件新增至需求中,請執行pip freeze > requirements.txt 。
為了使用 Jupyter Notebook 並查看模型是如何訓練的,您需要啟動 Jupyter Notebook 伺服器。
# Launch Jupyter server.
jupyter notebook Jupyter 將在本地提供http://localhost:8888/ 。帶有實驗的筆記本可以在experiments資料夾中找到。
演示應用程式是透過 create-react-app 在 React 上製作的。
# Switch to demos folder from project root.
cd demos
# Install all dependencies.
yarn install
# Start demo server on http.
yarn start
# Or start demo server on https (for camera access in browser to work on localhost).
yarn start-https演示將在本地提供http://localhost:3000/或https://localhost:3000/ 。
converter環境用於將實驗期間訓練的模型從.h5 Keras 格式轉換為 Javascript 可理解的格式(帶有.json和.bin檔案的tfjs_layers_model或tfjs_graph_model格式),以便在演示應用程式中進一步與TensorFlow.js一起使用。
# Create "converter" environment (from the project root folder).
python3 -m venv .virtualenvs/converter
# Activate "converter" environment.
source .virtualenvs/converter/bin/activate
# or if you use Fish...
source .virtualenvs/converter/bin/activate.fish
# Install converter requirements.
pip install -r requirements.converter.txt keras模型到tfjs_layers_model / tfjs_graph_model格式的轉換是由 tfjs-converter 完成的:
例如:
tensorflowjs_converter --input_format keras
./experiments/digits_recognition_mlp/digits_recognition_mlp.h5
./demos/public/models/digits_recognition_mlp
️ 將模型轉換為JS 可理解的格式並直接將其加載到瀏覽器可能不是一個好的做法,因為在這種情況下,用戶可能需要將數十或數百兆位元組的資料加載到瀏覽器,這效率不高。通常,模型是從後端(即 TensorFlow Extended)提供服務的,使用者不會將其全部載入到瀏覽器,而是會執行輕量級 HTTP 請求來進行預測。但由於演示應用程式只是一個實驗,而不是一個可用於生產的應用程序,並且為了簡單起見(以避免後端啟動和運行),我們將模型轉換為 JS 可理解的格式,並將它們直接加載到瀏覽器。
推薦版本:
> 3.7.3 。>= 12.4.0 。>= 1.13.0 。如果您使用的是 Python 版本3.7.3在嘗試import tensorflow時可能會遇到RuntimeError: dictionary changed size during iteration錯誤(請參閱問題)。


