tabled
1.0.0
Tabled 是一個用於偵測和提取表的小型函式庫。 它使用 surya 來尋找 PDF 中的所有表格,識別行/列,並將儲存格格式設定為 markdown、csv 或 html。
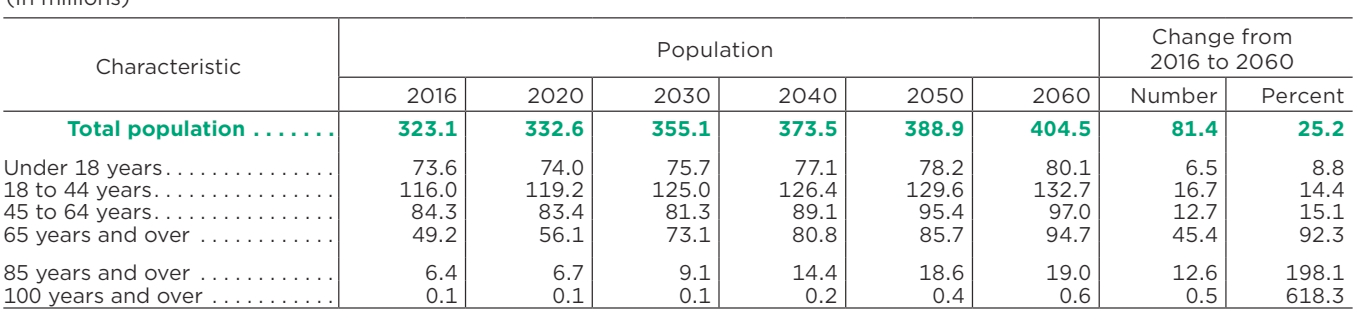
| 特徵 | 人口 | 2016年至2060年的變化 | ||||||
|---|---|---|---|---|---|---|---|---|
| 2016年 | 2020年 | 2030年 | 2040年 | 2050年 | 2060 | 數位 | 百分比 | |
| 總人口 | 323.1 | 332.6 | 355.1 | 373.5 | 388.9 | 404.5 | 81.4 | 25.2 |
| 18歲以下 | 73.6 | 74.0 | 75.7 | 77.1 | 78.2 | 80.1 | 6.5 | 8.8 |
| 18至44歲 | 116.0 | 119.2 | 125.0 | 126.4 | 129.6 | 132.7 | 16.7 | 14.4 |
| 45至64歲 | 84.3 | 83.4 | 81.3 | 89.1 | 95.4 | 97.0 | 12.7 | 15.1 |
| 65歲以上 | 49.2 | 56.1 | 73.1 | 80.8 | 85.7 | 94.7 | 45.4 | 92.3 |
| 85歲以上 | 6.4 | 6.7 | 9.1 | 14.4 | 18.6 | 19.0 | 12.6 | 198.1 |
| 100歲以上 | 0.1 | 0.1 | 0.1 | 0.2 | 0.4 | 0.6 | 0.5 | 618.3 |
Discord 是我們討論未來發展的地方。
這裡有一個用於表的託管 API:
適用於 PDF、圖像、Word 文件和 Powerpoint
一致的速度,無延遲峰值
高可靠性和正常運作時間
我希望盡可能廣泛地使用 Tablet,同時仍為我的開發/培訓成本提供資金。研究和個人使用總是可以的,但商業用途有一些限制。
模型的權重已獲得cc-by-nc-sa-4.0 ,但對於最近12 個月內總收入低於500 萬美元且終身風險投資/天使投資低於500 萬美元的任何組織,我將放棄該權重提出。您也不得與 Datalab API 競爭。 如果您想刪除 GPL 授權要求(雙重授權)和/或在收入限制之上使用商業權重,請查看此處的選項。
您需要 python 3.10+ 和 PyTorch。如果您不使用 Mac 或 GPU 機器,您可能需要先安裝 CPU 版本的 torch。 請參閱此處以了解更多詳細資訊。
安裝:
pip 安裝 tabled-pdf
安裝後:
檢查tabled/settings.py中的設定。 您可以使用環境變數覆蓋任何設定。
系統將自動偵測您的手電筒設備,但您可以覆蓋此設定。 例如, TORCH_DEVICE=cuda 。
模型權重將在您第一次執行時自動下載。
表格 DATA_PATH
DATA_PATH可以是圖像、pdf 或圖像/pdf 資料夾
--format指定每個表的輸出格式( markdown 、 html或csv )
--save_json將額外的行和列資訊保存在 json 檔案中
--save_debug_images儲存顯示偵測到的行和列的影像
--skip_detection表示你傳入的影像都是裁切後的表格,不需要任何表格偵測。
--detect_cell_boxes預設情況下,tabled 將嘗試從 pdf 提取儲存格資訊。 如果您希望透過偵測模型來偵測單元格,請指定此項目(通常只有嵌入文字錯誤的 pdf 才需要此設定)。
--save_images指定應儲存偵測到的行/列和儲存格的影像。
運行腳本後,輸出目錄將包含與輸入檔案名稱具有相同基本名稱的資料夾。 這些資料夾內將包含來源文件中每個表的 markdown 檔案。 也可以選擇提供表格的圖像。
輸出目錄的根目錄中還會有一個results.json檔案。該檔案將包含一個 json 字典,其中鍵是不含副檔名的輸入檔名。 每個值都是一個字典列表,文檔中的每個表都有一個。 每個表格字典包含:
cells - 每個表格儲存格偵測到的文字和邊界框。
bbox - 表 bbox 內單元格的 bbox
text - 單元格的文本
row_ids - 單元格所屬行的 id
col_ids - 單元格所屬列的 ID
order - 該儲存格在其指定的行/列儲存格中的順序。 (按行排序,然後按列排序,然後按順序排序)
rows - 偵測到的行的bboxes
bbox - (x1, x2, y1, y2) 格式的行的 bbox
row_id - 行的唯一 ID
cols - 偵測到的列的 bboxes
bbox - (x1, x2, y1, y2) 格式的列的 bbox
col_id - 列的唯一 ID
image_bbox - (x1, y1, x2, y2) 格式的圖片的 bbox。 (x1, y1) 是左上角,(x2, y2) 是右下角。 表bbox與此相關。
bbox - 圖片 bbox 內表格的邊界框。
pnum - 文檔中的頁碼
tnum - 頁面上的資料表索引
我提供了一個 Streamlit 應用程序,可讓您以互動方式嘗試在圖像或 PDF 文件上放置表格。 運行它:
pip 安裝 Streamlit 表格圖形使用者介面
從 tabled.extract 匯入 extract_tablesfrom tabled.fileinput 匯入 load_pdfs_imagesfrom tabled.inference.models 匯入 load_detection_models、load_recognition_modelsdet_models、rec_models = load_detection_elsa)、load_modelsdet_sefs、rec_models = load_detection_els0),_models images(IN_PATH)page_results = extract_tables(映像,highres_images,文字行、det_models、rec_models)
| 平均分數 | 每桌時間 | 總桌數 |
|---|---|---|
| 0.847 | 0.029 | 第688章 |
為表格取得良好的地面實況資料很困難,因為您要麼受限於可以啟發式解析和渲染的簡單佈局,要麼需要使用會出錯的 LLM。 我選擇使用 GPT-4 表預測作為偽真實值。
與 GPT-4 相比,Tabled 的對齊得分為.847 ,這表示表格行/單元格中的文字之間的對齊情況。 一些錯位是由於 GPT-4 錯誤或 GPT-4 認為的表格邊界中的小不一致造成的。 一般來說,提取品質相當高。
在使用 10GB VRAM 且批次大小為64 A10G 上運行,每個表需要.029秒。
使用以下命令執行基準測試:
python 基準/benchmark.py out.json
感謝 Peter Jansen 提供的基準測試資料集以及有關表解析的討論。
Huggingface 用於推理程式碼和模型託管
用於訓練/推理的 PyTorch


