ChatGPT、GenerativeAI 和法學碩士時間表
該儲存庫組織了 ChatGPT 公告前後發生的關鍵事件(產品、服務、論文、GitHub、部落格文章和新聞)的時間表。
它在此時間線中整理了各種信息,特別關注法學碩士和生成人工智慧。
也許這是最熱門歷史中的一個場景,所以我認為好好保存這些記憶很重要,所以我把它們整理了一下。
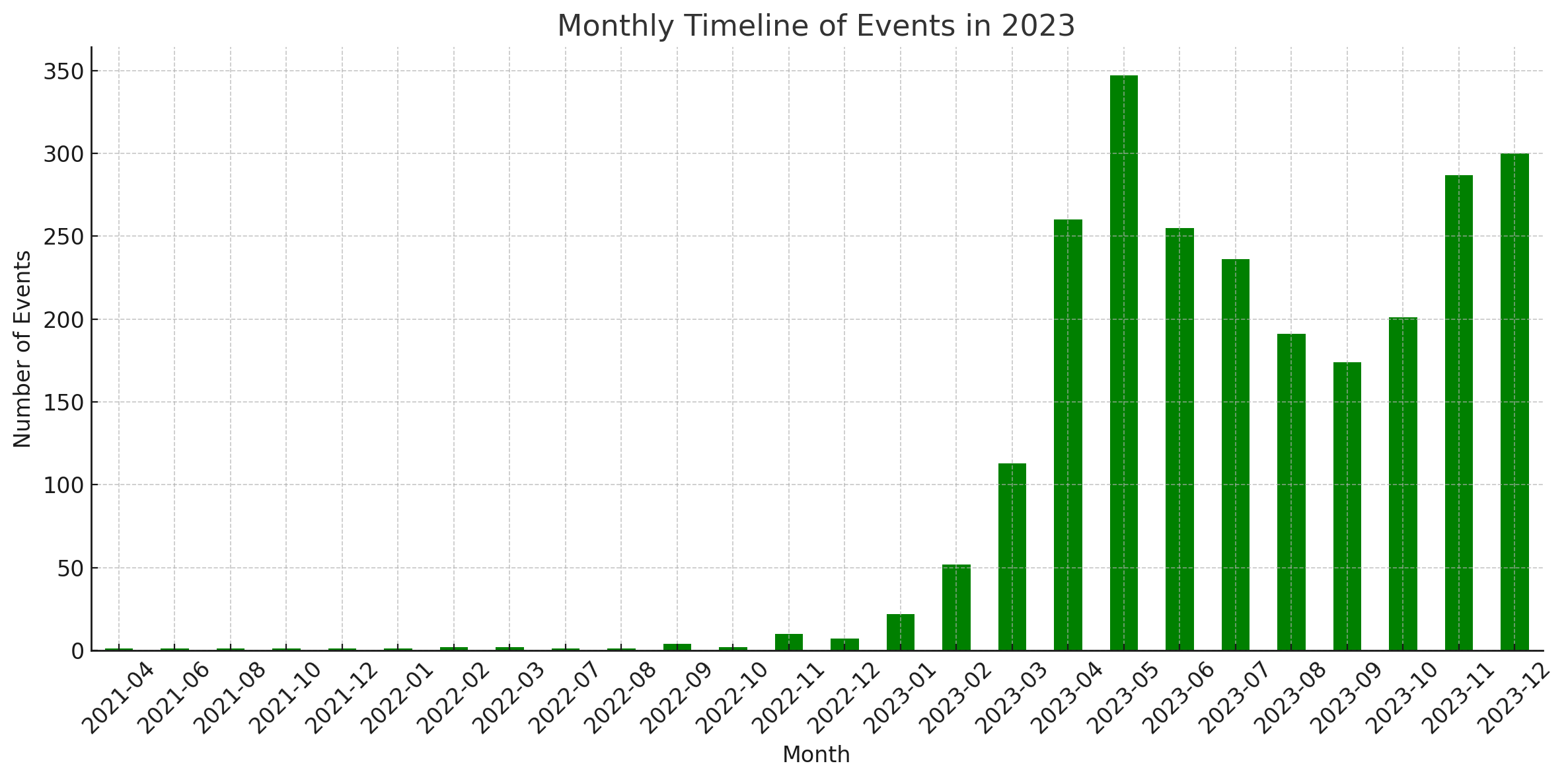
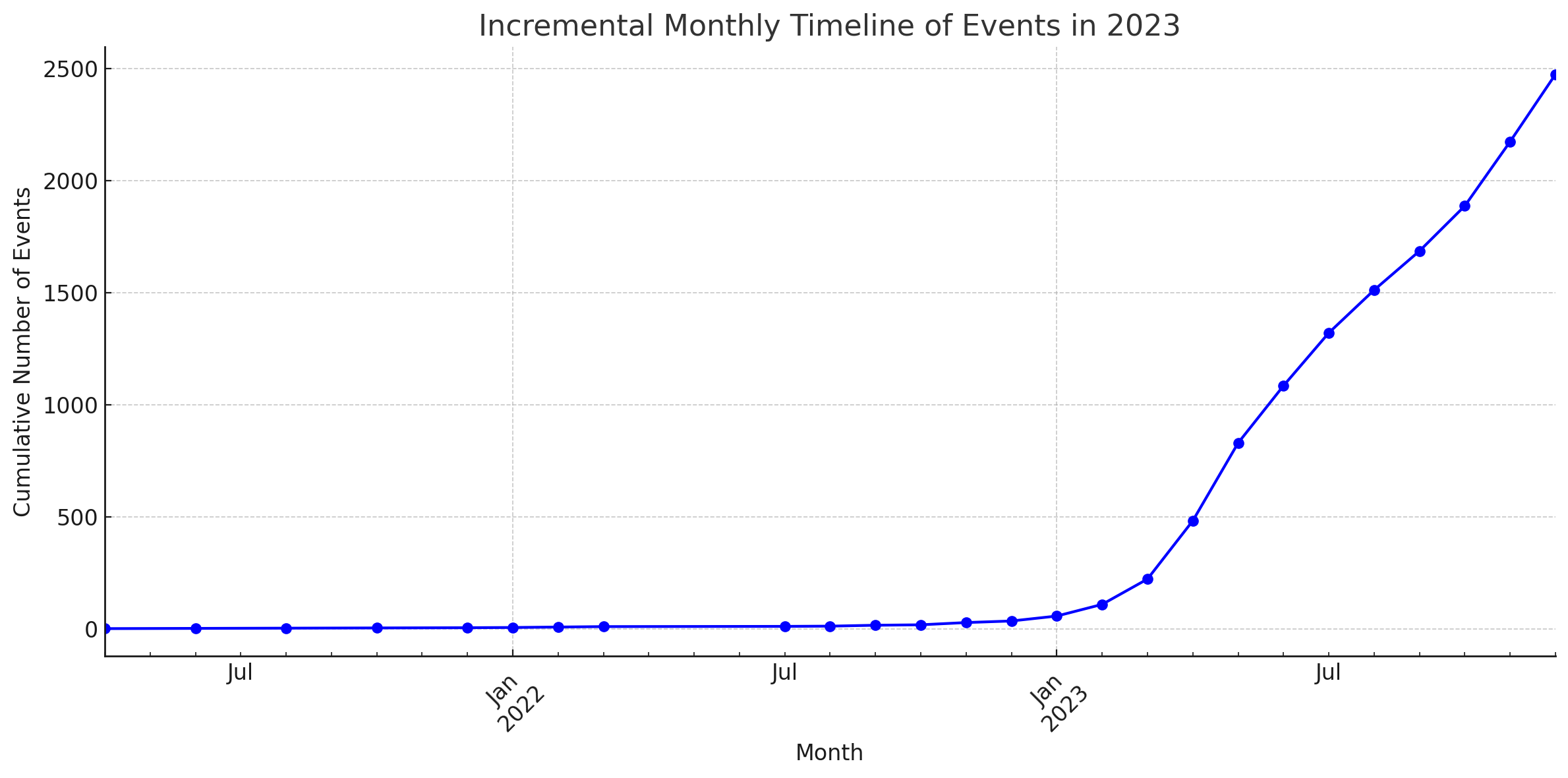
統計數據
這些圖表是由 ChatGPT 的程式碼解釋器產生的。
貢獻
非常感謝問題和請求請求。如果您之前從未為開源專案做出貢獻,我非常樂意引導您完成如何建立拉取請求。
您可以先打開一個問題來描述您想要解決的問題,我們將從那裡開始。
表情符號
arXiv ,PDF ?
執照
本文檔已獲得 MIT 許可 © Jonghong Jeon(전종홍)
時間軸V2
2024年
- 05/17 - OpenAI 與 Reddit 達成協議,在你的貼文上訓練其人工智慧
(訊息), - 05/17 - OpenAI 解散了專注於長期人工智慧風險的團隊,距離宣布這一消息不到一年
(訊息), - 05/17 -關於高階人工智慧安全性的國際科學報告
(部落格), - 05/16 - TRANSIC:透過線上修正學習從模擬到真實的策略轉移
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 - Toon3D:從新角度看卡通
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 -測試基於人工智慧的大語言模型從科學文獻中提取生態資訊的可靠性
(訊息), - 05/16 -多模態基礎模型中的多鏡頭情境學習
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 -如何在為時已晚之前暫停人工智慧
(訊息), - 05/16 - DINO 1.5 基礎:推進開放集物體偵測的“邊緣”
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 - GPT 商店挖掘與分析
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 - Dual3D:利用雙模式多視圖潛在擴散實現高效一致的文本到 3D 生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 - Chameleon:混合模態早期融合基礎模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 - CAT3D:使用多視圖擴散模型在 3D 中建立任何內容
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/15 - Xmodel-VLM:多模態視覺語言模型的簡單基線
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/15 - LoRA 學得少,忘記得少
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/15 -谷歌的隱形人工智慧水印將有助於識別生成文字和視頻
(訊息), - 05/15 - Google I/O 2024:一切已公佈
(部落格), - 05/15 - BEHAVIOR Vision Suite:透過模擬產生可自訂的資料集
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/15 - ALPINE:揭示語言模型中自回歸學習的規劃能力
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 -了解線上和離線對齊演算法之間的效能差距
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 - SpeechVerse:大規模通用音訊語言模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 - SpeechGuard:探索多模態大語言模式的對抗穩健性
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 -沒有時間可以浪費:將時間擠入行動視訊理解管道
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 - Hunyuan-DiT:強大的多解析度擴散變壓器,具有細粒度的中文理解
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 -使用密集 Blob 表示的組合文字到圖像生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 -超越縮放定律:透過關聯記憶體了解變壓器效能
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/13 - SambaNova SN40L:透過資料流和專家組合擴展 AI 記憶體牆
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/13 - RLHF 工作流程:從獎勵建模到線上 RLHF
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/13 - Plot2Code:用於評估科學繪圖程式碼產生中的多模態大型語言模型的綜合基準
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/13 - OpenAI 推出最新人工智慧模型 GPT-4o
(訊息), - 05/13 - MS MARCO Web 搜尋:包含數百萬個真實點擊標籤的大規模資訊豐富的 Web 資料集
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/13 -有多少研究是由大型語言模型所寫的?
(部落格), - 05/13 -你好 GPT-4o
(部落格), - 05/13 - Coin3D:透過代理引導條件產生可控且互動的 3D 資產
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/11 - Piccolo2:具有多任務混合損失訓練的通用文字嵌入
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/11 - LogoMotion:內容感知動畫的視覺基礎程式碼生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/10 - INSPECT - 用於大型語言模型評估的開源框架
(部落格), - 05/10 - AI安全研究所發布新的AI安全評估平台
(訊息), - 05/07 - SUTRA:可擴展的多語言語言模型架構
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/07 - Meta 發布 Llama 3 開源 LLM
(訊息), - 05/03 -建構視覺語言模型時什麼最重要?
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 - WildChat:1M ChatGPT 野外互動日誌
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 - StoryDiffusion:用於長距離影像和影片生成的一致自註意力
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 - Prometheus 2:專門用於評估其他語言模型的開源語言模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 - NeMo-Aligner:用於高效能模型對齊的可擴展工具包
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 - LLM-AD:基於大型語言模型的音訊描述系統
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 - FLAME:大型語言模型的事實感知對齊
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 -使用單一圖像對自訂文字到圖像模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/01 -具有神經補償的光譜修剪高斯場
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/01 -語言模型對齊的自玩偏好優化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/01 -編輯批量大小越大越好嗎? -- Llama-3模型編輯的實證研究
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/01 - Clover:使用順序知識進行回歸輕量級推測解碼
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/01 -仔細檢查大型語言模型在小學算術的表現
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 -視覺事實檢視器:實現高保真詳細字幕生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - STT:使用 Transformers 實現自動駕駛狀態追蹤
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - SemantiCodec:適用於一般聲音的超低位元率語義音訊編解碼器
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - Octopus v4:語言模型圖
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - MotionLCM:透過潛在一致性模型產生即時可控運動
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - MicroDreamer:透過基於分數的迭代重建在 sim20 秒內實現零樣本 3D 生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - Lightplane:神經 3D 場的高度可擴展組件
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - KAN:柯爾莫哥洛夫-阿諾德網絡
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 -迭代推理偏好優化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 -隱形縫合:透過深度修復產生平滑的 3D 場景
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - InstantFamily:零樣本多 ID 影像產生的屏蔽注意力
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - GS-LRM:3D 高斯潑濺的大型重建模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 -一夜之間將 Llama-3 的上下文擴展十倍
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - DOCCI:連接和對比影像的描述
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 -透過多標記預測更好更快的大型語言模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/29 - Stylus:擴散模型的自動適配器選擇
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/29 - SAGS:結構感知 3D 高斯潑濺
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/29 -用陪審團取代法官:用不同模型小組評估法學碩士一代
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/29 - NIST AI RMF 生成式人工智慧簡介
(訊息), - 04/29 - LoRA Land:310 個可與 GPT-4 競爭的微調 LLM,技術報告
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/29 -袋鼠:透過雙重提前退出進行無損自推測解碼
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/29 -雙子座模型在醫學中的能力
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/28 - Inpaint 繪製:學習透過先刪除影像物件來新增影像對象
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/28 - LEGENT:實體代理的開放平台
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/27 - Ag2Manip:透過與代理無關的視覺和動作表示學習新的操作技能
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/26 - MaPa:用於 3D 形狀的文本驅動的真實感材質繪畫
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/26 - BlenderAlchemy:使用視覺語言模型編輯 3D 圖形
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - Tele-FLM 技術報告
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - SEED-Bench-2-Plus:透過富含文字的視覺理解對多模式大型語言模型進行基準測試
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 -使用 Gecko 重新審視文字到圖像評估:關於指標、提示和人類評級
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - PLLaVA:從影像到影片的無參數 LLaVA 擴展,用於視訊密集字幕
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 -讓你的法學碩士充分利用環境
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 -逐一列出計畫:多模式法學碩士的新資料來源與學習範式
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 -層跳躍:啟用提前退出推理和自推測解碼
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - Interactive3D:透過互動式 3D 產生創建您想要的內容
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 -我們離 GPT-4V 還有多遠?透過開源套件縮小與商業多式聯運模式的差距
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - ConsolidatedID:具有多模式細粒度身分保留的肖像生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - XC-Cache:交叉參與快取上下文以實現高效的 LLM 推理
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 -高階人工智慧助理的道德規範
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - PuLID:透過對比對齊進行 Pure 和 Lightning ID 定制
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - NeRF-XL:使用多個 GPU 擴充 NeRF
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - MotionMaster:用於視訊生成的免訓練相機運動傳輸
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - MoDE:透過叢集獲得 CLIP 資料專家
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - MMT-Bench:用於評估面向多任務 AGI 的大型視覺語言模型的綜合多模態基準
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - MaGGIe:蒙面引導漸進人體實例摳圖
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - ID-Aligner:透過獎勵回饋學習增強身分保護文字到圖像的生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 -用於可控合成的可編輯影像元素
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - CatLIP:CLIP 等級視覺辨識精準度,網路規模影像文字資料預訓練速度提高 2.7 倍
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - BASS:批量注意力優化推測採樣
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/23 - Transformers 可以表示 n-gram 語言模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/23 - Pegasus-v1 技術報告
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/23 -多頭專家混合
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/23 - FlashSpeech:高效率的零樣本語音合成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 - SnapKV:法學碩士在一代之前就知道你在尋找什麼
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 - SEED-X:具有統一多粒度理解和產生的多模態模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 -場景座標重建:透過重新定位器的增量學習來擺出影像集合的姿勢
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 - Phi-3 技術報告:手機本地功能強大的語言模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 - OpenELM:具有開源訓練和推理框架的高效語言模型系列
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 - MultiBooth:從文字生成圖像中的所有概念
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 -學習 H-Infinity 運動控制
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 -低位量化 LLaMA3 模型有多好?實證研究
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 -調整您的步驟:優化擴散模型中的取樣計劃
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 -多模式自動解釋代理
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/21 - Hyper-SD:高效影像合成的軌跡分段一致性模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/21 - AdvPrompter:法學碩士的快速自適應對抗性提示
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/20 -音樂一致性模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 -指令層級結構:訓練法學碩士優先考慮特權指令
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 - TextSquare:擴大以文字為中心的視覺指令調整
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 - PhysDreamer:透過視訊產生與 3D 物件進行基於物理的交互
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 - LLM-R2:大型語言模型增強型基於規則的重寫系統,用於提高查詢效率
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 -真實有多真實?無限制對抗性例子的人類評估框架
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 -實用的功能級程式修復能走多遠?
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 - Groma:用於基礎多模態大型語言模型的在地化視覺標記化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 - Gaussian Splatting 需要 SFM 初始化嗎?
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 - AutoCrawler:用於產生網路爬蟲的漸進式理解網路代理
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - TriForce:透過分層推測解碼無損加速長序列生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 -透過想像、搜尋和批評實現法學碩士的自我完善
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 -重複使用您的獎勵:零樣本跨語言對齊的獎勵模型轉移
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - Reka Core、Flash 和 Edge:一系列強大的多模式語言模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - OpenBezoar:小型、經濟高效且開放的模型,經過混合指令資料訓練
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - MeshLRM:高品質網格的大型重建模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 -推出 MLCommons 的 AI 安全基準 v0.5
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 -介紹 Meta Llama 3:迄今為止最有能力的公開法學碩士
(部落格), - 04/18 - EdgeFusion:裝置上文字到影像生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - BLINK:多模態大型語言模型可以看到但無法感知
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - AniClipart:帶有文字到影片先驗的剪貼畫動畫
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/17 - MoA:個人化影像生成中主題情境解開的混合注意力
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/17 - FlowMind:使用法學碩士自動產生工作流程
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/17 -動態版面:讓文字栩栩如生
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/17 -穩定 Diffusion 3 API 現已推出
(推特)、(部落格)、(示範)、 - 04/16 - VASA-1:即時產生逼真的音訊驅動的說話面孔
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/16 -美國商務部長吉娜·雷蒙多宣布擴大美國人工智慧安全研究所領導團隊
(訊息), - 04/16 -具有潛在擴散的長格式音樂生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/15 -法學碩士評估者認可並偏愛自己的一代人
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/15 - Video2Game:來自單一影片的即時、互動式、逼真且瀏覽器相容的環境
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/15 - Tango 2:透過直接偏好優化調整基於擴散的文字到音訊生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/15 -馴服神經輻射場修復的潛在擴散模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/15 - Opus 可以作為圖靈機運行
(嘰嘰喳喳), - 04/15 - MathGPT:利用 Llama 2 創造高度個人化學習的平台
- 04/15 - HQ-Edit:用於基於指令的影像編輯的高品質資料集
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/15 - Ctrl-Adapter:一種高效且多功能的框架,用於使各種控制適應任何擴散模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/15 -壓縮線性代表智能
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/15 - CompGS:透過壓縮高斯潑濺進行高效 3D 場景表示
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/14 - TextHawk:探索多模態大語言模型的高效細粒度感知
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/13 - Cathie Wood 透過新的 OpenAI 股票推動 ChatGPT 繁榮
(訊息), - 04/12 -擴展(縮小)CLIP:資料、架構和訓練策略的綜合分析
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/12 -探索視覺基礎模型的 3D 意識
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/12 -使用更少的代幣預訓練小型 LM
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/12 -關於低階視覺任務的語言指導的穩健性:深度估計的發現
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/12 - MonoPatchNeRF:透過基於補丁的單目引導改善神經輻射場
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/12 - Megalodon:高效的法學碩士預訓練和無限上下文長度的推理
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/12 - ChatGPT 正在改變學者的寫作風格嗎?
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/12 - COCONut:現代化 COCO 分割
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/12 - AI 晶片將能源預算削減了 99% 以上
(訊息), - 04/12 - AdapterSwap:透過資料刪除和存取控制保證對法學碩士進行持續培訓
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/12 - Grok-1.5 視覺預覽
(演示), - 04/12 -好的、壞的和人道徽章
(訊息), - 04/12 -付費 ChatGPT 用戶現在可以存取 GPT-4 Turbo
(推特)、(新聞)、、() - 04/11 -人工智慧審計標準委員會的必要性
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/11 -記住 Transformer 進行持續學習
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 -亞馬遜將人工智慧領域的領導者吳恩達 (Andrew Ng) 納入董事會
(訊息), - 04/11 - Adobe 以每分鐘 3 美元的價格購買影片來建立 AI 模型
(訊息), - 04/11 - UltraEval:為法學碩士提供靈活、全面評估的輕量級平台
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/11 -開放詞彙分割的可轉移和原則效率
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/11 - SWE 代理
(推特)、(示範)、、() - 04/11 -稀疏車道形成者
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - Rho-1:並非所有代幣都是您所需要的
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/11 - ResearchAgent:利用大型語言模型對科學文獻進行迭代研究想法生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - RecurrentGemma:超越 Transformers 以實現高效率的開放語言模型
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - OSWorld:真實電腦環境中開放式任務的多模式代理程式基準測試
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - LLoCO:離線學習長上下文
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 -利用大型語言模型 (LLM) 支援人類與人工智慧協作線上風險資料註釋
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - JetMoE:以 10 萬美元實現 Llama2 效能
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) (項目), (twitter), , (✳️), () - 04/11 - HGRN2:具有狀態擴展的門控線性 RNN
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/11 -從單字到數字:當給出上下文範例時,您的大型語言模型實際上是一個有能力的回歸器
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - Ferret-v2:改進的大型語言模型參考和基礎基線
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - ControlNet++:透過高效率的一致性回饋改善條件控制
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 -長期資料集中的上下文感知視訊異常檢測
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - ChatGPT-3.5,Claude 3 在法學碩士街頭霸王 III 錦標賽中踢像素化屁股
(訊息), - 04/11 - ChatGPT 講述關於過去的未來故事時可以預測未來
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 -語言模型合成資料的最佳實踐和經驗教訓
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 -透過《街頭霸王 3》中的戰鬥來衡量法學碩士的基準
(演示), , () - 04/11 -音訊對話:用於音訊和音樂理解的對話資料集
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 -在有限的時間間隔內應用指導可提高擴散模型中的樣本和分佈質量
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - AmpleGCG:學習通用且可轉移的對抗性後綴生成模型,用於越獄開放式和封閉式法學碩士
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/10 - LM Transparency Tool:用於分析 Transformer 語言模型的互動式工具
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - Gemini 1.5 Pro 現在可以理解音訊
(嘰嘰喳喳), - 04/10 -探索概念深度:大型語言模式如何獲得不同層的知識?
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/10 -城市建築師:具有佈局優先的可操縱 3D 城市場景生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - RealmDreamer:具有修復和深度擴散的文本驅動 3D 場景生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 -報告稱,OpenAI 和 Meta 即將發布能夠像人類一樣推理的人工智慧模型
(訊息), - 04/10 - MetaCheckGPT-使用 LLM 不確定性和元模型的多任務幻覺偵測器
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - Meta 確認其 Llama 3 開源 LLM 將於下個月推出
(訊息), - 04/10 -不留任何上下文:具有無限注意力的高效無限上下文轉換器
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 -增量 XAI:透過增量解釋對 AI 進行令人難忘的理解
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - DreamScene360:使用全景高斯潑濺產生無約束文字到 3D 場景
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 -麻婆豆腐含有咖啡嗎?探索法學碩士的食品相關文化知識
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - BRAVE:拓寬視覺語言模型的視覺編碼
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - AI 新創公司 Mistral 推出 281GB AI 模型,與 OpenAI、Meta 和 Google 競爭
(訊息), - 04/10 -用於遠端監控的代理驅動的生成語義通信
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 -使 LLaMA 解碼器適應 Vision Transformer
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 -關於生成式人工智慧在行動網路中整合批判性思維的調查
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 -看看吧!重新思考如何評估語言模式越獄
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 - RULER:您的長上下文語言模型的真實上下文大小是多少?
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 -修改高斯潑濺中的緻密化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 -以 3D 方式重建手持物體
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 - RAR-b:推理作為檢索基準
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 -隱私保護提示工程:調查
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 -關於評估法學碩士產生的源代碼的效率
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/09 - OmniFusion 技術報告
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 - MuPT:生成符號音樂預訓練 Transformer
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 - MiniCPM:透過可擴展的訓練策略揭示小語言模型的潛力
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 - Magic-Boost:透過多視圖條件擴散增強 3D 生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 - LLM2Vec:大型語言模型是秘密強大的文字編碼器
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 - InternLM-XComposer2-4KHD:開創性的大型視覺語言模型,可處理從 336 像素到 4K 高清的分辨率
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 - Hash3D:3D 產生的免訓練加速
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 -Google推出產生人工智慧開源項目
(訊息), - 04/09 -大象永遠不會忘記:大型語言模型中表格資料的記憶和學習
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 - Apple 剛剛推出了新的 Ferret-UI LLM - 這個 AI 可以讀取你的 iPhone 螢幕
(訊息), - 04/09 - AEGIS:法學碩士專家團隊的線上自適應人工智慧內容安全審核
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/08 - YaART:另一種 ART 渲染技術
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/08 - WILBUR:用於穩健且準確的網路代理的自適應上下文學習
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/08 - UniFL:透過統一回饋學習提高穩定擴散
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/08 -肆無忌憚的伊卡洛斯:多模態大語言模型安全中影像輸入的潛在危險調查
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/08 -幻覺排行榜——在大型語言模型中測量幻覺的公開努力
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/08 -基於 LLM 的程式修復中的事實選擇問題
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/08-交換:在個人化的視覺編輯中啟用任意物件交換
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/08- sambalingo:教大語模型新語言
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/08-負偏好優化:從災難性崩潰到有效的學習
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/08- NAVER首次亮相多語言HyperClova X LLM將用於為亞洲建立主權AI
(訊息), - 04/08- MOMA:快速個人化影像產生的多模式LLM適配器
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/08 -MEDEXPQA:大型語言模型的多語言基準測試
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/08- MA-LMM:記憶揚名的大型多模式,用於長期視訊理解
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/08- layoutllm:使用大型語言模型的佈局指令調整以供文件理解
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/08 -ferret -UI:具有多模式LLM的接地移動UI理解
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/08-評估大語言模型的介入推理能力
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/08-鷹和芬奇:帶有矩陣值態和動態復發的RWKV
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/08-編解碼器:與量身定制的合成資料對齊語言模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/08-自動編碼器:自主程序改進
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/07-負載預測中的時間段:一個大的時間序列模型透視圖
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/07- OpenAI在一百萬小時的YouTube影片中轉錄訓練GPT -4
(訊息), - 04/07-魔術:延時視訊生成模型作為變質模擬器
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/07-比teedit:提升,遵守與加速生成影像編輯
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/06-醫生的多數投票提高了人工智慧對病理的適當性
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss) - 04/06-擴散-RWKV:擴散模型的縮放RWKV類架構
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/06- Datenerf:nerfs的深度感知文字編輯
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/06-超越:以預處理擴散的高解析度以人為中心的場景產生
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/06-透過優化人類實用程式來對齊擴散模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/06-發展從頭開始規劃式任務的基礎模型的情況
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/05-透過微調和量化增加了LLM漏洞
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/05-空間拖車:在3D空間中追蹤任何2D像素
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/05-大語言模型的社交技能培訓
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/05 -Sigma:用於多模式語義分段的暹羅山網絡
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/05-強大的高斯裂開
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/05 -Physavatar:從視覺觀察中學習穿著3D頭像的物理學
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/05- Koala:鑰匙幀條件的長視頻-LLM
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/05-線索:LLMS的臨床語言理解評估
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/05-中文小法學碩士:以中文為中心的大語言模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/05-協助人類進行複雜的比較:自動化資訊比較
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04-帶有兩個手臂的AI體現:零射擊學習,安全性和模組化
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss) - 04/04-語言模型演進:迭代學習觀點
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04-在大語言模型中可視化的想法引起空間推理
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(twitter),(twitter),(twitter), (twitter), - 04/04-沒有指數資料的沒有「零射」:概念概念頻率決定了多模型模型效能
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/04-在偵測LLM回應中的錯誤時評估LLM
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/04-評估資訊擷取中的生成語言模型作為主觀問題更正
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/04-直接NASH最佳化:教授語言模型,以自我興起一般的偏好
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04- CBR-RAG:基於案例的推理,用於檢索LLMS的法律問題回答
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04-控制工程中大語言模型的功能:GPT -4,Claude 3 Opus和Gemini 1.0 Ultra的基準研究
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04- cantTalkaboutthis:對齊語言模型以對話中的話題
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04- autowebglm:引導和加強基於語言模型的大型網路導航代理
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/04-神經壓迫文本的訓練LLM
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04- reft:語言模型的表示列表
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/04-紅色團隊GPT-4V:GPT-4V是否安全抵抗Uni/多模式越獄攻擊?
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04- RALL-E:使用經過三鏈鏈的穩健編解碼語言建模提示文字到語音綜合
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04-點Infinity:解析度為Invariant點擴散模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04- Minigpt4-Video:使用交織的視覺文字代幣進行視訊理解的多模式LLM
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04-昏迷:與圖像到文字概念相符的文字對圖像擴散模型對齊
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04- CodeedOtorBench:評估大語模型的程式碼編輯功能
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/04- autowebglm:引導和加強基於語言模型的大型網路導航代理
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/03-視覺自迴旋建模:透過暫時預測可擴展影像生成
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/03-關於基於擴散的文本對圖像生成的可擴展性
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/03-許多越獄
() - 04/03- lvlm-intrepret:用於大型視覺模型的可解釋性工具
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/03-語言模型作為編譯器:模擬偽代碼執行改善語言模型中的演算法推理
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/03- InstantStyle:在文字到圖像中免費提供午餐
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/03 -Freditor:高保真度和可轉移的NERF透過頻率分解編輯
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/03-跨注意力使推理在文字到圖像擴散模型中麻煩
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/03- ChatGlm-Math:使用自我批評的管道改善大型語言模型的數學解決問題
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/02-英國和美國宣布AI安全科學夥伴關係
(訊息), - 04/02-大型語言模型作為計劃域生成器
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss) - 04/02 -Poro 34B和多語言的祝福
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/02-章魚V2:超級代理的設備語言模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/02-詳細資訊的混合:在基於變壓器的語言模型中動態分配計算
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/02- Long-context LLM與長期內在學習鬥爭
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/02 -LLM -ABR:透過大語言模型設計自適應位元率演算法
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/02-大型語言模型可能會改變行為醫療保健的未來:負責任的發展和評估的建議
() - 04/02 -HyperClova X技術報告
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/02- CAMERACTRL:啟用攝影機控製文字到視訊生成
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/02-推進LLM推理通才的偏好樹
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/01-搜尋流(SOS):學習語言搜尋
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/01 -LLM作為策劃者:大語言模型的策略推理調查
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/01- AI大語言模型(LLM)的興起與崛起
(部落格), - 04/01-串流媒體密集的視訊字幕
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/01-擴散模型中的測量樣式相似性
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/01-正確正確:提高文字對影像模型的空間一致性
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/01-對於資料策劃的AI公司,網路太小
(訊息), - 04/01- flexidreamer:flexicubes的單一影像到3D生成
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/01-評估:大語言模型評估的統一且可訪問的庫
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/01-從語言模型獎勵直接優化視訊大型多模型模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 04/01 -DBRX,持續預處理,獎勵台,推理速度更快,更多
(部落格), - 04/01- Cosmicman:人類的文本對圖像基礎模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/01-可控影像生成的條件感知神經網絡
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/01-較大並不總是更好:潛擴散模型的縮放屬性
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 04/01-大語言模型是超人化學家嗎?
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/31 -WAVLLM:邁向強大且自適應的語音大語言模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/31-厭倦了插件?大型語言模型可以是端到端的推薦人
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/30-關於大語言模型增強強化學習的調查:概念,分類和方法
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/30 -ST -LLM:大語言模型是有效的臨時學習者
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss) - 03/30-佈局意識語言模型的噪音感知培訓
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/30 -Magritte:從圖像,topview和文字實現的操縱和生成3D實現
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss) - 03/30- Aurora-M:根據美國行政命令,第一個開源的多語言模型紅色電池
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/29-無法解決的問題偵測:評估視覺語言模型的可信度
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/29-變形金屬:在手機GPU上大型語言模型的高效部署
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/29- snap-it,tap-it,splat-it:觸覺的3D高斯脫衣舞,用於重建挑戰性的表面
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/ 29-領域:參考解析度作為語言建模
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/29 -NVIDIA H200 GPU CRUSS MLPERF的LLM推論基準測試
(訊息), - 03/29 -Mambamixer:具有雙令牌和頻道選擇的有效選擇性狀態空間模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/29- llava -gemma:具有緊湊語言模型的加速多模式基礎模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/29- Instantsplat:無界稀疏 - 視圖無姿勢無姿勢的高斯裂口在40秒內
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/29 -Gecko:從大語模型蒸餾出的多功能文本嵌入式
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/29 -Dijiang:透過緊湊的內核化有效的大型語言模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/29- DeepMind開發安全,這是一個基於AI的應用程序,可以檢查事實 - 檢查LLMS
(訊息), - 03/29 -CTRL -SIM:具有離線增強學習的反應性和可控駕駛劑
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/29-我們是否採取正確的方式評估大型視覺模型?
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/28 -SDPO:不要一次使用您的數據
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/28 -MESH2NERF:直接網格監督神經輻射場表示和發電
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/28-語言模型中的在地化段落記憶
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/28 -JAMBA:混合變壓器 - 曼巴語模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/28 -GaussianCube :使用最佳傳輸進行3D生成建模的構造高斯裂縫
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/28 -Claude 3在AI機器人的決鬥中超過GPT -4。這是採取行動的方法
(訊息), - 03/28-宣布Grok -1.5
(部落格),(示範), - 03/27-通往法律自主權的途徑:一種可互操作和可解釋的方法,用於使用大語言模型,專家系統和貝葉斯網絡提取,轉換,加載和計算法律信息
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/27- VITAR:具有任何解析度的視覺變壓器
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/27-邁向一個世界英語語言模型,用於設備虛擬助手
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/27 -TextCraftor:您的文字編碼器可以是影像品質控制器
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/27- objectDrop:bootstage formerantic物件刪除和插入的反事實
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/27- Mini-Gemini:挖掘多模式視覺語言模型的潛力
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/27-大語言模型中的長期事實
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/27- LITA:語言指示的時間安置助手
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/27 -GARMENT3DGEN:3D服裝風格與紋理生成
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/27 -GAMBA:與Mamba結婚以獲得單視3D重建
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/27-彈性:靈活且可控制的基於物件以物件為基礎的影像編輯
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/27 -BiomedLM:2.7b參數語言模型在生物醫學文本上訓練
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/26- MAGIS:基於LLM的GITHUB發行的多代理框架分辨率
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/26-更深層的無效性無效
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/26- TC4D:軌跡條件的文字到4D代
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/26- OCTREE-GS:朝向LOD結構3D高斯人持續即時渲染
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/26-介紹DBRX:新的最新開放式LLM
(部落格), - 03/26 -InternLM2技術報告
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/26-透過自動提示優化改善文字對影像一致性
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/26-英特爾資料中心上的完全融合的多層感知器GPU
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/26- egolifter:以自我感知的開放世界3D細分
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/26 -AniporTrait:光真逼真的肖像動畫的音訊驅動的合成
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/26- 2D高斯分裂,用於幾何準確的輻射場
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/25-朝向LLMS的臨床能力自動評估:度量,數據和演算法
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/25-維修:一種自主,基於LLM的程序維修代理
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/25- RL用於一致性模型:更快的獎勵引導文字對影像生成
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/25- VP3D:釋放2D視覺提示,以取得文字到3D
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/25-旅行:影像到視訊擴散模型的影像雜訊的時間殘差學習模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/25- SDXS:具有影像條件的即時單步潛擴散模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/25 -LLM代理作業系統
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/25-閃存面:具有高保真身份保護的人類形象個性化
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/25- Dreampolisher:透過幾何擴散邁向高品質的文本到3D代
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/25-做自己:多主題文字對圖像生成的關注
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/23-基於LLM的程式碼產生符合軟體開發流程時
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/22-主題:從幾個範例中產生主題感知的3D資產
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/22 -SIMBA:簡化的基於MAMBA的架構,用於視覺和多元時間序列
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/22 -LLM2LLM:透過新穎的迭代資料增強來增強LLM
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/22- LATTE3D:大規模攤銷的文本到增強3D合成
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/22- InternVideo2:用於多模式視訊理解的縮放視訊基礎模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/22-關注:評估和教學資訊檢索模型以遵循說明
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/22- dragapart:在鉸接對象的事先學習零件級運動
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/22-大型語言模型可以探索中文嗎?
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/22- Allhands:透過大型逐字回饋透過大語言模型問我任何東西
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss) - 03/21- peergpt:探討基於LLM的同儕代理人作為團隊主持人和參與者在兒童協作學習中的角色
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/21- Stylecinegan:使用預先訓練的Stylegan的景觀電影院
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/21- streamingt2v:一致,動態和可擴展的長視頻生成從文本中
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/21- renoise:透過迭代陳述的真實影像反轉
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/21-填海的追索:與生成語言模型聊天
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/21 -Rakutenai -7B:擴展日語的大型語言模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/21 -MYVLM:個人化使用者特定查詢的VLM
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/21-數學:您的多模式LLM是否真正看到視覺數學問題中的圖表?
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/21 -GRM:高效3D重建與生成的大型高斯重建模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/21-大會採用具有里程碑意義的人工智慧決議
(訊息), - 03/21-高斯糖霜:帶有即時渲染的可編輯複雜的輻射場
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/21-探索時間與空間的探索性過程
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/21-透過內容 - 框架運動線子分解有效的視訊擴散模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/21- Dreamreward:文本到3d的人類偏好
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/21 -COBRA:將Mamba擴展到多模式的大型語言模型以提高推理
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/21-冠軍:具有3D參數指導的可控且一致的人類影像動畫
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/21- ANYV2V:任何影片到影片編輯任務的插件和播放框架
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/20-映射LLM安全景觀:一項全面的利益相關風險評估建議
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/20 -Zigma:鋸齒形mamba擴散模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/20 -VSTAR:更長的動態視訊綜合的生成時間護理
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/20-獎勵基地:評估語言建模的獎勵模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/20-反向訓練以護理逆轉詛咒
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/20- radsplat:radiance田間資訊高斯拆卸,用於使用900+ fps的穩健即時渲染
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/20 -MORA:透過多代理框架啟用通才視頻
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/20 -LlamaFactory:100多種語言模型的統一有效微調
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/20- IDADAPTER:學習用於文字物件模型的無調個人化的混合功能
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/20 -Hyperlava:多模式模型的動態視覺和語言專家調整
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/20-評估邊境模型的危險功能
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/20 -DEPTHFM:流量匹配的快速單眼估計
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/20 -Compress3D:從單一影像中的3D產生的壓縮潛在空間
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/20- Be-Your-OutPainter:透過特定於輸入的適應來掌握影片的主修
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/19-什麼時候我們不需要更大的視力模型?
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/19- VID2ROBOT:端到端視訊條件的政策學習,跨意義變形金剛
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/19-邁向計算病理的通用基礎模型
() - 03/19- TexDreamer:朝零射擊高保真3D人紋理產生
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/19-場景標題:使用自回歸結構化語言模型重建場景
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/19- mplug-docowl 1.5:無OCR文檔理解的統一結構學習
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/19-魔術修復:透過觀看動態影片來簡化照片編輯
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/19- llmlingua-2:高效和忠實的任務不合時宜的提示壓縮的數據蒸餾
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/19- GVGEN:具有體積表示形式的文字到3D生成
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/19 -GaussianFlow:4D內容所創造的Gaussian動力學
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/19- fresco:零拍影片翻譯的時空通信
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/19-四台:無訓練高解析度影像合成的頻率觀點
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/19-模型合併食譜的演化優化
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),([:contocat :](https) ://github.com/ sakanaai/evolutionary-model-merge)! [github repo stars](https://img.shields.io/github/github/stars/ sakanaai/ sakanaai/ evolutionary-model -merge? - 03/19-組合:使用空間感知擴散指導創建組成3D資產
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/19-基於圖表的推理:將功能從LLMS轉移到VLMS
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/19 -Apple的MM1:一種多式模式的大型語言模型,能夠解釋圖像和文字數據
(訊息), - 03/19-動畫儀:跨模型擴散蒸餾
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/19 -Agent -Flan:設計大語模型的有效代理調整的資料和方法
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/19-計算病理學的視覺語言基礎模型
(),(✳️) - 03/19-透過大語言模型的特徵AI代理
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/18-我們在LLM的決策上有多遠?評估LLMS在多代理環境中的遊戲能力
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/18-視訊:一種用於視訊理解的記憶體啟動的多模式代理
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/18 -VFusion3D:從視訊擴散模型中學習可擴展的3D生成模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/18 -TNT -LLM:大規模的文本挖掘與大語言模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/18 -SV3D:使用潛在視訊擴散從單一影像發出新穎的多視圖合成和3D生成
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/18 -Routerbench:多LLLM路由系統的基準
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),(ss) - 03/18-使用LLMS自動化零攝影視覺辨識的元啟動
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/18 -LN3DIFF:可擴展的潛在神經場擴散3D代
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/18- llava-uhd:lmm感知任何縱橫比和高解析度影像
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(ss),(✳️),() - 03/18 -LARIMAR:具有情節記憶控制的大語言模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/18- Infinite-ID:透過ID-Semantics脫鉤範式保存身分的個人化
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/18 -GPT -4作為評估者:評估農業害蟲管理的大型語言模型
(),(),(?),(?),(?),(html),(sl),(sp),(gs),(ss),(✳️) - 03/18 - Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Compiler generated feedback for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - PhD: A Prompted Visual Hallucination Evaluation Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/16 - VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/16 - Do Large Language Models understand Medical Codes?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - VideoAgent: Long-form Video Understanding with Large Language Model as Agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Trusting the Search: Unraveling Human Trust in Health Information from Google and ChatGPT
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - PERL: Parameter Efficient Reinforcement Learning from Human Feedback
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - NeuFlow: Real-time, High-accuracy Optical Flow Estimation on Robots Using Edge Devices
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - MusicHiFi: Fast High-Fidelity Stereo Vocoding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - LightIt: Illumination Modeling and Control for Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Enhancing Human-Centered Dynamic Scene Understanding via Multiple LLMs Collaborated Reasoning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - DiPaCo: Distributed Path Composition
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - WavCraft: Audio Editing and Generation with Natural Language Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Editing via Factorized Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Scaling Instructable Agents Across Many Simulated Worlds
(twitter), (Blog), - 03/14 - Recurrent Drafter for Fast Speculative Decoding in Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - LocalMamba: Visual State Space Model with Windowed Selective Scan
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Helpful or Harmful? Exploring the Efficacy of Large Language Models for Online Grooming Prevention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - GPT on a Quantum Computer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/14 - Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - GiT: Towards Generalist Vision Transformer through Universal Language Interface
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Exploring the Capabilities and Limitations of Large Language Models in the Electric Energy Sector
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - 3D-VLA: A 3D Vision-Language-Action Generative World Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Scaling Instructable Agents Across Many Simulated Worlds
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/13 - VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - The Human Factor in Detecting Errors of Large Language Models: A Systematic Literature Review and Future Research Directions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - SOTOPIA-π: Interactive Learning of Socially Intelligent Language Agents
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Simple and Scalable Strategies to Continually Pre-train Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Scaling Up Dynamic Human-Scene Interaction Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language-based game theory in the age of artificial intelligence
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language models scale reliably with over-training and on downstream tasks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Knowledge Conflicts for LLMs: A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Gemma: Open Models Based on Gemini Research and Technology
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Cultural evolution in populations of Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Bugs in Large Language Models Generated Code: An Empirical Study
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Synth^2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - MoAI: Mixture of All Intelligence for Large Language and Vision Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Learning Generalizable Feature Fields for Mobile Manipulation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - DragAnything: Motion Control for Anything using Entity Representation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Chronos: Learning the Language of Time Series
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Transparent AI Disclosure Obligations: Who, What, When, Where, Why, How
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - HILL: A Hallucination Identifier for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - FAX: Scalable and Differentiable Federated Primitives in JAX
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FashionReGen: LLM-Empowered Fashion Report Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - VideoMamba: State Space Model for Efficient Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - V3D: Video Diffusion Models are Effective 3D Generators
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Stealing Part of a Production Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - Multistep Consistency Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FaceChain-SuDe: Building Derived Class to Inherit Category Attributes for One-shot Subject-Driven Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - Chain-of-table: Evolving tables in the reasoning chain for table understanding (Blog),
- 03/11 - An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/10 - VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/09 - Algorithmic progress in language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - On Protecting the Data Privacy of Large Language Models (LLMs): A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/08 - VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - DeepSeek-VL: Towards Real-World Vision-Language Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/08 - CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Now available on Poe: Claude 3 (Demo),
- 03/08 - Google - Health-specific embedding tools for dermatology and pathology (Blog),
- 03/07 - Yi: Open Foundation Models by 01.AI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Teaching Large Language Models to Reason with Reinforcement Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - StableDrag: Stable Dragging for Point-based Image Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Radiative Gaussian Splatting for Efficient X-ray Novel View Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Pix2Gif: Motion-Guided Diffusion for GIF Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Meet 'Liberated Qwen', an uncensored LLM that strictly adheres to system prompts (News),
- 03/07 - LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - KAIST develops next-generation ultra-low power LLM accelerator (News),
- 03/07 - Inflection-2.5: meet the world's best personal AI (News),
- 03/07 - How Far Are We from Intelligent Visual Deductive Reasoning?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Evaluating LLM models at scale (Blog),
- 03/07 - Common 7B Language Models Already Possess Strong Math Capabilities
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - SaulLM-7B: A pioneering Large Language Model for Law
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - NY hospital exec: Multimodal LLM assistants will create a “paradigm shift” in patient care (News),
- 03/06 - Learning to Decode Collaboratively with Multiple Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - Enhancing Vision-Language Pre-training with Rich Supervisions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Backtracing: Retrieving the Cause of the Query
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - AI Prompt Engineering Is Dead (News),
- 03/06 - 3D Diffusion Policy
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/05 - OpenAI and Elon Musk (Blog),
- 03/05 - Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/05 - WikiTableEdit: A Benchmark for Table Editing by Natural Language Instruction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Updating the Minimum Information about CLinical Artificial Intelligence (MI-CLAIM) checklist for generative modeling research (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Revisiting Meta-evaluation for Grammatical Error Correction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - MathScale: Scaling Instruction Tuning for Mathematical Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Interactive Continual Learning: Fast and Slow Thinking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - In Search of Truth: An Interrogation Approach to Hallucination Detection (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ImgTrojan: Jailbreaking Vision-Language Models with ONE Image (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Generative Software Engineering (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Exploring the Limitations of Large Language Models in Compositional Relation Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Design2Code: How Far Are We From Automating Front-End Engineering? (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Models are Task-specific Classifiers (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 3/5 - OpenAI - ChatGPT can now read responses to you. (嘰嘰喳喳,
- 03/04 - The Claude 3 Model Family: Opus, Sonnet, Haiku
() (twitter), , (✳️) - 03/04 - Wukong: Towards a Scaling Law for Large-Scale Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - Large language models surpass human experts in predicting neuroscience results
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/04 - NoteLLM: A Retrievable Large Language Model for Note Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - MagicClay: Sculpting Meshes With Generative Neural Fields (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/04 - Enhancing LLM Safety via Constrained Direct Preference Optimization (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - CODE-ACCORD: A Corpus of Building Regulatory Data for Rule Generation towards Automatic Compliance Checking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - Balancing Enhancement, Harmlessness, and General Capabilities: Enhancing Conversational LLMs with Direct RLHF (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 3/4 - ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - TripoSR: Fast 3D Object Reconstruction from a Single Image (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - RT-H: Action Hierarchies Using Language (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - Build AI for a Better Future (twitter), (News),
- 3/4 - AtomoVideo: High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 03/03 - Research Papers in February 2024: A LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM Research (Blog),
- 3/3 - Nvidia CEO Jensen Huang says AI could pass most human tests in 5 years (News
- 3/3 - MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - Could this be bigger than OpenAI? Microsoft invests billions in French startup — Mistral AI is a multilingual maestro that's almost as good as ChatGPT 4 (News),
- 3/3 - 3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/2 - Nvidia CEO says AI could pass human tests in five years (News
- 3/1 - Elon Musk sues OpenAI and CEO Sam Altman over contract breach (News)
- 3.1 - AtP*: An efficient and scalable method for localizing LLM behaviour to components (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - VisionLLaMA: A Unified LLaMA Interface for Vision Tasks (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Learning and Leveraging World Models in Visual Representation Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Resonance RoPE: Improving Context Length Generalization of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/29 - OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/29 - Retrieval-Augmented Generation for AI-Generated Content: A Survey (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 2.29 - DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Humanoid Locomotion as Next Token Prediction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - StarCoder 2 and The Stack v2: The Next Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Trajectory Consistency Distillation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - Beyond Language Models: Byte Models are Digital World Simulators (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Syntactic Ghost: An Imperceptible General-purpose Backdoor Attacks on Pre-trained Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - ViewFusion: Towards Multi-View Consistency via Interpolated Denoising (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - MOSAIC: A Modular System for Assistive and Interactive Cooking (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 02/28 - Automatic Creative Selection with Cross-Modal Matching
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 2.28 - Priority Sampling of Large Language Models for Compilers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Simple linear attention language models balance the recall-throughput tradeoff (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.28 - Approaching Human-Level Forecasting with Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Datasets for Large Language Models: A Comprehensive Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.28 - A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - A High Level Guide to LLM Evaluation Metrics (Blog),
- 2/27 - Users Say Microsoft's AI Has Alternate Personality as Godlike AGI That Demands to Be Worshipped (News)
- 2/27 - Google DeepMind CEO on AGI, OpenAI and Beyond – MWC 2024 (News)
- 2.27 - Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Towards Optimal Learning of Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Evaluating Very Long-Term Conversational Memory of LLM Agents (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Training-Free Long-Context Scaling of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - DiffuseKronA: A Parameter Efficient Fine-tuning Method for Personalized Diffusion Model (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora Generates Videos with Stunning Geometrical Consistency (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Video as the New Language for Real-World Decision Making (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - On the Societal Impact of Open Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/26 - Set the Clock: Temporal Alignment of Pretrained Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2/26 - DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models (), ()(?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/26 - Mistral Large is our flagship model, with top-tier reasoning capacities (News)
- 2.26 - Disentangled 3D Scene Generation with Layout Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Multi-LoRA Composition for Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.26 - Do Large Language Models Latently Perform Multi-Hop Reasoning? (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Nemotron-4 15B Technical Report (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - StructLM: Towards Building Generalist Models for Structured Knowledge Grounding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Towards Open-ended Visual Quality Comparison (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.25 - ChatMusician: Understanding and Generating Music Intrinsically with LLM (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.25 - FuseChat: Knowledge Fusion of Chat Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/24 - Divide-or-Conquer? Which Part Should You Distill Your LLM?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/24 - Perplexity.ai Revamps Google SEO Model For LLM Era (News)
- 02/24 - Data Interpreter: An LLM Agent For Data Science
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2.24 - Empowering Large Language Model Agents through Action Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Seamless Human Motion Composition with Blended Positional Encodings (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - Genie: Generative Interactive Environments (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - GPTVQ: The Blessing of Dimensionality for LLM Quantization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.22 - CLoVe: Encoding Compositional Language in Contrastive Vision-Language Models (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️), ()
- 02/22 - Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 2.22 - Divide-or-Conquer? Which Part Should You Distill Your LLM? (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - Watermarking Makes Language Models Radioactive (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - AutoPrompt - prompt optimization framework ()
- 2.22 - Announcing Stable Diffusion 3 (tweet), (blog)
- 2.22 - DualFocus: Integrating Macro and Micro Perspectives in Multi-modal Large Language Models (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - RoboScript: Code Generation for Free-Form Manipulation Tasks across Real and Simulation (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - LLMs with Industrial Lens: Deciphering the Challenges and Prospects -- A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Vision-Language Navigation with Embodied Intelligence: A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Enhancing Robotic Manipulation with AI Feedback from Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - PALO: A Polyglot Large Multimodal Model for 5B People (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion (), (), ([:paperclip:](https://arxiv.org/pdf/2402.148


