Megatron LM
NVIDIA Megatron Core 0.9.0
此儲存庫包含兩個基本元件: Megatron-LM和Megatron-Core 。 Megatron-LM 是一個以研究為導向的框架,利用 Megatron-Core 進行大型語言模型 (LLM) 訓練。另一方面,Megatron-Core 是一個 GPU 優化訓練技術庫,附帶正式產品支持,包括版本化 API 和定期發布。您可以將 Megatron-Core 與 Megatron-LM 或 Nvidia NeMo Framework 一起使用,以實現端到端和雲端原生解決方案。或者,您可以將 Megatron-Core 的建置模組整合到您首選的培訓框架中。
Megatron(1、2 和 3)於 2019 年首次推出,引發了人工智慧社群的創新浪潮,使研究人員和開發人員能夠利用該庫的基礎來進一步推動法學碩士的進步。如今,許多最受歡迎的 LLM 開發框架都是受到開源 Megatron-LM 庫的啟發並直接利用其構建的,從而引發了一波基礎模型和人工智慧新創公司的浪潮。一些基於 Megatron-LM 構建的最受歡迎的 LLM 框架包括 Colossal-AI、HuggingFace Accelerate 和 NVIDIA NeMo Framework。直接使用威震天的項目清單可以在這裡找到。
Megatron-Core 是一個基於 PyTorch 的開源函式庫,包含 GPU 最佳化技術和尖端的系統級最佳化。它將它們抽象化為可組合和模組化的 API,使開發人員和模型研究人員能夠充分靈活地在 NVIDIA 加速運算基礎架構上大規模訓練自訂 Transformer。該程式庫與所有 NVIDIA Tensor Core GPU 相容,包括對 NVIDIA Hopper 架構的 FP8 加速支援。
Megatron-Core 提供核心建構模組,例如注意力機制、變壓器塊和層、歸一化層和嵌入技術。啟動重新計算、分散式檢查點等附加功能也原生內建於該函式庫中。構建塊和功能均經過 GPU 優化,並且可以使用高級並行化策略進行構建,以在 NVIDIA 加速計算基礎設施上實現最佳訓練速度和穩定性。 Megatron-Core 庫的另一個關鍵組件包括高級模型平行技術(張量、序列、管道、上下文和 MoE 專家並行)。
Megatron-Core 可與企業級 AI 平台 NVIDIA NeMo 搭配使用。或者,您可以在此處使用本機 PyTorch 訓練循環來探索 Megatron-Core。請造訪 Megatron-Core 文件以了解更多資訊。
我們的程式碼庫能夠有效地訓練具有模型和資料並行性的大型語言模型(即具有數千億個參數的模型)。為了展示我們的軟體如何透過多個 GPU 和模型大小進行擴展,我們考慮了從 20 億個參數到 4,620 億個參數的 GPT 模型。所有模型都使用 131,072 的詞彙量和 4096 的序列長度 我們改變隱藏大小、注意力頭數量和層數以達到特定的模型大小。隨著模型大小的增加,我們也會適度增加批量大小。我們的實驗使用多達 6144 個 H100 GPU。我們執行資料並行( --overlap-grad-reduce --overlap-param-gather )、張量並行( --tp-comm-overlap )和管道並行通訊(預設為啟用)的細粒度重疊計算以提高可擴展性。報告的吞吐量是針對端到端訓練進行測量的,包括所有操作,包括資料載入、優化器步驟、通訊甚至日誌記錄。請注意,我們沒有訓練這些模型來收斂。
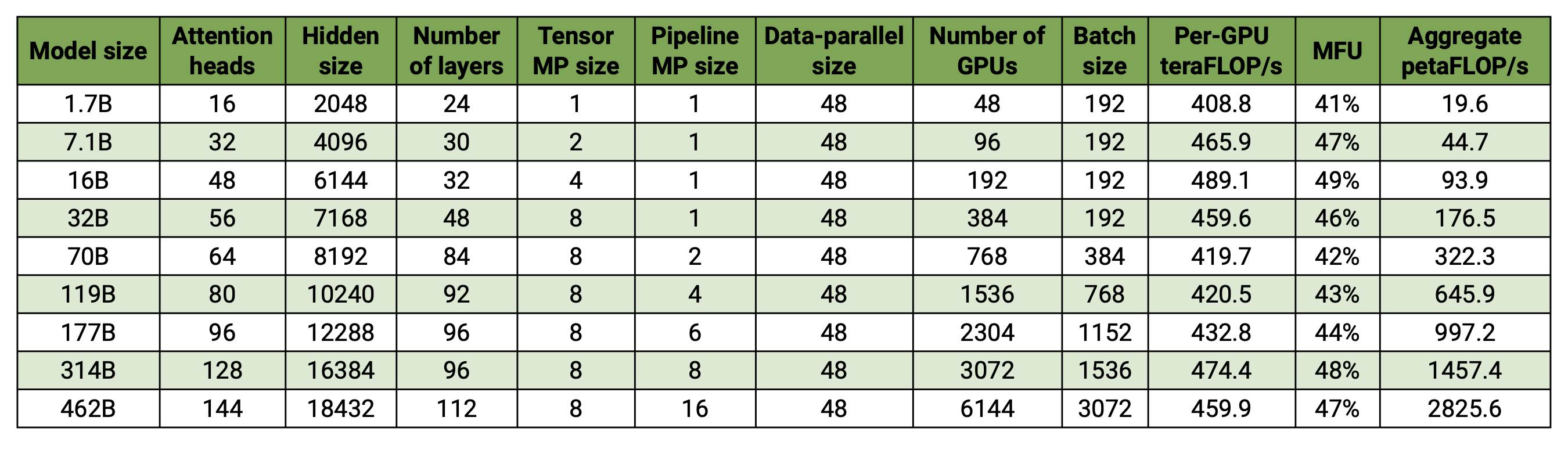
我們的弱縮放結果顯示超線性縮放(MFU 從最小模型的 41% 增加到最大模型的 47-48%);這是因為更大的 GEMM 具有更高的算術強度,因此執行效率更高。
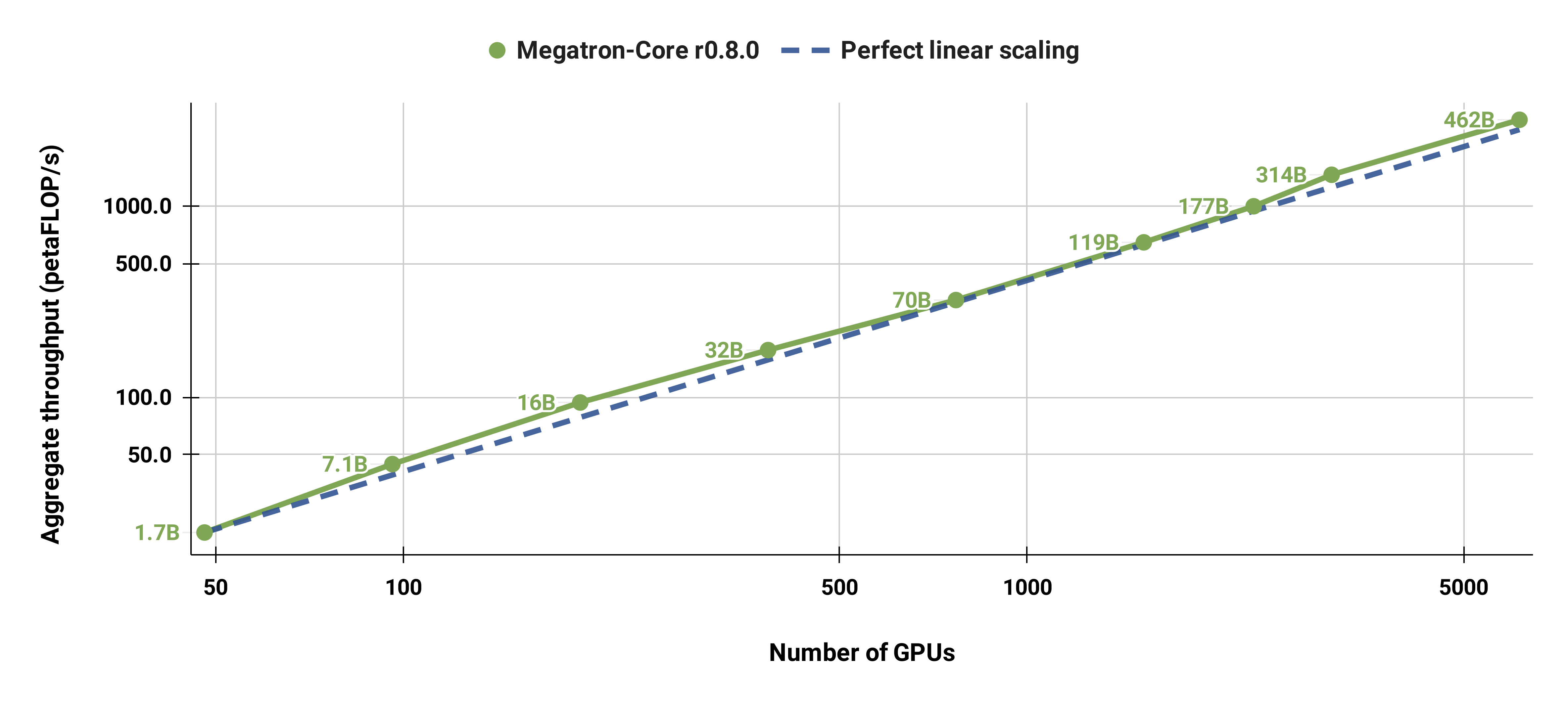
我們還將標準 GPT-3 模型(由於詞彙量較大,我們的版本具有略多於 1750 億個參數)從 96 個 H100 GPU 擴展到 4608 個 GPU,並始終使用 1152 個序列的相同批次大小。通訊在更大範圍內變得更加暴露,導致 MFU 從 47% 減少到 42%。
我們強烈建議將最新版本的 NGC 的 PyTorch 容器與 DGX 節點結合使用。如果您因為某些原因無法使用此功能,請使用最新的 pytorch、cuda、nccl 和 NVIDIA APEX 版本。資料預處理需要 NLTK,但這對於訓練、評估或下游任務來說不是必需的。
您可以使用以下 Docker 命令啟動 PyTorch 容器的實例並掛載 Megatron、您的資料集和檢查點:
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3
docker run --gpus all -it --rm -v /path/to/megatron:/workspace/megatron -v /path/to/dataset:/workspace/dataset -v /path/to/checkpoints:/workspace/checkpoints nvcr.io/nvidia/pytorch:xx.xx-py3
我們提供了預訓練的 BERT-345M 和 GPT-345M 檢查點來評估或微調下游任務。若要存取這些檢查點,請先註冊並設定 NVIDIA GPU Cloud (NGC) 註冊表 CLI。有關下載模型的更多文件可以在 NGC 文件中找到。
或者,您可以使用以下方式直接下載檢查點:
BERT-345M-uncased:wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O megatron_bert_345m_v0.1_uncased.zip BERT-345M-cased:wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O megatron_bert_345m_v0.1_cased.zip GPT-345M:wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
這些模型需要詞彙檔才能運作。 BERT WordPiece 詞彙檔案可以從 Google 預訓練的 BERT 模型中提取:uncased、cased。 GPT詞彙檔和合併表可以直接下載。
安裝後,有幾個可能的工作流程。最全面的是:
然而,步驟 1 和 2 可以透過使用上述預訓練模型之一來代替。
我們在examples目錄中提供了多個用於預訓練 BERT 和 GPT 的腳本,以及用於零樣本和微調下游任務的腳本,包括 MNLI、RACE、WikiText103 和 LAMBADA 評估。還有一個用於 GPT 互動式文字產生的腳本。
訓練資料需要預處理。首先,將訓練資料採用鬆散的 json 格式,其中一個 json 每行包含一個文字樣本。例如:
{“src”:“www.nvidia.com”,“text”:“敏捷的棕色狐狸”,“type”:“Eng”,“id”:“0”,“title”:“第一部分”}
{"src": "互聯網", "text": "跳過懶狗", "type": "Eng", "id": "42", "title": "第二部分"}
json text欄位的名稱可以透過使用preprocess_data.py中的--json-key標誌來更改。
然後將鬆散的 json 處理為二進位格式以進行訓練。若要將 json 轉換為 mmap 格式,請使用preprocess_data.py 。為 BERT 訓練準備資料的範例腳本是:
python 工具/preprocess_data.py
--輸入 my-corpus.json
--輸出前綴 my-bert
--vocab-檔案 bert-vocab.txt
--tokenizer-type BertWordPieceLowerCase
--分割句子
輸出將是兩個文件,在本例中名為my-bert_text_sentence.bin和my-bert_text_sentence.idx 。後面的 BERT 訓練中指定的--data-path是完整路徑和新檔案名,但不含檔案副檔名。
對於 T5,使用與 BERT 相同的預處理,也許將其重新命名為:
--輸出前綴 my-t5
GPT 資料預處理需要進行一些小的修改,即新增合併表、文件結束標記、刪除句子拆分以及更改標記器類型:
python 工具/preprocess_data.py
--輸入 my-corpus.json
--輸出前綴 my-gpt2
--vocab-檔案 gpt2-vocab.json
--tokenizer-type GPT2BPETokenizer
--合併檔案 gpt2-merges.txt
--追加eod
這裡的輸出檔被命名為my-gpt2_text_document.bin和my-gpt2_text_document.idx 。和以前一樣,在 GPT 訓練中,使用不帶擴展名的較長名稱作為--data-path 。
在原始碼檔案preprocess_data.py中描述了更多命令列參數。
examples/bert/train_bert_340m_distributed.sh腳本執行單 GPU 345M 參數 BERT 預訓練。偵錯是單 GPU 訓練的主要用途,因為程式碼庫和命令列參數針對高度分散式訓練進行了最佳化。大多數論點都是不言自明的。預設情況下,學習率在從--lr開始的訓練迭代中線性衰減到--lr-decay-iters迭代中由--min-lr設定的最小值。用於預熱的訓練迭代分數由--lr-warmup-fraction設定。雖然這是單 GPU 訓練, --micro-batch-size指定的批次大小是單一前向-後向路徑批次大小,並且程式碼將執行梯度累積步驟,直到達到global-batch-size批次大小)每次迭代。資料以 949:50:1 的比例分為訓練/驗證/測試集(預設為 969:30:1)。這種分區是動態發生的,但在使用相同隨機種子的運行中是一致的(預設為 1234,或使用--seed手動指定)。我們使用train-iters作為訓練迭代的要求。或者,可以提供--train-samples這是要訓練的樣本總數。如果存在此選項,則不需要提供--lr-decay-iters ,而是需要提供--lr-decay-samples 。
指定了日誌記錄、檢查點保存和評估間隔選項。請注意, --data-path現在包含在預處理中新增的附加_text_sentence後綴,但不包含檔案副檔名。
來源檔arguments.py中描述了更多命令列參數。
若要執行train_bert_340m_distributed.sh ,請進行任何所需的修改,包括設定CHECKPOINT_PATH 、 VOCAB_FILE和DATA_PATH的環境變數。確保將這些變數設定為其在容器中的路徑。然後啟動安裝了威震天和必要路徑的容器(如設定中所述)並執行範例腳本。
examples/gpt3/train_gpt3_175b_distributed.sh腳本執行單 GPU 345M 參數 GPT 預訓練。如上所述,單 GPU 訓練主要用於偵錯目的,因為程式碼針對分散式訓練進行了最佳化。
它遵循與先前的 BERT 腳本基本相同的格式,但有一些顯著的差異:使用的標記化方案是 BPE(需要合併表和json詞彙文件)而不是WordPiece,模型架構允許更長的序列(請注意,最大位置嵌入必須大於或等於最大序列長度),並且--lr-decay-style已設定為餘弦衰減。請注意, --data-path現在包含在預處理中新增的附加_text_document後綴,但不包含檔案副檔名。
來源檔arguments.py中描述了更多命令列參數。
train_gpt3_175b_distributed.sh可以按照與 BERT 描述相同的方式啟動。設定環境變數並進行任何其他修改,使用適當的安裝啟動容器,然後執行腳本。更多詳細信息,請examples/gpt3/README.md
與 BERT 和 GPT 非常相似, examples/t5/train_t5_220m_distributed.sh腳本運行單 GPU「基礎」(~220M 參數)T5 預訓練。與 BERT 和 GPT 的主要區別是添加了以下參數以適應 T5 架構:
--kv-channels設定模型中所有註意力機制的「鍵」和「值」矩陣的內部維度。對於 BERT 和 GPT,預設為隱藏大小除以注意力頭的數量,但可以為 T5 配置。
--ffn-hidden-size設定變壓器層內前饋網路中的隱藏大小。對於 BERT 和 GPT,預設為轉換器隱藏大小的 4 倍,但可以為 T5 配置。
--encoder-seq-length和--decoder-seq-length分別設定編碼器和解碼器的序列長度。
所有其他論點仍然與 BERT 和 GPT 預訓練相同。使用上述其他腳本的相同步驟執行此範例。
更多詳細信息,請參閱examples/t5/README.md
pretrain_{bert,gpt,t5}_distributed.sh腳本使用 PyTorch 分散式啟動器進行分散式訓練。這樣,透過適當設定環境變數就可以實現多節點訓練。有關這些環境變數的進一步描述,請參閱 PyTorch 官方文件。預設情況下,多節點訓練使用 nccl 分散式後端。一組簡單的附加參數以及使用 PyTorch 分散式模組和torchrun彈性啟動器(相當於python -m torch.distributed.run )是採用分散式訓練的唯一附加要求。有關更多詳細信息,請參閱pretrain_{bert,gpt,t5}_distributed.sh中的任何一個。
我們使用兩種類型的並行性:資料並行性和模型並行性。我們的資料並行實作位於megatron/core/distributed中,並且在使用--overlap-grad-reduce命令列選項時支援梯度縮減與後向傳遞的重疊。
其次,我們開發了一種簡單且高效的二維模型平行方法。若要使用第一個維度,即張量模型並行性(將單一轉換器模組的執行拆分到多個 GPU 上,請參閱我們論文的第 3 節),請新增--tensor-model-parallel-size標誌來指定要執行的GPU 數量分割模型,以及如上所述傳遞給分散式啟動器的參數。要使用第二個維度,即序列並行性,請指定--sequence-parallel ,這還需要啟用張量模型並行性,因為它會跨相同的GPU 進行拆分(更多詳細信息請參閱我們論文的第4.2.2 節)。
要使用管道模型並行性(將變壓器模組分片為各個階段,每個階段上具有相同數量的變壓器模組,然後透過將批次分解為更小的微批次來管線執行,請參閱我們論文的第2.2 節),請使用--pipeline-model-parallel-size標誌指定將模型拆分為的階段數(例如,將具有24 個變壓器層的模型拆分為4 個階段將意味著每個階段各有6 個變壓器層)。
我們提供如何使用這兩種不同形式的模型並行性的範例(以distributed_with_mp.sh結尾的範例腳本)。
除了這些細微的變化之外,分散式訓練與單一 GPU 上的訓練相同。
可使用--num-layers-per-virtual-pipeline-stage參數啟用交錯管線調度(更多詳細資訊請參閱本文的第2.2.2 節),此參數控制虛擬階段中變壓器層的數量(預設情況下)使用非交錯調度,每個 GPU 將執行具有NUM_LAYERS / PIPELINE_MP_SIZE轉換器層的單一虛擬階段。變壓器模型中的總層數應能被此參數值整除。此外,使用此計劃時,管道中的微批次數量(計算為GLOBAL_BATCH_SIZE / (DATA_PARALLEL_SIZE * MICRO_BATCH_SIZE) )應能被PIPELINE_MP_SIZE整除(此條件在程式碼中的斷言中檢查)。具有 2 個階段的管道 ( PIPELINE_MP_SIZE=2 ) 不支援交錯調度。
為了減少訓練大型模型時 GPU 記憶體的使用,我們支援各種形式的啟動檢查點和重新計算。與深度學習模型中的傳統情況不同,所有激活都存儲在內存中以便在反向傳播期間使用,只有模型中某些“檢查點”的激活才會保留(或存儲)在內存中,而其他激活則重新計算-the-fly 當需要反向傳播時。請注意,這種檢查點(啟動檢查點)與其他地方提到的模型參數和最佳化器狀態的檢查點有很大不同。
我們支援兩種等級的重新計算粒度: selective和full 。選擇性重新計算是預設設置,並且在幾乎所有情況下都建議使用。此模式將佔用較少記憶體儲存空間且重新計算成本較高的啟動保留在記憶體中,並重新計算佔用較多記憶體儲存空間但重新計算相對便宜的啟動。有關詳細信息,請參閱我們的論文。您應該發現此模式可以最大限度地提高效能,同時最大限度地減少儲存啟動所需的記憶體。若要啟用選擇性啟動重新計算,只需使用--recompute-activations 。
對於記憶體非常有限的情況, full重新計算僅保存變壓器層或變壓器層組或區塊的輸入,並重新計算其他所有內容。若要啟用完全啟動重新計算,請使用--recompute-granularity full 。使用full啟動重新計算時,有兩種方法: uniform和block ,使用--recompute-method參數進行選擇。
uniform方法將 Transformer 層統一劃分為層組(每組大小為--recompute-num-layers ),並將每組的輸入激活儲存在記憶體中。基線組大小為 1,在這種情況下,儲存每個轉換器層的輸入啟動。當 GPU 記憶體不足時,增加每組的層數可以減少記憶體使用量,從而可以訓練更大的模型。例如,當--recompute-num-layers設定為 4 時,僅儲存每組 4 個轉換器層的輸入啟動。
block方法重新計算每個管道階段的特定數量(由--recompute-num-layers給出)的各個 Transformer 層的輸入激活,並將其餘層的輸入激活儲存在管道階段。減少--recompute-num-layers會導致將輸入激活儲存到更多轉換器層,從而減少反向傳播中所需的激活重新計算,從而提高訓練性能,同時增加記憶體使用量。例如,當我們指定 5 層來重新計算每個管道階段的 8 層時,只有前 5 個轉換器層的輸入啟動在反向傳播步驟中被重新計算,而最後 3 層的輸入啟動被儲存。 --recompute-num-layers可以逐漸增加,直到所需的內存存儲空間量剛好小到足以適合可用內存,從而最大限度地利用內存並最大化性能。
用法: --use-distributed-optimizer 。與所有模型和資料類型相容。
分散式優化器是一種記憶體節省技術,優化器狀態均勻分佈在資料並列之間(與跨資料並行複製優化器狀態的傳統方法不同)。如《ZeRO:訓練兆參數模型的記憶體最佳化》所述,我們的實作分佈了與模型狀態不重疊的所有最佳化器狀態。例如,當使用 fp16 模型參數時,分散式最佳化器會維護自己的 fp32 主要參數和梯度的單獨副本,這些副本分佈在 DP 等級中。然而,當使用bf16 模型參數時,分散式最佳化器的fp32 主參數與模型的fp32 主參數相同,因此這種情況下的參數不是分散式的(儘管fp32 主參數仍然是分佈式的,因為它們與bf16 是分開的)模型參數)。
理論上的記憶體節省量會根據模型的 param dtype 和 grad dtype 的組合而有所不同。在我們的實作中,每個參數的理論位元組數為(其中“d”是資料並行大小):
| 非分散式最佳化 | 分散式最佳化 | |
|---|---|---|
| fp16 參數、fp16 梯度 | 20 | 4 + 16/天 |
| bf16 參數,fp32 梯度 | 18 | 6+12/天 |
| fp32 參數、fp32 梯度 | 16 | 8+8/天 |
與常規資料並行性一樣,可以使用--overlap-grad-reduce標誌來促進梯度減少(在本例中為減少分散)與向後傳遞的重疊。此外,參數 all-gather 的重疊可以使用--overlap-param-gather與前向傳遞重疊。
用法: --use-flash-attn 。最多支援128個注意力頭尺寸。
FlashAttention 是一種快速且節省記憶體的演算法,用於計算精確注意力。它加快了模型訓練速度並減少了記憶體需求。
安裝 FlashAttention:
pip install flash-attn在examples/gpt3/train_gpt3_175b_distributed.sh中,我們提供如何設定 Megatron 在 1024 個 GPU 上使用 1750 億個參數訓練 GPT-3 的範例。該腳本是為帶有 pyxis 插件的 slurm 設計的,但可以輕鬆地應用於任何其他調度程序。它採用8路張量並行和16路管道並行。使用選項global-batch-size 1536和rampup-batch-size 16 16 5859375 ,訓練將從全域批次大小16 開始,並在5,859,375 個樣本上以增量步驟16 將全域批量大小線性增加到1536。可以是單一集合或多個資料集與一組權重的組合。
在 1024 個 A100 GPU 上的完整全域批次大小為 1536 時,每次迭代大約需要 32 秒,導致每個 GPU 達到 138 teraFLOP,這是理論峰值 FLOP 的 44%。
Retro(Borgeaud 等人,2022)是一種經過檢索增強預訓練的自回歸解碼器語言模型 (LM)。 Retro 具有實用的可擴展性,可透過檢索數兆個代幣來支援從頭開始的大規模預訓練。與在網路參數中隱式儲存事實知識相比,具有檢索的預訓練提供了更有效的事實知識儲存機制,從而大大減少了模型參數,同時實現了比標準 GPT 更低的困惑度。 Retro 還可以透過更新檢索資料庫來靈活地更新 LM 中儲存的知識(Wang 等人,2023a),而無需再次訓練 LM。
InstructRetro(Wang 等人,2023b)進一步將 Retro 的大小擴大到 48B,具有最大的經過檢索預訓練的 LLM(截至 2023 年 12 月)。所得的基礎模型 Retro 48B 在困惑度方面大大優於 GPT 模型。透過對 Retro 進行指令調整,InstructRetro 在零樣本設定中的下游任務上展示了比指令調整 GPT 的顯著改進。具體而言,InstructRetro 在 8 項短格式 QA 任務中的平均改進比 GPT 同行提高了 7%,在 4 項具有挑戰性的長格式 QA 任務中比 GPT 平均改進了 10%。我們還發現,可以從 InstructRetro 架構中消除編碼器,並直接使用 InstructRetro 解碼器主幹作為 GPT,同時獲得可比較的結果。
在此儲存庫中,我們提供了實作 Retro 和 InstructRetro 的端對端複製指南,涵蓋
有關詳細概述,請參閱tools/retro/README.md。
有關詳細信息,請參閱範例/mamba。
我們提供了幾個命令列參數(在下面列出的腳本中詳細介紹)來處理各種零樣本和微調的下游任務。但是,您也可以根據需要從其他語料庫上的預訓練檢查點微調您的模型。為此,只需添加--finetune標誌並調整原始訓練腳本中的輸入檔案和訓練參數即可。迭代計數將重設為零,優化器和內部狀態將重新初始化。如果微調因任何原因中斷,請務必在繼續之前刪除--finetune標誌,否則訓練將從頭開始。
由於評估所需的記憶體比訓練少得多,因此合併並行訓練的模型以便在下游任務中在更少的 GPU 上使用可能會更有利。以下腳本完成此任務。此範例讀取具有 4 路張量和 4 路管道模型並行性的 GPT 模型,並寫出具有 2 路張量和 2 路管道模型並行性的模型。
python 工具/檢查點/convert.py
--模型類型 GPT
--load-dir 檢查點/gpt3_tp4_pp4
--save-dir 檢查點/gpt3_tp2_pp2
--目標張量並行大小 2
--目標管道並行大小 2
下面描述了 GPT 和 BERT 模型的幾個下游任務。它們可以在分散式和模型並行模式下運行,並在訓練腳本中使用相同的變更。
我們在tools/run_text_generation_server.py中包含了一個簡單的 REST 伺服器,用於產生文字。您執行它就像開始預訓練作業一樣,指定適當的預訓練檢查點。還有一些可選參數: temperature 、 top-k和top-p 。有關詳細信息,請參閱--help或來源文件。有關如何運行伺服器的範例,請參閱examples/inference/run_text_ Generation_server_345M.sh。
伺服器執行後,您可以使用tools/text_generation_cli.py來查詢它,它需要一個參數,也就是伺服器正在執行的主機。
工具/text_ Generation_cli.py 本機:5000
您也可以使用 CURL 或任何其他工具直接查詢伺服器:
捲曲 'http://localhost:5000/api' -X 'PUT' -H '內容類型:application/json; charset=UTF-8' -d '{"prompts":["Hello world"], "tokens_to_generate":1}'
如需更多 API 選項,請參閱 megatron/inference/text_ Generation_server.py。
我們在examples/academic_paper_scripts/detxoify_lm/中包含一個範例,透過利用語言模型的生成能力來消除語言模型的毒害。
請參閱 example/academic_paper_scripts/detxoify_lm/README.md,以了解如何使用自行產生的語料庫執行領域自適應訓練和解毒 LM 的逐步教學。
我們提供了針對 WikiText 困惑度評估和 LAMBADA 完型填空準確度進行 GPT 評估的範例腳本。
為了與先前的作品進行比較,我們評估了單字級 WikiText-103 測試資料集的困惑度,並根據使用我們的子詞標記生成器時標記的變化適當地計算困惑度。
我們使用以下命令在 345M 參數模型上執行 WikiText-103 評估。
任務=“WIKITEXT103”
VALID_DATA=<維基文字路徑>.txt
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=檢查點/gpt2_345m
COMMON_TASK_ARGS="--num-layers 24
--隱藏大小 1024
--num-attention-heads 16
--seq-長度 1024
--最大位置嵌入 1024
--fp16
--vocab-檔案 $VOCAB_FILE"
python 任務/main.py
--任務 $TASK
$COMMON_TASK_ARGS
--有效資料 $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--合併檔案 $MERGE_FILE
--載入$CHECKPOINT_PATH
--微批量大小 8
--日誌間隔 10
--無負載最佳化
--無負載-rng
為了計算 LAMBADA 完形填空準確性(在給定前面的標記的情況下預測最後一個標記的準確性),我們利用 LAMBADA 資料集的去標記化、處理版本。
我們使用以下命令在 345M 參數模型上執行 LAMBADA 評估。請注意,應使用--strict-lambada標誌來要求整個單字匹配。確保lambada是檔案路徑的一部分。
任務=“蘭巴達”
VALID_DATA=<蘭巴達路徑>.json
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=檢查點/gpt2_345m
COMMON_TASK_ARGS=<與上面維基文本困惑度評估中的相同>
python 任務/main.py
--任務 $TASK
$COMMON_TASK_ARGS
--有效資料 $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--嚴格-蘭巴達
--合併檔案 $MERGE_FILE
--載入$CHECKPOINT_PATH
--微批量大小 8
--日誌間隔 10
--無負載最佳化
--無負載-rng
在來源檔案main.py中描述了更多命令列參數
以下腳本微調 BERT 模型以在 RACE 資料集上進行評估。 TRAIN_DATA和VALID_DATA目錄包含 RACE 資料集作為單獨的.txt檔案。請注意,對於 RACE,批量大小是要評估的 RACE 查詢的數量。由於每個 RACE 查詢有四個樣本,因此透過模型傳遞的有效批次大小將是命令列上指定的批次大小的四倍。
TRAIN_DATA =“數據/比賽/火車/中間”
VALID_DATA =“資料/種族/開發/中間
數據/種族/開發/高”
VOCAB_FILE=bert-vocab.txt
PRETRAINED_CHECKPOINT=檢查點/bert_345m
CHECKPOINT_PATH=檢查點/bert_345m_race
COMMON_TASK_ARGS="--num-layers 24
--隱藏大小 1024
--num-attention-heads 16
--seq-長度 512
--最大位置嵌入 512
--fp16
--vocab-檔案 $VOCAB_FILE"
COMMON_TASK_ARGS_EXT="--train-data $TRAIN_DATA
--有效資料 $VALID_DATA
--pretrained-checkpoint $PRETRAINED_CHECKPOINT
--保存間隔 10000
--保存$CHECKPOINT_PATH
--日誌間隔 100
--評估間隔 1000
--評估迭代 10
--重量衰減 1.0e-1"
python 任務/main.py
--任務競賽
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--tokenizer-type BertWordPieceLowerCase
--紀元 3
--微批量大小 4
--lr 1.0e-5
--lr-預熱分數 0.06
以下腳本對 BERT 模型進行微調,以使用 MultiNLI 句子對語料庫進行評估。由於匹配任務非常相似,因此可以快速調整腳本以使用 Quora 問題對 (QQP) 資料集。
TRAIN_DATA =“資料/glue_data/MNLI/train.tsv”
VALID_DATA =“資料/glue_data/MNLI/dev_matched.tsv
資料/glue_data/MNLI/dev_mismatched.tsv”
PRETRAINED_CHECKPOINT=檢查點/bert_345m
VOCAB_FILE=bert-vocab.txt
CHECKPOINT_PATH=檢查點/bert_345m_mnli
COMMON_TASK_ARGS=<與上面RACE評估中的相同>
COMMON_TASK_ARGS_EXT=<與上面RACE評估中的相同>
python 任務/main.py
--任務 MNLI
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--tokenizer-type BertWordPieceLowerCase
--紀元 5
--微批量大小 8
--lr 5.0e-5
--lr-預熱分數 0.065
Llama-2 系列模型是一組開源的預訓練和微調(用於聊天)模型,在廣泛的基準測試中取得了出色的結果。在發佈時,Llama-2 模型取得了開源模型中最好的結果之一,並且與閉源 GPT-3.5 模型具有競爭力(請參閱 https://arxiv.org/pdf/2307.09288.pdf)。
Llama-2 檢查點可以載入到威震天中進行推理和微調。請參閱此處的文件。
Megatron-Core (MCore) GPTModel系列透過 TensorRT-LLM 支援高階量化演算法和高效能推理。
有關llama2和nemotron3範例,請參閱威震天模型最佳化和部署。
我們不託管任何用於 GPT 或 BERT 訓練的資料集,但是,我們詳細說明了它們的集合,以便可以重現我們的結果。
我們建議遵循 Google 研究指定的維基百科資料提取過程:“建議的預處理是下載最新的轉儲,使用 WikiExtractor.py 提取文本,然後應用任何必要的清理將其轉換為純文本。”
我們建議在使用 WikiExtractor 時使用--json參數,它將把Wikipedia 資料轉儲為鬆散的json 格式(每行一個json 物件),使其在檔案系統上更易於管理,並且也易於我們的程式碼庫使用。我們建議使用 nltk 標點符號標準化進一步預處理此 json 資料集。對於 BERT 訓練,請如上所述使用--split-sentences標誌到preprocess_data.py以在產生的索引中包含句子中斷。如果您想使用維基百科資料進行 GPT 訓練,您仍然應該使用 nltk/spacy/ftfy 清理它,但不要使用--split-sentences標誌。
我們利用 jcpeterson 和 eukaryote31 的公開可用的 OpenWebText 函式庫來下載 URL。然後,我們根據 openwebtext 目錄中描述的過程來過濾、清理和刪除所有下載的內容。截至 2018 年 10 月的內容對應的 Reddit URL,我們得到了約 37GB 的內容。
威震天訓練可以按位重現;若要啟用此模式,請使用--deterministic-mode 。這意味著相同的訓練配置在相同的硬體和軟體環境中運行兩次應該會產生相同的模型檢查點、損失和準確性指標值(迭代時間指標可能會有所不同)。
目前有三種已知的威震天優化,這些優化破壞了可重複性,同時仍產生幾乎相同的訓練運行:
NCCL_ALGO指定)非常重要。我們測試了以下內容: ^NVLS 、 Tree 、 Ring 、 CollnetDirect 、 CollnetChain 。該程式碼允許使用^NVLS ,這允許 NCCL 選擇非 NVLS 演算法;它的選擇似乎是穩定的。--use-flash-attn 。NVTE_ALLOW_NONDETERMINISTIC_ALGO=0 。此外,確定性僅在 23.12 及更高版本的 NGC PyTorch 容器中進行了驗證。如果您在其他情況下觀察到威震天訓練中的不確定性,請提出問題。
以下是我們直接使用威震天的一些項目:


