obfuscated gradients
v1.0.0
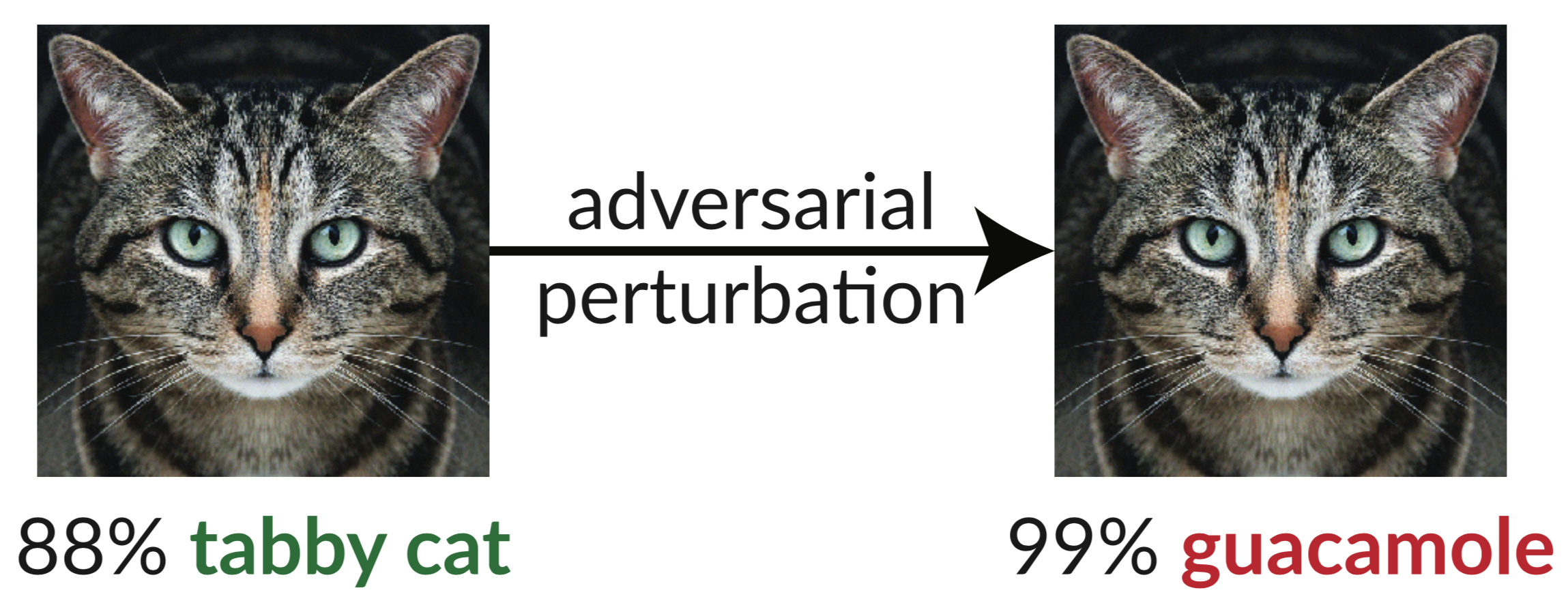
上面是一個對抗性範例:貓的輕微擾動圖像欺騙了 InceptionV3 分類器,將其分類為「酪梨醬」。使用梯度下降很容易合成這種「愚弄圖像」(Szegedy et al. 2013)。
在我們最近的論文中,我們評估了 ICLR 2018 接受的 9 篇論文的穩健性,作為對抗性示例的未經認證的白盒安全防禦。我們發現九種防禦措施中的七種在穩健性方面的提高有限,並且可以透過我們開發的改進的攻擊技術來破解。
以下是我們論文中的表 1,其中我們展示了每個已接受的防禦對於我們可以建構的對抗性範例的穩健性:
| 防禦 | 數據集 | 距離 | 準確性 |
|---|---|---|---|
| 巴克曼等人。 (2018) | 西法爾 | 0.031(線性) | 0%* |
| 馬等人。 (2018) | 西法爾 | 0.031(線性) | 5% |
| 郭等人。 (2018) | 影像網 | 0.05(l2) | 0%* |
| 迪倫等人。 (2018) | 西法爾 | 0.031(線性) | 0% |
| 謝等人。 (2018) | 影像網 | 0.031(線性) | 0%* |
| 宋等人。 (2018) | 西法爾 | 0.031(線性) | 9%* |
| 薩曼古埃等。 (2018) | MNIST | 0.005(l2) | 55%** |
| 馬德里等人。 (2018) | 西法爾 | 0.031(線性) | 47% |
| 娜等人。 (2018) | 西法爾 | 0.015(線性) | 15% |
(以* 表示的防禦也建議結合對抗性訓練;我們在這裡單獨報告防禦。完整數字請參閱我們的論文第5 節。用** 表示的防禦背後的基本原理的準確度為0%;在實踐中,防禦缺陷導致理論上的失敗的最佳攻擊,請參閱第 5.4.2 節以了解詳細資訊。
我們觀察到的唯一能夠顯著提高所提出的威脅模型中對抗性示例魯棒性的防禦措施是「邁向抵抗對抗性攻擊的深度學習模型」(Madry 等人,2018 年),並且我們無法在不走出威脅模型的情況下擊敗這種防禦措施。即便如此,該技術仍被證明難以擴展到 ImageNet 規模(Kurakin 等人,2016 年)。其餘論文(除了 Na 等人的論文,其穩健性有限)無意或有意地依賴我們所說的混淆梯度。標準攻擊應用梯度下降來最大化給定圖像上的網路損失,從而在神經網路上生成對抗性範例。這種最佳化方法需要有用的梯度訊號才能成功。當防禦混淆梯度時,它會破壞該梯度訊號並導致基於最佳化的方法失敗。
我們確定了防禦措施導致梯度混淆的三種方式,並建構了攻擊來繞過每種情況。我們的攻擊通常適用於任何有意或無意地包括不可微分操作或以其他方式阻止梯度訊號流過網路的防禦。我們希望未來的工作能夠使用我們的方法來進行更徹底的安全評估。
抽象的:
我們認為混淆梯度(一種梯度掩蔽)是一種在防禦對抗性範例時導致錯誤的安全感的現象。雖然導致混淆梯度的防禦措施似乎能夠擊敗基於迭代優化的攻擊,但我們發現依賴這種效果的防禦措施是可以被規避的。我們描述了表現出這種效果的防禦的特徵行為,並且對於我們發現的三種類型的混淆梯度中的每一種,我們開發了攻擊技術來克服它。在 ICLR 2018 上檢查未經認證的白盒安全防禦的案例研究中,我們發現混淆梯度很常見,9 種防禦中有 7 種依賴混淆梯度。我們的新攻擊成功地完全規避了每篇論文考慮的原始威脅模型中的 6 個攻擊,以及部分攻擊。
有關詳細信息,請閱讀我們的論文。
該儲存庫包含我們論文中描述的一般攻擊技術的實例,突破了 ICLR 2018 的 7 項防禦措施。有些防禦措施沒有發布原始程式碼(在我們做這項工作時),所以我們不得不重新實作它們。
@inproceedings{obfuscated-gradients,作者= {Anish Athalye 和Nicholas Carlini 和David Wagner},標題= {混淆梯度給出錯誤的安全感:規避對抗性示例的防禦},書名= {第35 屆國際機器會議論文集學習,{ICML} 2018},年份 = {2018},月份 = jul,url = {https://arxiv.org/abs/1802.00420},
} 

