LaTeX OCR
1.0.0
該專案的目標是創建一個基於學習的系統,該系統獲取數學公式的圖像並返回相應的 LaTeX 程式碼。
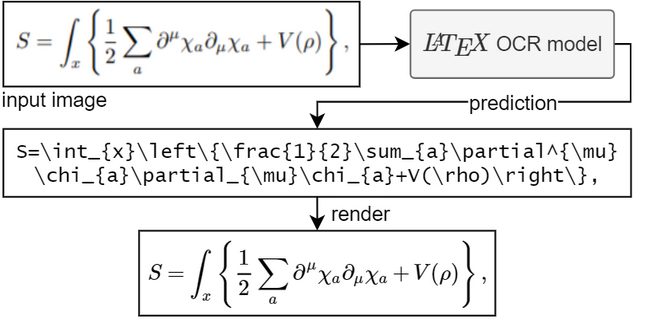
要運行模型,您需要 Python 3.7+
如果您沒有安裝 PyTorch。請按照此處的說明進行操作。
安裝pix2tex軟體包:
pip install "pix2tex[gui]"
模型檢查點將自動下載。
有三種方法可以從影像中獲得預測。
您可以透過呼叫pix2tex來使用命令列工具。在這裡您可以解析磁碟中已有的映像和剪貼簿中的映像。
感謝@katie-lim,您可以使用漂亮的使用者介面作為獲得模型預測的快速方法。只需使用latexocr呼叫 GUI 即可。從這裡您可以截取螢幕截圖,並使用 MathJax 呈現預測的乳膠程式碼並將其複製到剪貼簿。
在 Linux 下,如果事先安裝了gnome-screenshot則可以使用具有gnome-screenshot (支援多顯示器)的 GUI。對於 Wayland,當grim和slurp都可用時將使用它們。請注意, gnome-screenshot與基於 wlroots 的 Wayland 合成器不相容。由於gnome-screenshot在可用時將是首選,因此在這種情況下您可能必須將環境變數SCREENSHOT_TOOL設為grim (其他可用值是gnome-screenshot和pil )。
如果模型不確定影像中的內容,則每次按一下「重試」時,它可能會輸出不同的預測。使用temperature參數,您可以控制這種行為(低溫會產生相同的結果)。
您可以使用 API。這有額外的依賴性。透過pip install -U "pix2tex[api]"安裝並運行
python -m pix2tex.api.run
啟動連接到連接埠 8502 處的 API 的 Streamlit 示範。
docker pull lukasblecher/pix2tex:api docker run --rm -p 8502:8502 lukasblecher/pix2tex:api
還要運行streamlit演示運行
docker run --rm -it -p 8501:8501 --entrypoint python lukasblecher/pix2tex:api pix2tex/api/run.py
並導航至 http://localhost:8501/
從 Python 內部使用
from PIL import Imagefrom pix2tex.cli import LatexOCRimg = Image.open('path/to/image.png')model = LatexOCR()print(model(img))此模型最適用於解析度較小的影像。這就是為什麼我添加了一個預處理步驟,其中另一個神經網路預測輸入影像的最佳解析度。該模型將自動調整自訂圖像的大小,以最接近訓練數據,從而提高在野外發現的圖像的性能。但它仍然不完美,可能無法以最佳方式處理大圖像,因此在拍照之前不要將其完全放大。
務必仔細檢查結果。如果答案錯誤,您可以嘗試使用其他解析度重新進行預測。
想要使用該套件嗎?
我現在正在嘗試編寫文件。
請造訪此處:https://pix2tex.readthedocs.io/
安裝幾個相依性pip install "pix2tex[train]" 。
首先,我們需要將圖像與其真實標籤結合。我編寫了一個資料集類別(需要進一步改進),它使用渲染圖像的 LaTeX 程式碼保存圖像的相對路徑。若要產生資料集 pickle 文件,請執行
python -m pix2tex.dataset.dataset --equations path_to_textfile --images path_to_images --out dataset.pkl
要使用您自己的標記產生器,請透過--tokenizer傳遞它(見下文)。
您也可以在 Google Drive 上找到我產生的訓練資料(formulae.zip - 圖像、math.txt - 標籤)。對驗證和測試資料重複此步驟。全部使用相同的標籤文字檔。
將設定檔中的data (和valdata )條目編輯到新產生的.pkl檔中。如果需要,可以更改其他超參數。請參閱pix2tex/model/settings/config.yaml取得範本。
現在進行實際訓練
python -m pix2tex.train --config path_to_config_file
如果您想使用自己的數據,您可能有興趣創建自己的分詞器
python -m pix2tex.dataset.dataset --equations path_to_textfile --vocab-size 8000 --out tokenizer.json
不要忘記更新設定檔中標記生成器的路徑並將num_tokens設定為您的詞彙量大小。
該模型由具有 ResNet 主幹的 ViT [1] 編碼器和 Transformer [2] 解碼器組成。
| BLEU 分數 | 標準化編輯距離 | 令牌準確度 |
|---|---|---|
| 0.88 | 0.10 | 0.60 |
我們需要配對數據供網路學習。幸運的是,網路上有許多 LaTeX 程式碼,例如 wikipedia、arXiv。我們也使用 im2latex-100k [3] 資料集中的公式。所有這些都可以在這裡找到
為了以多種不同的字體呈現數學,我們使用 XeLaTeX,產生 PDF 並最終將其轉換為 PNG。對於最後一步,我們需要使用一些第三方工具:
XeLaTeX
ImageMagick 與 Ghostscript。 (用於將 pdf 轉換為 png)
Node.js 運行 KaTeX(用於標準化 Latex 程式碼)
Python 3.7+ 和依賴項(在setup.py中指定)
拉丁文現代數學、GFSNeohellenicMath.otf、Asana 數學、XITS 數學、Cambria 數學
增加更多評估指標
建立一個圖形使用者介面
新增波束搜尋
支援手寫公式(有點完成,請參閱訓練 colab 筆記本)
縮小模型尺寸(蒸餾)
找到最佳超參數
調整模型結構
修復數據抓取並抓取更多數據
追蹤模型 (#2)
歡迎任何形式的貢獻。
程式碼取自 lucidrains、rwightman、im2markup、arxiv_leaks、pkra:Mathjax、harupy:截圖工具並進行修改
[1] 一張圖片勝過 16x16 個字
[2] 注意力就是你所需要的
[3] 具有粗到細注意力的圖像到標記生成


