disclosure backend static
1.0.0
disclosure-backend-static儲存庫是為 Open Disclosure California 提供支援的後端。
它是在 2016 年大選之前倉促創建的,因此是圍繞著「完成任務」的理念設計的。那時,我們已經設計了一個API並建造了(大部分)前端;建立此儲存庫是為了盡快實施這些內容。
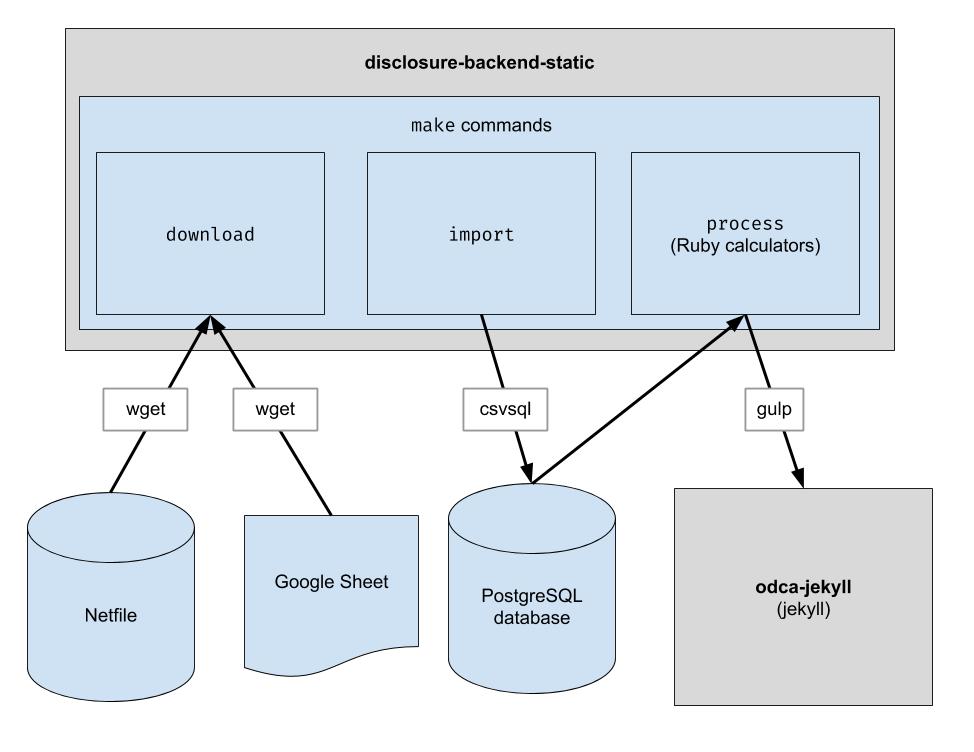
該專案實現了一個基本的 ETL 管道來下載奧克蘭網路文件數據、下載奧克蘭的 CSV 人工管理數據,並將兩者結合起來。輸出是一個 JSON 檔案目錄,它模仿現有的 API 結構,因此不需要更改客戶端程式碼。
.ruby-version中的版本) 注意:您不需要執行這些命令來在前端進行開發。您需要做的就是克隆與前端儲存庫相鄰的儲存庫。
如果您打算修改後端程式碼,請按照以下步驟設定所有必要的開發依賴項,包括新的 PostgreSQL 資料庫和 Python 3:
brew update && brew upgrade
brew install postgresql@16
brew services start postgresql@16
python3 -m pip而不是pip以確保使用 Python 3: python3 -m pip install ...
pip指向Python 3,你可以直接使用pip : pip install ...
sudo -H python -m pip install -r requirements.txt
gem install pg bundler
bundle install
此儲存庫設定為在 Codespaces 下的容器中運作。換句話說,您可以啟動已設定的環境,而無需執行設定本機環境所需的任何安裝步驟。這可以用作在將程式碼提交到生產管道之前對其進行故障排除的一種方法。以下資訊可能有助於開始使用 Codespaces:
Code按鈕,然後按一下下拉清單中的Codespaces標籤/workspace處的終端提示,如果您之前使用過 VS Code,這看起來會很熟悉make downloadpsql即可連接到伺服器make import指令將填入 Postgres 資料庫git push它最終不會出現在 GitHub 儲存庫中該存儲庫也配置為在 Docker 容器中運行。這與 Codespaces 類似,只不過您可以使用您喜歡的任何 IDE 和本地設定。以下是如何開始將 Docker 與 VSCode 結合使用:
下載原始資料檔。您只需偶爾運行一次即可獲取最新數據。
$ make download
將資料匯入資料庫以便於處理。您只需在下載新資料後執行此命令。
$ make import
運行計算器。所有內容都輸出到“build”資料夾中。
$ make process
(可選)將建置輸出重新索引到 Algolia 中。 (重新索引需要 ALGOLIASEARCH_APPLICATION_ID 和 ALGOLIASEARCH_API_KEY 環境變數)。
$ make reindex
如果您想透過本機 Web 伺服器提供靜態 JSON 檔案:
$ make run
執行make import時,會建立許多 postgres 表用於匯入下載的資料。這些表的模式在dbschema目錄中明確定義,並且將來可能需要更新以適應未來的資料。保存字串資料的列的大小可能不足以容納未來的資料。例如,如果名稱列最多接受 20 個字元的名稱,而將來我們有名稱長度為 21 個字元的數據,則資料匯入將失敗。發生這種情況時,我們將不得不更新dbschema中對應的模式檔案以支援更多字元。只需進行更改並重新運行make import即可驗證其是否成功。
此儲存庫用於產生網站使用的資料檔案。執行make process後,會產生一個包含資料檔案的build目錄。該目錄被簽入儲存庫,稍後在生成網站時簽出。進行程式碼build後,將產生的build目錄與程式碼變更之前產生的建置目錄進行比較並驗證程式碼變更是否符合預期非常重要。
由於對build目錄的所有內容的嚴格比較將始終包括獨立於任何程式碼變更而發生的更改,因此每個開發人員都必須了解這些預期的變更才能執行此檢查。為了消除這種需要,特定檔案bin/create-digests.py會在排除這些預期變更後在build目錄中產生 JSON 資料的摘要。要查找排除這些預期更改的更改,只需在build/digests.json文件中查找更改即可。
目前,這些是獨立於任何程式碼變更而發生的預期變更:
在build目錄中的資料摘要之前,將排除預期的變更。其邏輯可以在函數clean_data中找到,該函數位於檔案bin/create-digests.py中。修改程式碼使得預期的變更不再存在後,可以從clean_data中刪除對該變更的排除。例如,由於環境的差異,每次執行make process時,浮點數的捨入不一致。當程式碼被修復後,只要資料沒有改變,浮點數的捨入就相同,那麼可以刪除clean_data中的round_float呼叫。
已建立一個附加腳本來產生報告,以便比較候選人的總數。腳本是bin/report-candidates.py ,它產生build/candidates.csv和build/candidates.xlsx 。這些報告包括所有候選人的清單以及透過多種方式計算的總數,這些總數應達到相同的數字。
為了確保資料庫架構變更在拉取請求中可見,完整的 postgres 架構也會儲存到build目錄中的schema.sql檔案中。由於build目錄會自動為 PR 中的每個分支重新建置並提交到儲存庫,因此在查看 PR 時,程式碼變更引起的架構的任何變更都會在schema.sql檔案中顯示差異。
關於候選人的每個指標都是獨立計算的。指標可能是「收到的捐款總額」之類的東西,也可能是更複雜的東西,例如「少於 100 美元的捐款百分比」。
新增計算時,最好先從官方表格 460 開始。如果是這樣,您可能會在匯入過程後在資料庫中找到它。我們也匯入了一些其他表格, input表格 496。
每個表單的每個時間表都會匯入到單獨的 postgres 表中。例如,表格 460 的附表 A 被匯入到A-Contributions表中。
現在您已經有了查詢資料的方法,您應該提出一個 SQL 查詢來計算您想要取得的值。一旦您可以將計算表達為 SQL,請將其放入計算器檔案中,如下所示:
calculators/[your_thing]_calculator.rb的新文件 # the name of this class _must_ match the filename of this file, i.e. end
# with "Calculator" if the file ends with "_calculator.rb"
class YourThingCalculator
def initialize ( candidates : [ ] , ballot_measures : [ ] , committees : [ ] )
@candidates = candidates
@candidates_by_filer_id = @candidates . where ( '"FPPC" IS NOT NULL' )
. index_by { | candidate | candidate [ 'FPPC' ] }
end
def fetch
@results = ActiveRecord :: Base . connection . execute ( <<-SQL )
-- your sql query here
SQL
@results . each do | row |
# make sure Filer_ID is returned as a column by your query!
candidate = @candidates_by_filer_id [ row [ 'Filer_ID' ] . to_i ]
# change this!
candidate . save_calculation ( :your_thing , row [ column_with_your_desired_data ] )
end
end
endFiler_ID列。candidate.save_calculation的呼叫。此方法會將其第二個參數序列化為 JSON,因此它可以儲存任何類型的資料。candidate.calculation(:your_thing)來擷取您的計算結果。您需要將其新增至process.rb檔案中的 API 回應。 這就是資料流經後端的方式。財務資料從 Netfile 中提取,並輔以 Google Sheet,將 Filer Id 映射到投票訊息,如候選人姓名、辦公室、投票措施等。前端。
捆綁安裝期間
error: use of undeclared identifier 'LZMA_OK'
嘗試:
brew unlink xz
bundle install
brew link xz
make download期間
wget: command not found
執行brew install wget 。
在make import期間
使用 Apple 晶片的 Macintosh 系統似乎有問題。
ImportError: You don't appear to have the necessary database backend installed for connection string you're trying to use. Available backends include:
PostgreSQL: pip install psycopg2
請嘗試以下操作:
pip uninstall psycopg2-binary
pip install psycopg2-binary --no-cache-dir


