meena chatbot
1.0.0
這是我重新創建 Meena 的嘗試,Meena 是由 Google Research 開發的最先進的聊天機器人,並在論文《走向類人開放域聊天機器人》中進行了描述。
對於這個實現,我使用了tensor2tensor深度學習庫,使用了論文中描述的進化變壓器模型。
使用的訓練集是義大利文的 OpenSubtitles 語料庫。這裡還提供許多其他語言。
與論文中所做的工作類似,該模型由 1 個編碼器區塊和 12 個解碼器區塊組成,總共 108M 個參數。使用的優化器是 Adafactor,其訓練速率表與論文中描述的相同。
以下是在 OpenSubtitles 義大利語資料集的 4000 萬個句子上訓練模型後的結果。學習率從 0.01 開始,在 10k 步內保持恆定,然後隨著步數的平方根倒數衰減。
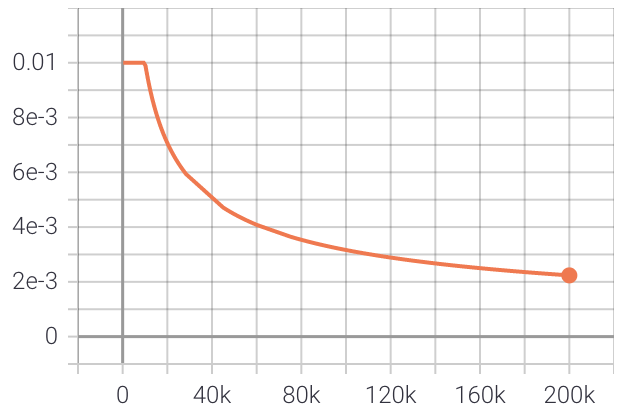
這是訓練期間評估損失的圖。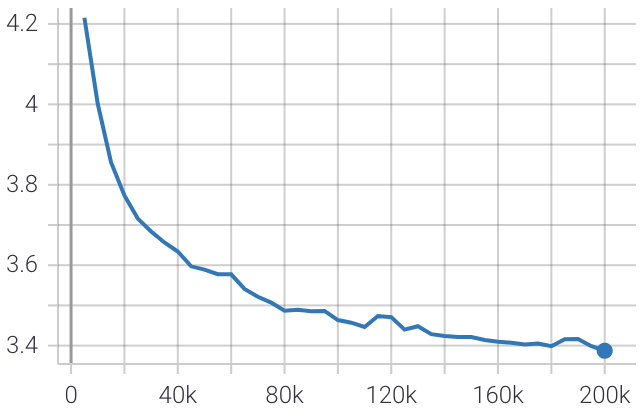
最後的困惑度得分為 10.4 ,非常接近 Google 的meena chatbot所達到的困惑度得分 10.2。
該論文顯示了困惑度分數與敏感度和特異性平均值之間的相關性,該平均值與聊天機器人的「人類相似性」相關。我們的困惑度分數顯示我們的機器人比 Cleverbot 和 DialoGPT 等其他聊天機器人更好: 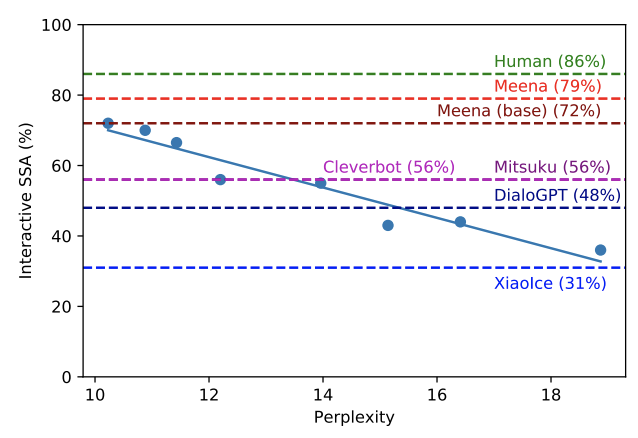
然而,所使用的數據集並不能很好地代表人類之間的正常對話。然而,Opensubtitles 提供了多種語言的非常大的資料集。
只需運行筆記本meena_chatbot_inference.ipynb 。
否則下載以下模型並解壓縮。在predict.py中設定正確的MODEL_DIR和CHECKPOINT_NAME並執行main.py
對於訓練,只需在 Google Colab 上運行 ipython 筆記本,模型將保存在 Google Drive 上。執行結束後,您可以與聊天機器人互動。
可以透過複製資料夾中的以下文件來匯出模型:
並在設定正確的模型目錄後運行main.py 。
server.py提供了一個簡單的 HTTP API 來為聊天機器人提供服務。


