很棒的審計演算法
用於審核黑盒演算法的精選演算法清單。如今,許多演算法(建議、評分、分類)都是在第三方提供者處運行的,用戶或機構對如何操作資料沒有任何了解。因此,此列表中的審核演算法適用於此設置,創造了「黑盒子」設置,其中一名審核員希望深入了解這些遠端演算法。
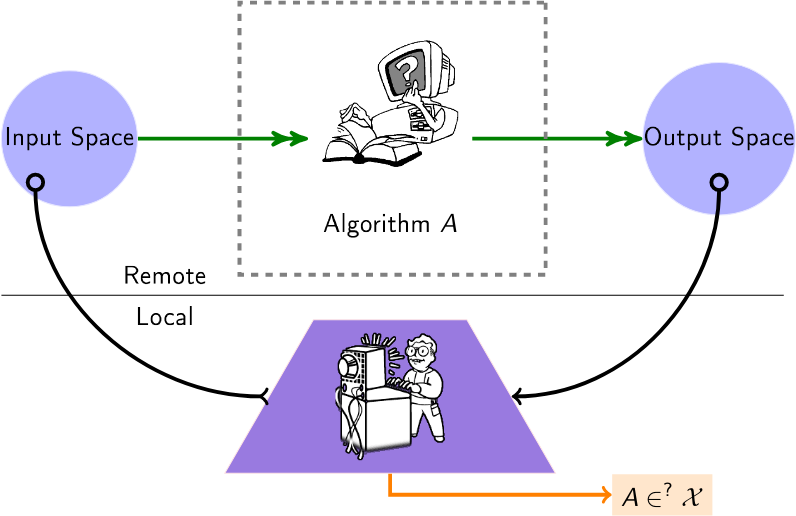
使用者查詢遠端演算法(例如,透過可用的API),以推斷有關該演算法的資訊。
內容
文件
2024年
- 審計本地解釋很困難 - (NeurIPS)給出審計解釋的(禁止的)查詢複雜性。
- 法學碩士也對圖產生幻覺:結構視角 -(複雜網絡)查詢法學碩士的已知圖並研究拓撲幻覺。提出結構性幻覺等級。
- 多代理協作的公平審核 - (ECAI)考慮多個代理一起工作,每個代理針對不同的任務審核同一平台。
- 繪製演算法審計領域:識別研究趨勢、語言和地理差異的系統性文獻綜述 - (Arxiv)對演算法審計研究的系統回顧以及其方法論趨勢的識別。
- FairProof:神經網路的機密性和可認證的公平性 - (Arxiv)提出了使用零知識證明等加密工具的傳統審計的替代範例;給出了一個名為 FairProof 的系統,用於驗證小型神經網路的公平性。
- 在操縱下,某些人工智慧模型是否更難審計? - (SATML)使用 Rademacher 複雜度將黑盒子審計的難度與目標模型的容量連結起來。
- 針對語言分類模型的改進成員推理攻擊 - (ICLR)提出了一個在審核模式下針對分類器運行成員推理攻擊的框架。
- 透過投注審核公平性 - (Neurips) [代碼]允許連續監視來自黑盒分類器或回歸器的傳入資料的順序方法。
2023年
- 透過一 (1) 次訓練運行進行隱私審計 -(NeurIPS - 最佳論文)一種透過單次訓練運行來審計差分隱私機器學習系統的方案。
- 透過反事實推理在不知情的情況下審計公平性 -(資訊處理與管理)展示如何揭示符合法規的黑盒模型是否仍然存在偏見。
- XAudit:從理論上來說帶有解釋的審計 - (Arxiv)形式化解釋在審計中的作用,並調查模型解釋是否以及如何幫助審計。
- 跟上語言模型:NLI 資料和模型中的穩健性與偏差的相互作用 - (Arxiv)提出了一種透過使用語言模型本身來延長稽核資料集保質期的方法;也發現當前偏差審計指標的問題並提出替代方案——這些替代方案強調模型的脆弱性表面上增加了先前的偏差分數。
- 透過迭代細化進行線上公平審計 - (KDD)提供自適應流程,自動推斷與估計公平性指標相關的機率保證。
- 竊取語言模型的解碼演算法 - (CCS)竊取 LLM 解碼演算法的類型和超參數。
- 對 YouTube 上的兔子洞進行建模 - (SNAM)對 YouTube 上的兔子洞中用戶的陷阱動態進行建模,並提供對該封閉空間的測量。
- 審查 YouTube 的推薦演算法是否存在錯誤訊息過濾氣泡 -(推薦系統上的交易)如何“戳破氣泡”,即從推薦中恢復氣泡外殼。
- 透過公平性的視角審查 Yelp 的業務排名和評論推薦 - (Arxiv)透過人口統計平等、曝光率和統計測試(例如分位數線性和邏輯回歸)審查 Yelp 的業務排名和評論推薦系統的公平性。
- Confidential-PROFITT:公平樹訓練的機密證明 - (ICLR)提出公平決策樹學習演算法以及零知識證明協議,以獲得審核伺服器上的公平性證明。
- SCALE-UP:透過分析擴展預測一致性進行有效的黑盒輸入級後門檢測 - (ICLR)考慮機器學習即服務 (MLaaS) 應用程式中黑盒設定下的後門檢測。
2022年
- 雙面:商業人臉辨識系統的對抗性審計 - (ICWSM)對多個系統 API 和資料集進行對抗性審計,提出一些令人擔憂的觀察結果。
- 擴大搜尋引擎審計:演算法審計的實用見解 - (資訊科學雜誌)(代碼)使用虛擬代理的模擬瀏覽行為審計多個搜尋引擎。
- 石灰熱情:實現與架構無關的模型距離 - (ICLR)使用 LIME 測量兩個遠程模型之間的距離。
- 主動公平審計 - (ICML)基於查詢的審計演算法的研究,可以以查詢有效的方式估計 ML 模型的人口統計奇偶性。
- 看看方差!基於 Sobol 的靈敏度分析的高效黑盒解釋 - (NeurIPS) Sobol 指數提供了一種有效的方法來捕捉影像區域之間的高階交互作用及其透過變異數鏡頭對(黑盒)神經網路預測的貢獻。
- 你的迴聲被聽到:亞馬遜智慧揚聲器生態系統中的追蹤、分析和廣告定位 - (arxiv)推斷 Amazon Echo 系統和廣告定位演算法之間的聯繫。
2021年
- 當裁判同時也是玩家時:電子商務市場上自有品牌產品推薦的偏見 - (FAccT)亞馬遜自有品牌產品是否獲得了不公平的推薦份額,因此與第三方產品相比是否具有優勢?
- 日常演算法審計:了解日常用戶在暴露有害演算法行為方面的力量 - (CHI)為用戶進行「日常演算法審計」提供了理由。
- 審核黑盒預測模型的資料最小化合規性 - (NeurIPS)使用有限數量的查詢來衡量預測模型滿足的資料最小化程度。
- 澄清影子禁令的記錄 - (INFOCOM)(代碼)考慮 Twitter 中影子禁令的可能性(即調節黑盒演算法),並測量幾個假設的機率。
- 從大型語言模型中提取訓練資料 -(USENIX 安全)從 GPT-2 模型的訓練資料中提取逐字文字序列。
- FairLens:審查黑盒臨床決策支援系統 -(資訊處理和管理)透過比較不同的多標籤分類差異度量,提供檢測和解釋臨床 DSS 中潛在公平性問題的管道。
- Twitter 上的審計演算法偏差 - (WebSci)。
- 貝葉斯演算法執行:使用互資訊估計黑盒函數的可計算屬性 - (ICML)一種預算約束和貝葉斯最佳化過程,用於從黑盒演算法中提取屬性。
2020年
- Black-Box Ripper:使用生成演化演算法複製黑盒模型 - (NeurIPS)複製黑盒神經模型的功能,但查詢量沒有限制(透過教師/學生方案和演化搜尋) 。
- 審計激進化路徑 - (FAT*)使用靜態管道推薦上的隨機遊走來研究激進管道彼此之間的可及性。
- 圖神經網路上的對抗模型提取 -(AAAI 圖深度學習研討會:方法論和應用)介紹了 GNN 模型提取並提出了初步方法。
- 遠程解釋性面臨保鑣問題 -(《自然機器智能》第 2 卷,第 529-539 頁)(代碼)顯示了遠程 AI 決策的解釋是不可能的(透過一個請求)或難以發現。
- GeoDA:黑盒對抗性攻擊的幾何框架 -(CVPR)(代碼)在純黑盒設定中製作對抗性範例來愚弄模型(無梯度,僅推斷類)。
- 模仿遊戲:利用黑盒推薦器進行演算法選擇 -(Netys)(程式碼)透過模仿遠端且訓練有素的演算法的決策來參數化本地推薦演算法。
- 審查新聞策展系統:檢視 Apple News 中的演算法和編輯邏輯的案例研究 - (ICWSM)將 Apple News 作為社會技術新聞策展系統的審查研究(熱門故事部分)。
- 審計演算法:關於經驗教訓和數據最小化的風險 - (AIES)對 Telefónica 開發的健康推薦應用程式的實際審計(主要是關於偏見)。
- 從大型語言模型中提取訓練資料 - (arxiv)執行訓練資料提取攻擊,透過查詢語言模型來恢復單一訓練範例。
2019年
- 用於遠端神經網路浮水印的對抗性前沿縫合 -(神經計算和應用)(替代實現)檢查遠端機器學習模型是否為「洩漏」模型:透過遠端模型的標準API 請求,提取(或不提取)零-位元浮水印,被插入到水印有價值的模型(例如,大型深度神經網路)。
- 仿冒網路:竊取黑盒模型的功能 - (CVPR)詢問對手可以在多大程度上竊取此類僅基於黑盒互動的「受害者」模型的功能:影像輸入,預測輸出。
- 打開黑盒子:審核 Google 的熱門故事演算法 - (Flairs-32)對 Google 的熱門故事面板的審核,提供對其用於選擇和排名新聞發布商的演算法選擇的見解
- 使有針對性的黑盒規避攻擊有效且高效 - (arXiv)研究對手如何最佳地利用其查詢預算對深度神經網路進行有針對性的規避攻擊。
- 用於衡量廣告拍賣中激勵相容性的線上學習 - (WWW)衡量黑盒拍賣平台的激勵相容性 (IC) 機制(遺憾)。
- TamperNN:部署神經網路的高效篡改偵測 - (ISSRE)精心設計輸入的演算法,可透過遠端執行的分類器模型偵測篡改。
- 透過聽取架構提示來進行邊緣設備中的神經網路模型提取攻擊 - (arxiv)透過從匯流排監聽中獲取記憶體存取事件,透過LSTM-CTC 模型識別層序列,根據記憶體存取模式進行層拓撲連接,以及根據記憶體存取模式進行層維度估計資料量限制,證明可以準確恢復類似的網路架構作為攻擊起點
- 使用複合未標記資料從受保護的深度神經網路竊取知識 - (ICNN)複合方法,可用於攻擊和提取黑盒模型的知識,即使它完全隱藏其 softmax 輸出。
- 透過背景知識對齊在對抗性環境中進行神經網路反演 - (CCS)對抗性環境中的模型反演方法,基於訓練充當原始模型的反演的反演模型。在不完全了解原始訓練資料的情況下,透過從更通用的資料分佈中提取的輔助樣本訓練反演模型,仍然可以實現準確的反演。
2018年
- 無需打開黑盒子的反事實解釋:自動決策和 GDPR -(《哈佛法律與技術雜誌》)要解釋關於 x 的決策,請找到一個反事實:最接近 x 且改變決策的點。
- 蒸餾與比較:使用透明模型蒸餾審核黑盒模型 - (AIES)將黑盒模型視為教師,訓練透明的學生模型來模仿黑盒模型分配的風險評分。
- 黑盒神經網路的逆向工程 -(ICLR)(程式碼)透過分析遠端神經網路模型對某些輸入的反應模式來推斷其內部超參數(例如層數、非線性活化類型)。
- 資料驅動的對抗域中黑盒分類器的探索性攻擊 -(神經計算)逆向工程遠端分類器模型(例如,用於逃避驗證碼測試)。
- xGEM:產生解釋黑盒模型的範例 - (arXiv)透過訓練無監督的隱式生成模型來搜尋黑盒模型中的偏差。然後透過沿著資料流形擾動資料樣本來定量總結黑盒模型的行為。
- 基於隨機遊走的節點相似性的學習網路 - (NIPS)透過觀察一些隨機遊走通勤時間來反轉圖。
- 從黑盒模型中識別機器學習系列 - (CAEPIA)確定返回的預測背後是哪種機器學習模型。
- 透過定時側通道竊取神經網路 - (arXiv)使用查詢透過定時攻擊竊取/近似模型。
- Copycat CNN:透過使用隨機非標記資料說服坦白來竊取知識 - (IJCNN)(程式碼)透過使用隨機自然圖像(ImageNet 和 Microsoft-COCO)查詢黑盒模型 (CNN) 來竊取知識。
- 審查政治相關搜尋引擎結果頁面的個人化和組成 - (WWW) Chrome 擴展,用於調查參與者並收集搜尋引擎結果頁面 (SERP) 和自動完成建議,以研究個人化和組成。
2017年
- 揭示影響力食譜:對同行排名服務中的拓撲影響進行逆向工程 - (CSCW)旨在確定同行排名服務中使用哪些中心性指標。
- 建議的拓撲面:偏差檢測的模型和應用 -(複雜網路)為向使用者推薦的項目提出了偏差檢測框架。
- 針對機器學習模型的成員推理攻擊 -(安全與隱私研討會)給定一個機器學習模型和一筆記錄,確定記錄是否用作模型訓練資料集的一部分。
- 針對機器學習的實用黑盒攻擊 -(亞洲 CCS)了解遠端服務如何容易受到對抗性分類攻擊的影響。
2016年
- 透過定量輸入影響實現演算法透明度:學習系統的理論和實驗 - (IEEE S&P)使用 shapley 值評估特徵對模型的個體、聯合和邊際影響。
- 審核黑盒模型的間接影響 - (ICDM)透過「巧妙地」將變數從資料集中刪除並查看準確性差距來評估變數對黑盒模型的影響
- 用於診斷黑盒模型偏差的迭代正交特徵投影 -(FATML 研討會)執行特徵排序以分析黑盒模型
- 線上自由職業市場中的偏差:來自 TaskRabbit 的證據 -(dat 研討會)衡量 TaskRabbit 的搜尋演算法排名。
- 透過預測 API 竊取機器學習模型 -(Usenix Security)(程式碼)旨在提取遠端服務使用的機器學習模型。
- 「為什麼我應該相信你?」解釋任何分類器的預測 - (arXiv)(程式碼)透過圍繞資料實例進行取樣來解釋黑盒分類器模型。
- 回歸黑色:對消毒劑和過濾器進行正式的黑盒分析 -(安全和隱私)消毒劑和過濾器的黑盒分析。
- 透過定量輸入影響來實現演算法透明度:學習系統的理論和實驗 -(安全性和隱私)引入了捕獲輸入對觀察系統輸出的影響程度的措施。
- 亞馬遜商城演算法定價的實證分析 - (WWW)(程式碼)開發一種檢測演算法定價的方法,並根據經驗使用它來分析其在亞馬遜商城上的流行程度和行為。
2015年
- 證明和消除不同的影響 - (SIGKDD)提出基於 SVM 的方法來證明不存在偏差,以及從資料集中消除偏差的方法。
- Peeking Under the Hood of Uber - (IMC)推斷 Uber 激增價格演算法的實作細節。
2014年
- 窺視黑盒子:透過隨機化探索分類器 -(資料探勘和知識發現期刊)(程式碼)尋找可以在不更改預測樣本的輸出標籤的情況下進行排列的特徵組
- XRay:透過差分關聯增強網路透明度 -(USENIX 安全性)審查哪些使用者個人資料資料用於定位特定廣告、推薦或價格。
2013年
- 衡量 Web 搜尋的個人化 - (WWW)開發一種衡量 Web 搜尋結果個人化的方法。
- 審核:具有結果相關查詢成本的主動學習 - (NIPS)從僅支付負標籤費用的二元分類器中學習。
2012年
- 規避凸分類器的查詢策略 - (JMLR)凸分類器的規避方法。考慮規避複雜性。
2008年
- Privacy Oracle:一種透過黑盒差異測試來尋找應用程式洩漏的系統 - (CCS) Privacy Oracle:一種發現應用程式在向遠端伺服器傳輸過程中洩露個人資訊的系統。
2005年
- 對抗性學習 - (KDD)使用成員資格查詢對遠端線性分類器進行逆向工程。
相關活動
2024年
- 第一屆審計與人工智慧國際會議
- 可調式機器學習研討會 (RegML'24)
2023年
- 支援用戶參與測試、審核和競爭 AI(CSCW 用戶 AI 審核)
- 演算法的演算法審計研討會(WAAA)
- 可調式機器學習研討會 (RegML'23)


