作者:鄭步前(buqiianz)、黃永康(yongkan1)
海報
我們在 Swift 和 Metal 中實作了 Corgy,一個深度學習框架。 Corgy 可以嵌入到 macOS 和 iOS 應用程式中,並用於建立經過訓練的神經網路並輕鬆對其進行評估。我們在具有不同 GPU 的不同裝置上實現了超過 60 倍的加速。

Metal 2 框架是 Apple 提供的接口,可提供對 iPhone/iPad 和 Mac 上圖形處理單元 (GPU) 近乎直接的存取。除了圖形之外,Metal 2 還包含一系列函式庫,為能夠在各種 Apple 裝置中運行的必要線性代數運算和訊號處理函數提供出色的平行支援。這些函式庫使我們能夠基於其他框架提供的訓練模型在 iOS 裝置上建立良好實現的 GPU 加速的深度學習模型。 1
一般來說,經過訓練的神經網路的推理階段是計算密集的,特別是對於那些具有相當大的層數或應用於需要處理高解析度影像的場景的模型。值得注意的是,存在大量的矩陣計算(例如捲積層) ,適合應用並行操作來最佳化效能。
我們面臨的第一個挑戰是設計一個良好的應用程式介面抽象,該介面具有表現力、易於使用、學習曲線低、易於用戶使用。
在整個開發過程中,我們盡最大努力使公共 API 盡可能簡單,同時利用 Swift 提供的函數式程式設計機制來創建所需的每個元件所需的所有必要屬性。我們也故意隱藏了 Metal 提供的不必要的硬體抽象,以平滑學習曲線。
儘管各種網路的訓練模型很容易在互聯網上獲得,但由於使用各種工具的不同實現而導致它們之間的異質性,導致了創建通用模型導入器的工作。
有些計算的概念很容易理解,但當您想透過抽象來創建有效的實作時,需要仔細思考。卷積就是一個代表性的例子。
卷積運算的內在屬性不具有良好的局部性,普通的實作很難理解且對於複雜的 for 迴圈無效。此外,我們需要考慮 Metal 2 提供的抽象,並創建一種方便的方法來在主機和裝置之間共享必要的資訊和資料結構,同時仔細考慮資料表示和記憶體佈局。
在開發階段,我們非常認真地考慮我們的程式碼能夠在 macOS 和 iOS 上正常運行,並且在兩個平台上的效能都不會受到影響。我們盡力維護能夠在兩個平台上編譯和執行的程式碼庫。我們謹慎地最大化不同目標之間共享的程式碼並盡可能地重複使用程式碼。
由於神經網路層的完全實現的組件應該提供合理數量的參數支持,使組件足夠可用,因此組件的複雜性實際上是相當令人印象深刻的。例如,卷積層應支援包含填充、擴張步幅等的參數,並且在進行並行化以實現合理性能時應謹慎考慮所有這些參數。我們建立了一些簡單的網路來進行回歸測試。測試案例是在其他框架(主要是 PyTorch 和 Keras)中建立的,以確保所有實作都能正常運作。
Swift 於 2010 年 7 月首次開發,並於 2014 年發布並開源。造成這種情況是有原因的,Apple的主導地位和Swift的快速迭代特性可能是造成這種現象的原因。一些對我們至關重要的程式庫要么不夠強大,功能不夠滿足我們的需求,要么發明它們的個人開發人員維護得不好。我們花了相當多的時間來實現一個功能良好的張量類Variable來滿足我們的需求。
此外,檔案和字串處理功能的能力非常有限,這也是阻礙通用模型解析器開發的另一個原因。
另外,開發和調試工具基本上僅限於Xcode,雖然還有其他對我們來說更通用的選擇,但Xcode仍然是我們開發事實上的標準工具。
對於行動裝置的效能調優,蘋果沒有為其 SoC 提供詳細的硬體規格,媒體廣泛使用行銷名稱,很難推斷特定硬體功能的確切影響以及微調實現的效能。
我們使用 Swift 程式語言,具體來說,Swift 4.2,這是迄今為止最新的; Metal 2框架和Metal Performance Shader提供的一些函式庫函數(基本線性代數函數)。儘管Apple在2017年春季推出了CoreML SDK,其中包含了對卷積神經網路的一些支持,但我們並沒有在Corgy中使用它們來獲得開發網絡層並行實現的寶貴經驗,並提供簡潔直觀的API,具有良好的可用性和平滑的學習曲線讓使用者輕鬆地從其他框架遷移模型。
我們的目標機器是所有運行 macOS 和 iOS 的設備,例如 iMac、MacBook、iPhone 和 iPad。具體來說,支援MPS線性代數庫的平台的設備(即iOS 10.0和macOS 10.13之後),這意味著iPhone 5之後推出的iPhone,iPad(第四代)和iPod Touch(第六代)之後推出的iPad均支援 iOS 平台。 Mac產品線的覆蓋範圍更加廣泛,包括2009年底或更新版本之後生產的iMac、2010年中期之後推出的所有MacBook系列以及iMac Pro。
Metal 2 的平行抽象與CUDA 非常相似:當將電腦傳遞給GPU 時,程式設計師將首先編寫將由每個執行緒執行的核心函數,然後指定網格中的執行緒組(也稱為CUDA 中的區塊)的數量,以及每個線程組中的線程數,Metal 將在該網格上執行內核,該內核以名為 Metal 著色語言的 C++14 方言實現。每個線程組內部都有一個更小的單元,稱為SIMD組,意思是一堆共享相同SIMD指令的線程。但在我們的實現下,不需要考慮這個。
Metal 提供了一個名為 MTLCommandBuffer 的 API,它儲存由 GPU 提交和執行的編碼命令。每次我們想要啟動一個由 GPU 執行的任務時,預先編譯的核心函數都會被編碼為 GPU 指令,嵌入到 Metal 著色管道中並傳送到 MTLCommandBuffer。用於儲存需要傳遞給設備的計算參數的Metal buffer也在這個階段設定。然後,透過指定數量的線程組和每組線程,命令緩衝區處理的命令將被完全編碼,並全部設定為提交到裝置。 GPU會對任務進行調度,執行完成後通知CPU執行緒提交工作。
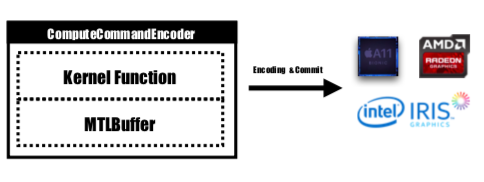
內核函數將由MTLComputeCommandEncoder進行編碼,並將為所有支援的平台建立任務。
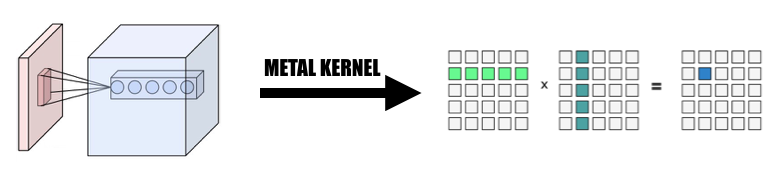
在我們的實作中,我們廣泛採用了一種直觀的方式將元素映射到GPU 線程:將當前層輸出張量中的每個元素映射到一個GPU 線程:每個線程計算並更新輸出的一個元素,輸入將是唯讀,所以我們不需要擔心執行緒之間的同步。在此映射下,具有連續 id 的執行緒可能會從不同的記憶體位置讀取輸入數據,但始終會寫入連續的記憶體位置。因此,當SIMD組寫入記憶體時,不會出現分散操作。
我們設計了一個張量類Variable作為所有實現的基礎,我們利用並將線性代數運算封裝到Variable類中,而不是編寫額外的內核來深入研究不是我們主要關注的操作,以降低實現的複雜性並節省我們的時間來專注於加速網路層。
1.將卷積改為巨矩陣乘法
我們以並行方式從輸入中收集數據,形成輸入變數和權重的巨大矩陣。我們快取每個卷積層的權重以避免重新計算。卷積層的填充將在計算過程中的平行化轉換過程中生成,然後我們對巨型矩陣呼叫 MPSMatrixMultiply,並將巨型矩陣中的資料轉換回我們創建的普通張量類別。該方法在課堂幻燈片中進行了描述。
2.Variable類別的設計與實現
變數類別是我們實作張量表示的基礎。我們封裝了變數的 MPSMatrixMultiplication(將 Unicode 乘法符號 (×) 定義為中綴運算子以優雅地表示它:-))。
這個變數的底層資料結構是一個指向資料類型的UnsafemutableBufferPointer ,為了簡單起見,我們選擇了32位元Float。 Variable類別維護了兩個資料大小, count保存了實際儲存的元素個數, actualCount是所有元素的大小四捨五入到使用getpagesize()獲得的平台頁面大小。
我們維護這兩個值以確保makeBuffer(bytesNoCopy:)直接在指定的 VM 區域上建立緩衝區,並避免冗餘重新分配,從而減少開銷。如果傳遞給 Metal 的記憶體不是頁對齊的,那麼 Metal 將無法使用該記憶體作為輸入或輸出緩衝區。我們必須使用makeBuffer(bytes:)方法,該方法將建立一個新的緩衝區並從輸入記憶體位置複製資料。因此,我們總是需要分配比需要更多的內存,以確保Variable中的所有內存都是頁對齊的。因此,我們需要兩個值來追蹤這塊記憶體到底有多大以及我們應該使用多大。
3、單一線程處理的元素數量
我們嘗試將一個執行緒對應到多個元素,從每個執行緒 2 到 16 個元素,效能幾乎相同,但為我們的專案增加了很多複雜性,因此我們放棄了這種方法。
以下提到的所有 CPU 版本都是未經 SIMD 最佳化的簡單單執行緒 CPU 程式碼。應用了-Ofast等級的編譯器最佳化。
我們的實施效果不錯,但還不夠好。
我們使用 iPhone 6s 和 15 吋 MacBook Pro 作為基準平台。硬體具體說明如下:
MacBook Pro(視網膜 15 英寸,2015 年中)
iPhone 6S
與沒有並行性的簡單 CPU 版本實作相比,我們的 GPU 版本快了 60 倍以上。
由於 MNIST 模型太小,其結果可能無法準確反映加速比。而且我們沒有一個實現良好的單線程版本,我們無法給出準確的加速數字。由於 CPU 版本太慢,Tiny YOLO 上的加速比大得令人難以置信。
實驗網路屬性:
國家標準技術研究所:
約洛:
測量結果:
| iPhone 6s | MNIST | 小YOLO |
|---|---|---|
| 中央處理器 | 1500毫秒 | 753s |
| 圖形處理器 | 0.025秒 | 0.5秒 |
| 加速 | 〜60倍 | 〜1500x |
| Macbook 專業版 | MNIST | 小YOLO |
|---|---|---|
| 中央處理器 | 650毫秒 | 729s |
| 圖形處理器 | 10毫秒 | 0.028秒 |
| 加速 | 〜65x | 〜26000x |
根據上述基準,我們可以看到,隨著問題規模的增加,
為什麼我們說我們的加速不夠好?因為與蘋果官方實現的MPSCNNConvolution相比,我們的速度只有三分之一左右,這意味著還有很大的優化空間。此比較是基於 iPhone 上使用官方MPSCNNConvolution的 YOLO 開源實現,它每秒可以識別約 5 張圖像,而我們的實現每秒只能識別約 2 張圖像。
而且由於時間有限,我們無法創建更好的基準版本和CPU並行版本來進行基準測試,這使得加速數字太大。
此外,值得報告不同問題大小的效能增益。我們可以看到,MNIST 只有 10 萬個權重,而 Tiny YOLO 有 1700 萬個。 Tiny YOLO 比 MNIST 複雜得多,但 GPU 版本的運行時間並沒有那麼多。這又是因為阿姆達爾定律。每啟動一個GPU任務,都需要將對應的GPU指令編碼到指令緩衝區。這個過程本質上是串行的。當問題規模較小時,該過程對總運行時間貢獻很大,因此透過並行化 MINST 中的神經網路推理階段可能無法獲得與 Tiny YOLO 相同的速度,後者的運行時間開銷可以忽略不計。
是什麼限制了你的加速?
if和for可能會導致發散,從而導致 SIMD 利用率不佳。更深入的分析:細分不同階段的執行時間。
以Tiny YOLO為例,在Macbook上總運行時間為227ms的範例運行中,卷積層使用了207ms,佔總運行時間的92%。 Pooling 層使用了 14ms(6%),ReLU 使用了 6ms(2%)。根據阿姆達爾定律,如果我們想進一步提高性能,我們肯定應該在卷積層上繼續努力。
總的來說,我們相信我們選擇 Metal 框架在 iOS 和 macOS 裝置上進行神經網路加速是合理的,特別是對於 iOS 裝置。由於它的核心較少,即使使用 SIMD 指令,經過良好調優的 CPU 版本也不太可能獲得與 GPU 版本相似的效能。
兩個團隊成員完成同等的工作。
1 https://developer.apple.com/metal/ ↩
2 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
3 http://pytorch.org ↩
4 https://github.com/BVLC/caffe ↩
5 https://developer.apple.com/documentation/metal/compute_processing/about_threads_and_threadgroups ↩
6 https://developer.apple.com/library/content/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Render-Ctx/Render-Ctx.html ↩


